Command Palette
Search for a command to run...
使用极大 Dropout 进行微调
使用极大 Dropout 进行微调
Jianyu Zhang Léon Bottou
在 shakespeare 数据集上用 nanoGPT 微调 GPT
摘要
在当今,假装机器学习实践始终与训练数据和测试数据遵循相同分布的理念相兼容是不可能的。最近,几位作者利用集成技术展示了涉及多个数据分布的场景如何由比通过正则化以获得最佳分布内性能所得到的表示更丰富、且比受常见随机梯度过程隐式稀疏性偏差影响所得到的表示更丰富的表示来更好地服务。本贡献研究了使用极高的 Dropout 率而非集成来获得此类丰富表示的方法。尽管使用如此高的 Dropout 率从头训练深度网络几乎不可能,但在这些条件下对大型预训练模型进行微调不仅是可行的,而且其分布外性能超过了集成和诸如模型汤(model soups)等权重平均方法。这一结果具有实际意义,因为近年来微调场景的重要性显著增加。此外,该结果为丰富表示的本质以及使用相对较小数据集微调大型网络的内在线性性质提供了有趣的见解。
一句话总结
对大型预训练模型应用极高的 Dropout 率进行微调,能够生成更丰富的特征表示,其分布外(o.o.d.)性能优于模型集成以及模型汤(model soups)等权重平均方法,同时为理解大型网络适应小规模数据集时固有的线性适应特性提供了重要见解。
核心贡献
- 本文提出一种微调策略,在表征层应用极高的 Dropout 率(随机遮蔽超过 90% 的单元),从而迫使大型预训练模型在无显式多样性设计的情况下学习更丰富的表示。
- 在分布外场景下的评估表明,该方法超越了传统集成方法以及模型汤等权重平均技术的性能。
- 该分析通过实证确认,在相对较小的数据集上微调大型网络本质上是一个线性过程,从而为丰富表示的构成提供了具体见解。
引言
现代机器学习日益依赖于先在大规模数据集上预训练大型模型,随后针对特定任务进行微调,并在分布偏移条件下进行评估。这种对严格独立同分布(i.i.d.)假设的偏离,使得开发能够在多样化数据分布下实现稳健泛化的表示变得至关重要。先前的方法试图通过集成、对抗采样或权重平均来构建更丰富的特征集,但这些方法会带来高昂的计算成本,且难以克服标准梯度下降中隐含的稀疏性偏差。研究者利用极高的 Dropout 率进行微调,迫使网络保留弱相关及冗余特征。将该方法应用于预训练模型而非从头训练,研究者在分布外性能上超越了集成方法和模型汤,同时展示了一条计算高效的优化路径,凸显了微调大型架构时近乎线性的动态特性。
