Command Palette
Search for a command to run...
掩码语言建模
摘要
一句话总结
本研究系统评估了法语生物医学掩码语言模型在各类自然语言处理任务中的子词分词策略,旨在确定分词粒度、数据源和形态学信息如何影响 token 一致性与任务性能。
核心贡献
- 本文提出了一种面向法语生物医学领域的形态素增强分词策略,将人工定义的语言形态素整合进字节对编码(Byte-Pair Encoding)和 SentencePiece 等统计算法中,以标准化黏着语术语的分词过程。
- 系统评估了统计分词器与实际语言词边界之间的对齐情况,并探究分词粒度如何影响各类下游任务的性能。
- 在 23 项法语生物医学自然语言处理任务(包括命名实体识别和语义文本相似度)上提供了全面的定性与定量基准测试,以展示形态素增强分词及训练数据源如何影响基于 BERT 的语言模型。
引言
子词分词已成为自然语言处理领域的标准方法,使预训练语言模型能够高效处理未登录词,并在各类应用中提升性能。尽管其应用广泛,但其成功背后的底层机制仍缺乏深入理解,尤其是在最优分词粒度与语言结构的系统性排除方面。在法语生物医学等专业领域,术语构建依赖于源自古典词根的严格黏着规则,但传统统计分词器往往忽略此类形态学知识,导致产生随意且不一致的词元切分,从而阻碍模型准确率的提升。为弥补这一差距,本文作者提出了一种形态素增强分词策略,将人工定义的语言单元直接嵌入标准统计算法中。通过在 23 项法语生物医学自然语言处理任务上评估该方法,作者展示了基于规则的分词如何提升 token 一致性,并为语言粒度与下游模型性能之间的关系提供了可操作的见解。
数据集
-
数据集构成与来源: 作者使用 DrBenchmark 套件中的 23 项下游自然语言处理任务评估模型,重点聚焦法语生物医学与临床文本。数据涵盖临床病例、药品标签、生物医学摘要、临床试验协议及处方对话录音。在分词器训练方面,作者整理了一份 1GB 的原始文本语料库,融合了法语生物医学内容(NACHOS)、英语生物医学文献(PubMed Central)、通用法语文本(法语维基百科)及多语言网络文本(CC100)。
-
各子集关键细节: DEFT-2020 提供 1,010 对句子用于语义文本相似度任务,以及 1,102 个样本用于多分类任务。DEFT-2021 包含 275 个临床病例,生成跨越 23 个 MeSH 轴线的 4,712 个多标签分类样本,并包含 13 种实体的命名实体识别标注。E3C 提供 1,402 个法语临床病例,标注了临床实体、时间信息与真实性。QUAERO 涵盖药品说明书与生物医学标题,包含 26,409 个映射至 5,797 个 UMLS 概念实体。MorFITT 包含 3,624 篇 PMC 开放获取摘要,标注了 12 个医学专科的多标签信息。Mantra-GSC 聚焦 EMEA、Medline 及专利文档的法语子集,用于生物医学命名实体识别。CLISTER 包含 1,000 对句子,相似度评分经多位标注者平均后介于 0 至 5 之间。CAS 包含 3,790 个临床病例,提供跨越 31 个类别的自动词性标注及否定标记。ESSAI 提供 7,247 个临床试验协议,提供跨越 41 个类别的自动词性标注。PxCorpus 包含 1,981 段转录对话录音,总时长 4 小时,用于跨越 4 个类别的意图分类及跨越 38 个类别的命名实体识别。
