Command Palette
Search for a command to run...
CharacterGen:基于多视图姿态规范化的单图像高效3D角色生成
CharacterGen:基于多视图姿态规范化的单图像高效3D角色生成
Hao-Yang Peng Jia-Peng Zhang Meng-Hao Guo Yan-Pei Cao Shi-Min Hu
一键部署 CharacterGen:单图生成高质量 3D 角色
摘要
在数字内容创作领域,从单张图像生成高质量的3D角色具有挑战性,尤其是面对各种身体姿态的复杂性、自遮挡以及姿态歧义等问题。在本文中,我们提出了CharacterGen,这是一个旨在高效生成3D角色的框架。CharacterGen引入了一个简化的生成流程以及一个图像条件化的多视图扩散模型。该模型能有效将输入姿态校准为标准形式(canonical form),同时保留输入图像的关键属性,从而应对多样化姿态带来的挑战。我们方法的另一个核心组件是基于Transformer的可泛化稀疏视图重建模型,它促进了从多视图图像创建详细的3D模型。我们还采用了一种纹理反投影策略来生成高质量的纹理贴图。此外,我们精心构建了一个动漫角色数据集,包含多种姿态和视角的渲染结果,用于训练和评估我们的模型。我们通过定性和定量实验对我们的方法进行了全面评估,结果表明其在生成具有高质量形状和纹理的3D角色方面表现出色,这些角色可直接应用于绑定(rigging)和动画等下游任务。
一句话总结
研究团队提出 CharacterGen,这是一个通过结合用于姿态规范化的图像条件多视图扩散模型、基于 Transformer 的可泛化稀疏视图重建模型以及纹理反投影策略,从单张图像高效生成高质量 3D 角色的框架。在精心策划的动漫角色数据集上进行的定量与定性评估表明,该框架能够生成细节丰富且适用于绑定与动画制作的形状与纹理。
核心贡献
- CharacterGen 引入了一种图像条件多视图扩散模型,该模型能够将多样化的输入姿态校准为规范姿态,同时在单张图像角色生成过程中保留关键视觉属性。
- 该框架将基于 Transformer 的稀疏视图重建模型与纹理反投影策略相结合,能够从多视图图像中合成细节丰富的 3D 几何结构与高保真纹理贴图。