方法
研究者采用三分布设置来分析迁移学习过程,其中预训练模型作为在大型可控分布 Tp 上训练的基座模型。该基座模型生成特征 Ψ,随后将其整合至新模型 ωd∘Ψ 中,该模型在第二个分布 Td 上进行微调。最终性能在第三个分布 Td 上进行评估,该分布可能在数据分布或特征可用性方面与微调分布不同,从而模拟现实世界中的分布外(o.o.d.)场景。目标是识别能够在此类分布偏移下增强模型鲁棒性的微调策略。
如图下方所示:该框架由带有残差连接的预训练基座模型构成,通过修改后的训练流程在目标任务上进行微调。模型架构利用跳跃连接将内部层特征暴露给最终分类层,从而在微调期间实现所学表示的近乎线性利用。Veit 等人(2016)形式化的这一分解将倒数第二层表示 Φ(x) 表达为各个残差块贡献的加性总和:
其中 fi 表示第 i 个残差块实现的函数。这种加性结构对本文提出的方法至关重要,因为它允许作用于 Φ(x) 的 Dropout 同时阻断所有残差块的贡献。研究者对倒数第二层表示 Φ 应用极高的 Dropout 率(约 90%),对其进行如下修改:
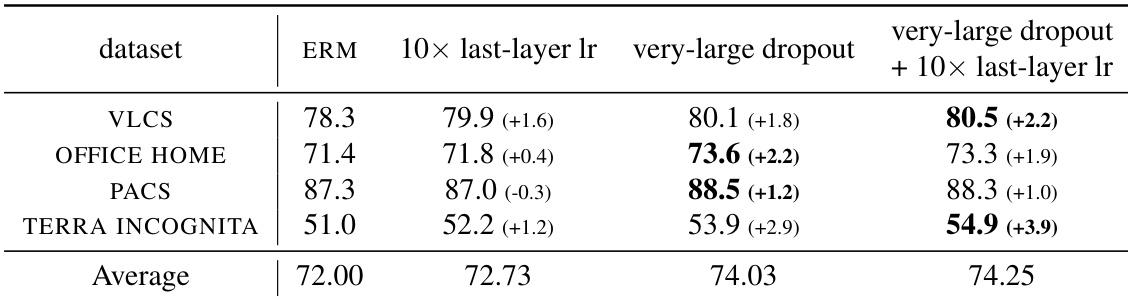
Φdropout(x)=1−λm(λ)⊙Φ(x)其中 m(λ) 是一个伯努利变量向量,取值为零的概率为 λ。该机制迫使模型在微调期间依赖更广泛的特征集,从而缓解在线性模型中观察到的梯度饥饿现象,即优化过程倾向于对单一主导特征过拟合。尽管在线性情况下 L2 正则化与 Dropout 在促进特征多样性方面是等价的,但这种等价性在深度网络中会失效。在此类设置中,在微调阶段(而非预训练阶段)应用极高的 Dropout 率,能够促进更具鲁棒性的表示,以支持 o.o.d. 泛化。
该方法采用 SGD 或 ADAM 等标准随机优化算法实现。值得注意的是,该高 Dropout 率仅应用于微调阶段,而非初始预训练阶段,因为如此高的比率会在初始学习阶段导致性能下降。研究者证明,该简单技术与包括权重平均和集成方法在内的其他微调策略兼容,即使与这些技术结合使用,也能显著提升 o.o.d. 性能。然而,仅靠极高 Dropout 率的方法本身已主导了性能提升,这表明其在改善分布偏移鲁棒性方面发挥着核心作用。