-
数据使用与划分: 作者仅将这些数据集严格用于下游任务评估,而非模型预训练。在缺乏预设划分的情况下,数据被随机划分为 70% 训练集、10% 验证集和 20% 测试集。分词器训练混合数据使用该整理后的 1GB 语料库生成 16 种独立的分词器,每种均配置 32k 词表大小,并在形态素集成算法与标准算法之间保持平衡。
-
处理与裁剪策略: 作者通过将全部文本转为小写来标准化分词器语料库。针对 QUAERO,将嵌套实体标注简化至最高粒度层级,此举移除了约 6% 至 9% 的标注,并将冗长的 EMEA 文档拆分为句子以符合模型输入限制。CLISTER 的相似度评分经多位标注者平均后生成连续浮点数值。CAS 与 ESSAI 的词性标注分别依赖 Tagex 与 TreeTagger 工具,在对照人工金标准时实现了高精度。
方法
作者采用两种基于统计的分词方法,即字节对编码(Byte Pair Encoding, BPE)与 SentencePiece,作为子词分割的基础方案。BPE 从独立字符开始,根据其在训练语料库中的出现频率,迭代将最高频的子词对合并为更大的单元。该过程生成的词表优先保留高频组合,从而实现对常见词形的高效表示。相比之下,SentencePiece 支持两种不同的分割算法(Unigrams 与 BPE),在控制子词单元粒度方面提供了更高的灵活性。尽管 SentencePiece 在法语生物医学自然语言处理领域日益普及,但其有效性可能因语言与领域而异,可能导致次优的分词结果。
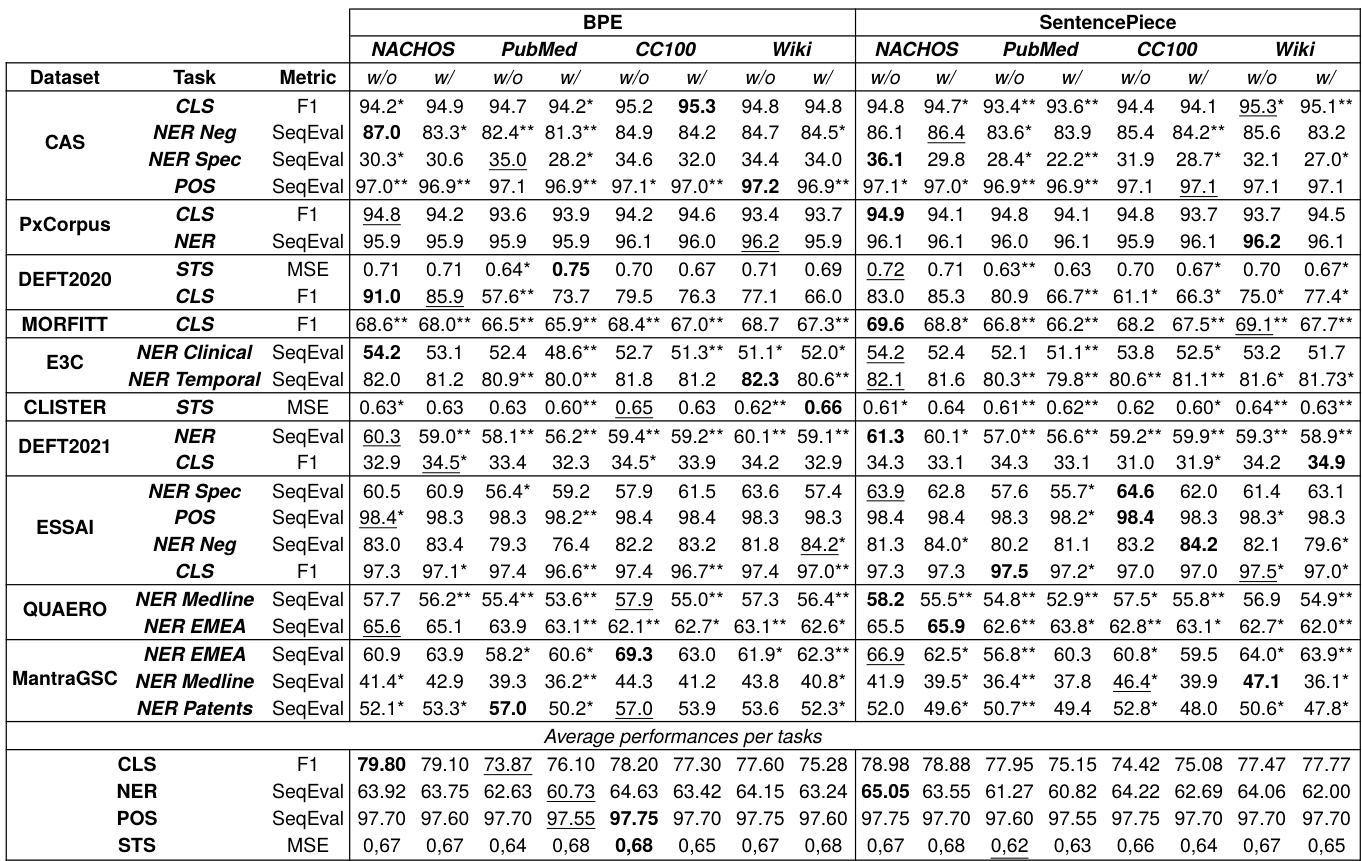
为增强专业医学术语的建模能力并缓解预训练期间未登录词的挑战,作者提出了一种新颖的形态素增强分词策略。该方法通过整合语言知识,将一份约 600 个常见于法语医学领域的人工筛选词汇形态素列表纳入其中,这些形态素源自 Cottez (1980) 等权威资料。此类形态素的示例包括 céphal-、clinico-、-thérapie、thoraco-、-ome 与 -gène。在分词过程中,这些形态素被视为固定的 token 单元。

如图所示,形态素增强分词框架通过强制包含预定义的形态素 token,对 BPE 与 SentencePiece 算法进行了修改。在训练阶段,当分词器遇到列表中的形态素时,会将其视为单个 token 处理,而非进一步分解。对于剩余文本,则应用所选算法(BPE 或 SentencePiece)的标准子词分割流程。这种混合策略在保留有意义形态单元的同时,维持了统计分词方法的适应性,从而改善医学术语的表示能力并降低未登录词的影响。
实验
该评估框架使用标准化的微调协议,在 23 项下游任务上评估法语生物医学语言模型,以独立考察分词策略的影响。验证分词粒度的实验表明,较粗的分割通常能带来更高的性能,尤其在上下文敏感任务中;而评估形态素增强的实验显示,明确的语言规则虽能提升分割准确率,但受限于模型固有的鲁棒性,并未始终一致地提升下游结果。最后,关于训练数据源的测试证实,与目标语言对齐的语料库通过防止 token 稀疏与过度分割,其表现优于语言不匹配的领域特定数据。