- 提供了一个包含 13,746 个动漫角色的精心策划数据集,涵盖多种姿态与视角,用于训练与评估。定量与定性实验验证了该模型在下游绑定与动画任务中的能力。
引言
数字娱乐与虚拟现实领域的快速扩张使得高效的 3D 资产创建成为刚需,但手动建模仍是显著的生产瓶颈。尽管单图转 3D 生成提供了一条有前景的解决路径,但现有方法在处理风格化角色常见的复杂关节结构、严重自遮挡及多样化姿态时仍面临挑战。先前的方法严重依赖写实人体先验,无法捕捉夸张的比例与宽松衣物,且往往缺乏处理任意输入姿态的灵活性,或存在多脸生成伪影问题。为突破这些限制,研究团队采用名为 CharacterGen 的两阶段流水线,将任意单张输入图像转换为干净的 3D 角色模型。该方法首先将任意姿态规范化为标准 A-pose,并通过扩散模型生成一致的多视图图像,随后将这些视图输入基于 Transformer 的重建网络,以生成细节丰富且可直接用于动画的网格。该方法有效规避了姿态歧义与遮挡问题,同时简化了下游绑定与动画的工作流程。
数据集
- 数据集构成与来源: 研究团队使用 Anime3D 数据集以增强扩散模型对 3D 角色的理解,并缓解 Janus 问题。该数据集源自 VRoid-Hub,初始包含近 14,500 个动漫角色,经筛选后仅保留 13,746 个严格符合人形标准的模型。
- 子集详情与姿态生成: 数据划分为 A-pose 与姿态类别。A-pose 模型具有固定的关节旋转角度,双臂设置为 45°,双大腿沿 Z 轴设置为 6°。姿态模型使用 10 个 Mixamo 骨骼动画片段(包含行走与坐姿)进行动画处理,并随机采样帧,同时嘴部与眼部关节被随机化以生成多样的面部表情。
- 处理与渲染流水线: 所有资产均使用
three-vrm框架转换为图像,以支持 2D 扩散模型的微调。研究团队将角色边界框归一化至 [-0.5, 0.5]^3 的体积范围内,将相机置于距离场景原点 1.5 个单位处,视场角为 40°,并应用环境光与方向光的组合照明。 - 训练用途与视角配置: 模型在包含四个 A-pose 视图与一个姿态视图的图像对上进行训练。标准 A-pose 配置在方位角 0°、90°、180° 和 270° 处渲染四张正交图像,俯仰角为 0°。为提升空间布局理解能力,另外三组 A-pose 采用随机初始方位角。针对可泛化重建的微调,研究团队还生成了四个方位角与俯仰角完全随机化的姿态视图。