实验
通过在多个数据集、不同的超参数配置以及不同层次的预训练表示丰富度上微调预训练视觉模型,实验验证了高 Dropout 率对分布外泛化的影响。结果表明,在倒数第二层应用极高的 Dropout 率,与集成和权重平均基线相比,始终能产生更优的分布外性能,同时在不同的超参数和 Dropout 率选择下保持稳健性。进一步分析证实,该技术对从头训练无效,但对微调预训练模型极具价值,因为它选择性利用了丰富且预先存在的特征表示,而非试图学习新特征。最终,研究结果确立了极高 Dropout 率作为分布外鲁棒性的主要驱动力,并凸显了分布内与分布外泛化优化策略之间的根本差异。
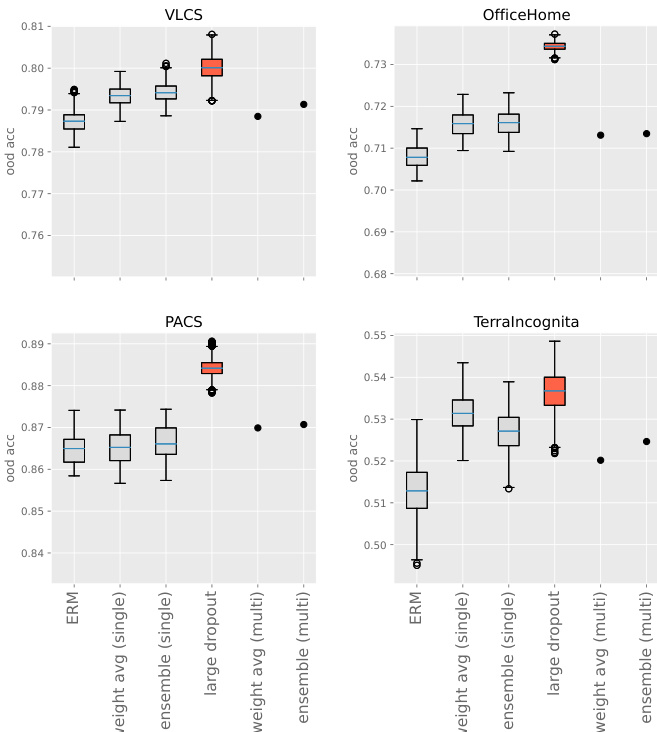
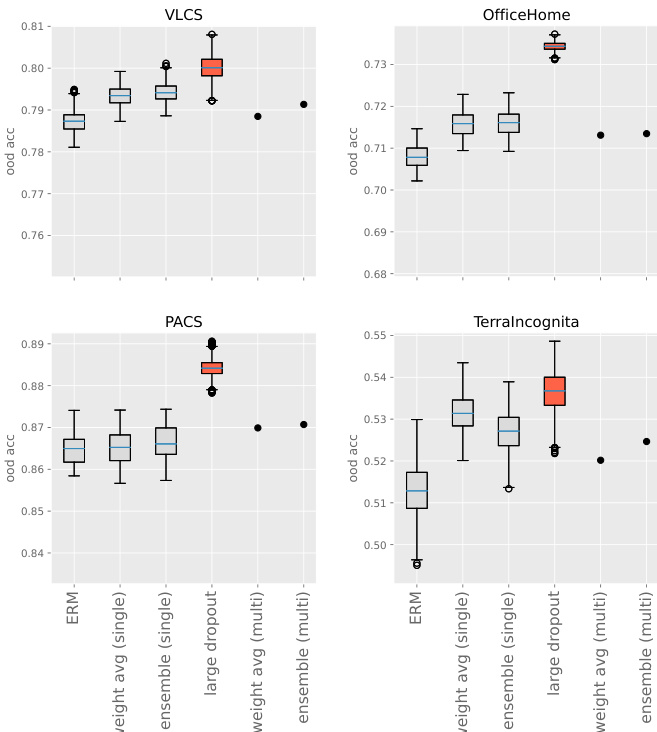
研究者在分布外任务上比较了多种微调方法,重点对比了极高 Dropout 率与集成及权重平均技术的性能。结果表明,极高 Dropout 率始终优于基线方法,且随着预训练模型表示的丰富度增加,其有效性随之提升。该方法对超参数选择具有鲁棒性,即使与其他技术结合也能带来显著改进。极高 Dropout 率实现了优于集成和权重平均方法的分布外性能。该方法虽与其他技术兼容,但在性能提升中起主导作用。预训练模型的表示越丰富,性能提升越明显,且该方法对超参数选择具有鲁棒性。
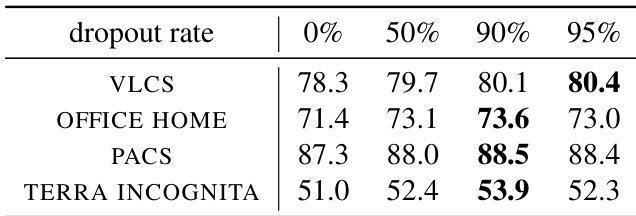
研究者调查了 Dropout 率对分布外性能的影响,发现与标准或较低的 Dropout 率相比,极高 Dropout 率在多个数据集上始终能提升性能。结果表明,更高的 Dropout 率带来更好的 o.o.d. 性能,最佳比率在 90% 或更高,且该方法即使与集成或权重平均等技术结合也保持稳健有效。当应用于具有丰富表示的模型(例如经过大量数据增强预训练的模型)时,该方法尤为有效。在多个数据集上,极高 Dropout 率始终优于标准 Dropout 率。o.o.d. 性能的最佳 Dropout 率在 90% 或更高,且在该范围内性能保持稳定。极高 Dropout 方法与集成和权重平均兼容,为基线微调方法提供了持续的性能提升。