方法
研究团队采用两阶段框架,旨在从单张输入图像高效生成 3D 角色,该框架专门用于生成高质量且姿态规范化的模型,适用于下游动画任务。整体流水线首先通过多视图扩散模型生成角色在标准 A-pose 下的一致性正交视图,随后执行由粗到细的重建过程,以构建外观增强的细节 3D 网格。
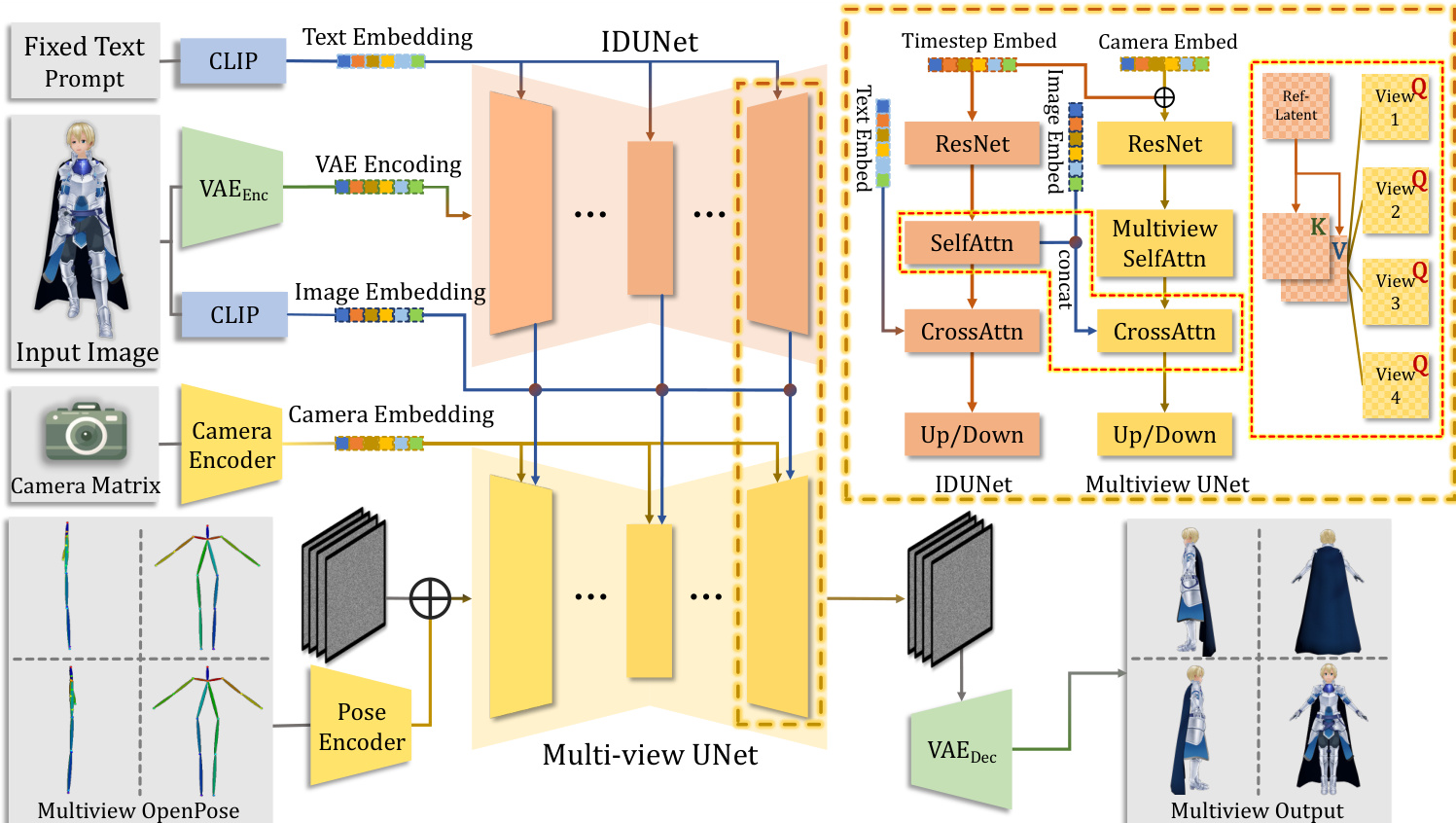
第一阶段聚焦于多视图图像生成与姿态规范化。该过程由扩散模型架构驱动,接收单张输入图像并合成规范姿态下的四视图图像。框架采用 IDUNet 模块将输入图像的像素级外观特征迁移至扩散过程,确保对原始纹理的高保真还原。与依赖全局图像嵌入的先前的方法不同,IDUNet 利用潜在 tokens 与条件图像 tokens 之间的交叉注意力机制实现图块级交互,从而保留细粒度细节。该模块与多视图 UNet 结合,后者对四视图的潜在表示执行联合去噪过程。UNet 引入空间自注意力机制,通过重塑潜在 tokens 来建模跨视图关系,使模型能够捕捉生成视图间的整体一致性。条件特征通过将 IDUNet 输出与 CLIP 编码的图像特征拼接而成,随后通过交叉注意力机制引入。为提升生成质量,模型在最终时间步采用零采样信噪比(SNR)策略进行训练,以优化速度预测。姿态规范化通过将扩散模型与源自 OpenPose 的姿态嵌入联合训练来实现,后者提供结构引导以防止布局错位,并确保生成的角色符合人体解剖学约束。
流水线第二阶段从生成的多视图图像中重建 3D 角色。研究团队采用受 LRM 启发的基于 Transformer 的重建网络,该网络先在通用物体数据集上进行预训练,随后在 Anime3D 数据集上进行微调,以捕捉角色专属先验。重建过程分为两步:首先使用三平面 NeRF 表示法建立粗略几何结构与外观;随后修改解码器以预测符号距离函数(SDFs),从而生成更平滑且精确的表面几何。该阶段通过 MSE、掩码与 LPIPS 损失函数的组合进行监督,以确保形状与外观重建的准确性。生成的网格进一步采用拉普拉斯平滑进行优化,以降低表面噪声。
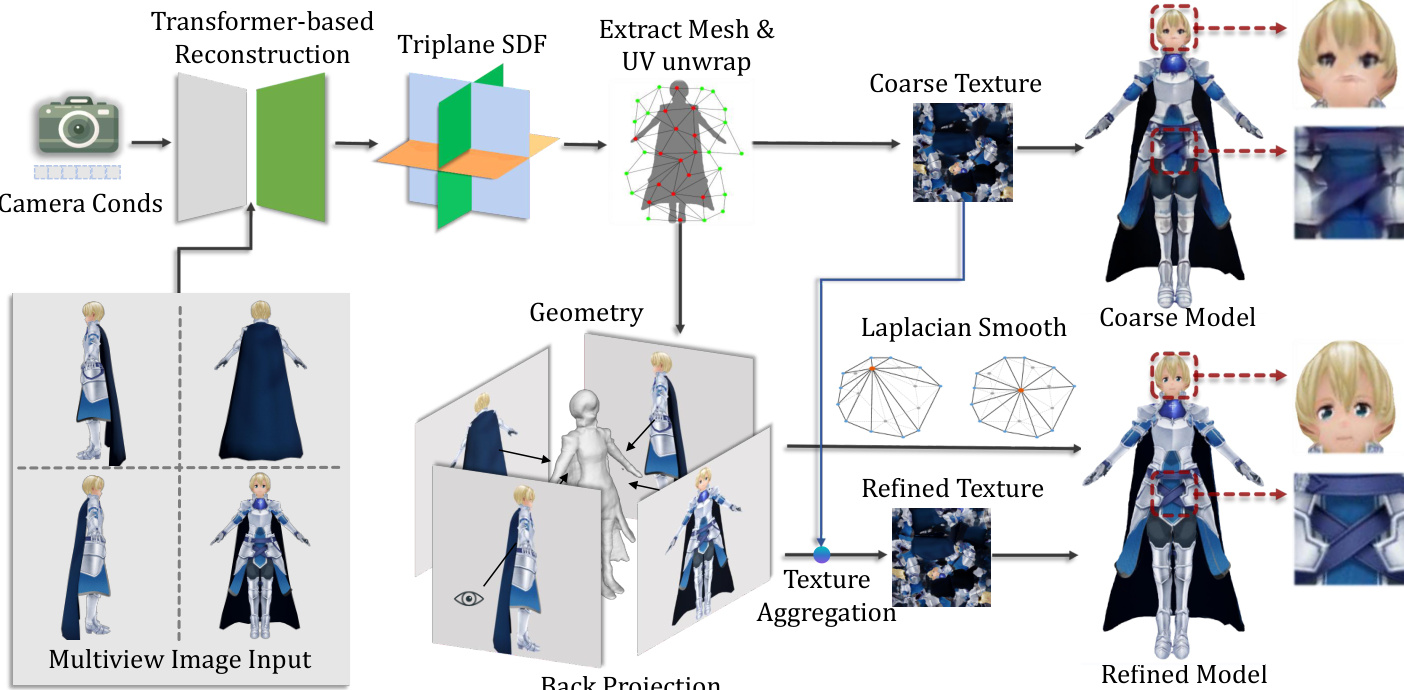
为提升纹理质量,框架采用纹理反投影策略。生成的高分辨率多视图图像被投影至重建网格的粗略 UV 贴图上。为缓解可微渲染过程中因遮挡与纹理像素重叠产生的噪声,系统执行深度测试以剔除被遮挡的纹理像素,并使用基于法线的滤波器丢弃轮廓附近的纹理像素。对于重叠的纹理像素,选取与粗略纹理 RGB 值最接近的像素。最后,应用泊松融合将投影纹理像素与原始纹理聚合,有效减少接缝并生成高质量、精细化的纹理贴图。该完整流程最终输出可直接用于动画的完整 3D 角色模型。
实验
评估设置通过在既定基线上进行基准测试、开展用户偏好研究以及执行组件消融实验,来验证模型在 2D 多视图图像生成与 3D 网格重建任务上的整体生成质量与架构设计选择。定性评估与用户投票确认,该框架能有效校准规范姿态,保持跨视图的空间与外观一致性,并生成避免 Janus 问题等常见伪影的干净网格。消融实验进一步表明,联合训练身份网络与引入姿态嵌入对准确特征提取与布局稳定性至关重要,而下游应用测试验证了生成的 A-pose 角色能够无缝支持自动绑定与动画工作流。
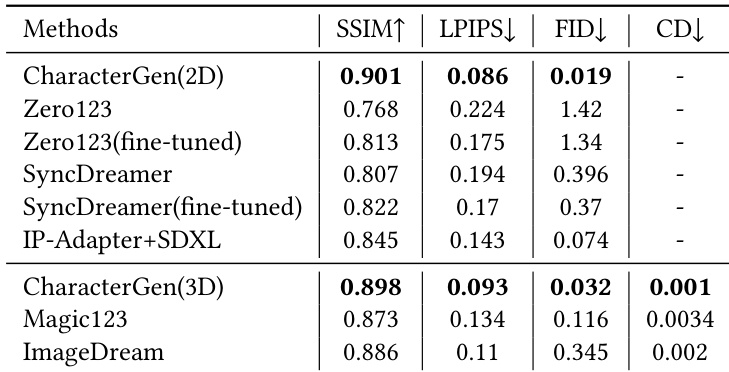
研究团队在 2D 多视图图像生成与 3D 角色生成任务上,将 CharacterGen 方法与多种基线方法进行对比评估。结果表明,与其他方法相比,CharacterGen 在 2D 风格与多视图一致性,以及 3D 几何与纹理质量方面均取得显著提升。评估凸显了所提框架在生成一致性多视图图像与高质量 3D 模型方面的有效性。CharacterGen 在 2D 多视图风格一致性与 3D 角色几何及纹理质量上优于其他方法。与 Zero123 和 ImageDream 等基线相比,CharacterGen 在 2D 与 3D 生成任务中均表现出更优越的性能。该方法在生成多视图图像与重建 3D 角色方面展现出高一致性与强鲁棒性,从而带来更佳的下游应用效果。