研究者在分布外任务上比较了多种微调方法,重点考察极高 Dropout 率的有效性及其与集成和权重平均技术的结合效果。结果表明,极高 Dropout 率始终能提升基线方法的性能,且在应用于表示更丰富的模型时,其优势更为明显。当与极高 Dropout 结合时,集成和权重平均仅带来边际改善。极高 Dropout 率优于基线方法,相比标准微调提供了显著改进。将极高 Dropout 与集成或权重平均技术结合仅带来微小的性能增益。极高 Dropout 的有效性随预训练模型表示丰富度的增加而提升。
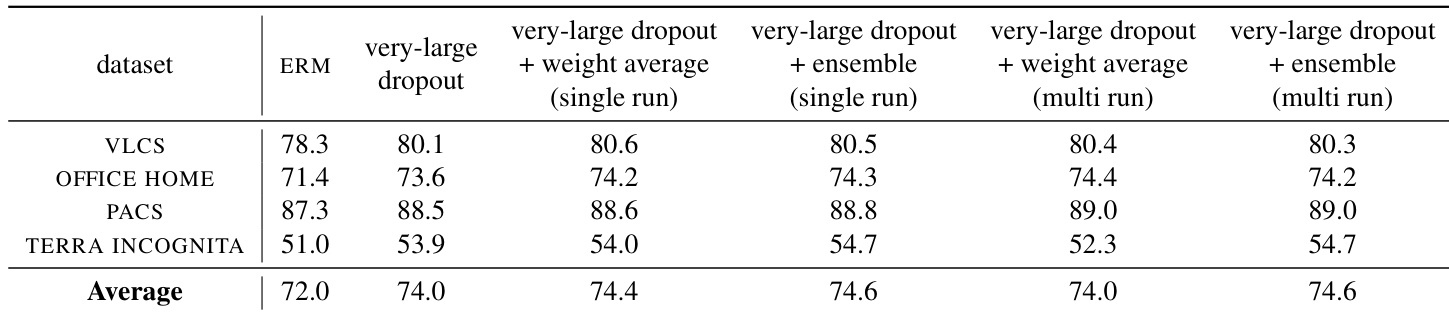
研究者在多个数据集上比较了不同微调方法的分布外性能。结果表明,极高 Dropout 率始终优于其他方法(包括集成和权重平均),且在特定数据集上性能差距尤为明显。该方法对超参数选择具有鲁棒性,并在不同场景下保持强劲性能。与集成和权重平均方法相比,极高 Dropout 率实现了更优的分布外性能。该方法对超参数选择稳健,在不同数据集上表现一致。在极高 Dropout 微调后应用集成和权重平均技术仅带来边际改善。
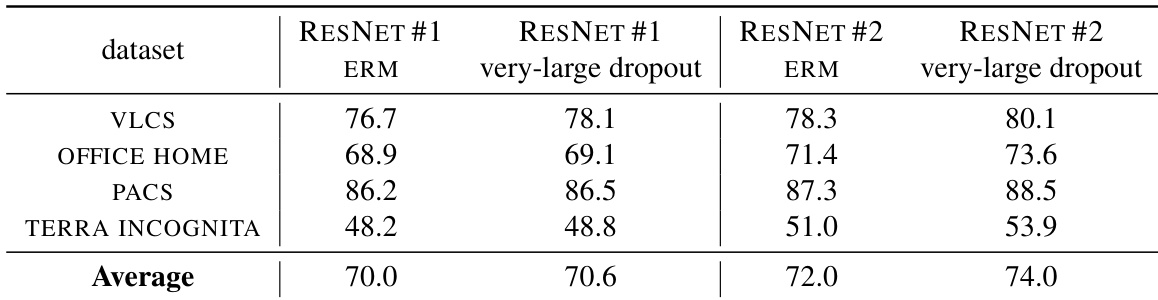
研究者在两款预训练 ResNet 模型上比较了极高 Dropout 率与基线方法的分布外性能。结果表明,极高 Dropout 率始终能改善标准微调的 o.o.d. 性能,且在使用表示更丰富的模型时,该提升更为显著。该方法同样展现出对超参数选择的鲁棒性。在两款预训练模型上,极高 Dropout 率均持续提升了分布外性能。极高 Dropout 带来的性能增益在表示更丰富的模型上更为显著。该方法对超参数选择稳健,其最差结果仍优于基线方法的最佳结果。
实验在多个数据集和预训练模型上评估了分布外任务中的多种微调策略,重点验证了极高 Dropout 率的泛化效能。定性结果表明,该方法在鲁棒性和迁移能力上始终优于标准微调、集成和权重平均。该方法在超参数选择上表现出极高的稳定性,且应用于具有更丰富学习表示的模型时,能带来逐步增强的性能增益。最终,它成为性能提升的主导因素,使得补充性的集成技术基本失去必要性。