研究团队通过定量指标与用户研究评估 CharacterGen 方法,并将其与多种基线模型在 2D 多视图图像生成与 3D 角色生成任务上进行对比。结果表明,CharacterGen 在图像与 3D 模型生成方面实现了更高的质量与一致性,在风格与外观相似度上表现优异。定量指标显示,CharacterGen 在 2D 与 3D 生成任务中均优于基线方法。与其他方法相比,CharacterGen 展现出更卓越的风格一致性与外观建模能力。用户研究确认,在 2D 与 3D 生成任务中,CharacterGen 均优于替代方案。

研究团队在 2D 多视图图像生成与 3D 角色生成任务上评估 CharacterGen 方法,并将其与多种基线模型进行对比。结果表明,CharacterGen 在生成一致性多视图图像与高质量 3D 角色网格方面表现优异,在几何与纹理保真度上较其他方法有显著提升。用户研究与定量指标进一步印证了其有效性与鲁棒性。CharacterGen 在生成一致性多视图图像与高质量 3D 角色网格方面优于基线方法。该方法展现出卓越的几何与纹理保真度,尤其在处理复杂角色姿态时表现突出。用户研究与定量指标证实了 CharacterGen 在 2D 与 3D 生成任务中的鲁棒性与有效性。
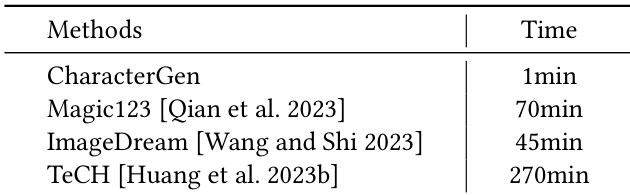
研究团队将本方法的生成速度与其他图像提示 3D 角色生成方法进行对比,结果表明该方法完成流程的速度显著快于替代方案。结果证明,CharacterGen 在实现高效 3D 角色生成的同时,保持了多视图图像与重建网格的高一致性与高质量。CharacterGen 的 3D 角色生成速度快于其他图像提示方法。该方法能够生成一致性多视图图像与高质量 3D 网格。在角色生成任务的速度与视觉质量方面,该方法均优于替代方案。
研究团队在 2D 多视图图像生成与 3D 角色重建任务上,将 CharacterGen 与多种基线模型进行对比评估,并通过定量指标与用户研究衡量其性能。这些实验验证了框架在保持强风格一致性、精准多视图对齐以及高几何与纹理保真度方面的能力,尤其在复杂角色姿态下表现稳定。用户反馈与效率基准测试进一步证实,相较于现有方法,该方法能提供更优的视觉质量与显著更快的生成速度。最终,结果确立了 CharacterGen 作为从单张图像提示生成一致性、高质量 3D 角色的稳健且高效解决方案的地位。