作者描述了一项针对法语生物医学语言模型的分词策略评估实验,该实验在多项任务中采用了一致的训练与评估协议。结果表明,训练数据的选择对性能影响显著,部分非领域特定数据源的表现优于其他数据源,且形态素增强的效果因任务与模型而异。性能因训练数据源不同而产生显著差异,非领域特定数据有时甚至优于领域特定数据。形态素的引入并未在所有任务与分词策略中一致地提升模型性能。整体趋势显示,较高性能与较少的子词单元数量呈正相关,尤其在序列到序列(sequence-to-sequence)与语义文本相似度(STS)等特定类型任务中。

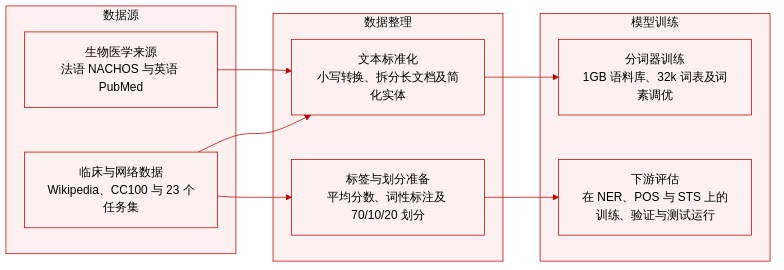
作者分析了在不同数据源上训练的分词器中形态素的覆盖率,重点关注分词策略与数据选择如何影响形态素表示。表格显示,基于 NACHOS 与维基百科训练的分词器展现出更高的形态素覆盖率,尤其在较短形态素方面;而 CC100 与 PubMed 训练出的分词器在所有长度范围内覆盖率均较低。这种形态素表示的差异与训练数据的语言及领域特定特征密切相关。与基于 PubMed 和 CC100 训练的分词器相比,基于 NACHOS 和维基百科训练的分词器具有更高的形态素覆盖率。对于较长形态素,覆盖率显著下降,尤其是在基于 PubMed 和 CC100 训练的分词器中。BPE 与 SentencePiece 在形态素覆盖率上呈现相似趋势,具体差异取决于训练数据源。
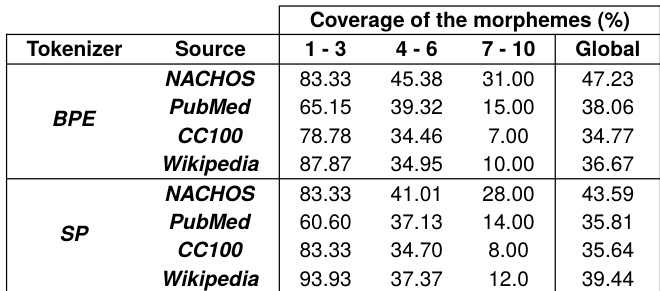
作者利用多种下游任务评估分词策略对法语生物医学语言模型的影响。结果表明,性能在不同任务与分词方法间差异显著,没有任何单一策略能始终超越其他策略,且训练数据的选择对模型结果具有实质性影响。性能在不同任务与分词方法间存在波动,无单一策略能持续取得最佳结果。训练数据的选择显著影响模型性能,与领域相关的数据通常优于领域特定但语言不匹配的数据。在分词器中引入形态素提升了分割质量,但并未始终带来下游任务性能的改善。
作者评估了分词策略对法语生物医学语言模型的影响,重点关注分词粒度、形态素增强及数据源的作用。结果表明,尽管形态素增强分词器提升了分割准确率,但并未始终导向更好的下游性能,且训练数据的选择显著影响模型结果。最佳结果由在领域特定数据上训练的经典统计分词器取得,即便未进行形态素增强。形态素增强提升了分割准确率,但未能始终增强下游任务性能。分词粒度与模型性能呈相关性,子词单元较少通常对应更高分数。训练数据源影响显著,即便存在潜在过度分割问题,领域特定数据仍优于跨语言数据源。
作者开展了一项实验,评估分词策略对法语生物医学语言模型的影响,重点考察分词粒度、形态学信息及数据源的作用。结果显示,性能在不同任务与分词方法间差异显著,无单一策略能持续领先。本研究还探讨了微调期间冻结模型不同组件的效果,揭示了任务对词嵌入与编码器的特定依赖关系。性能在不同任务与分词方法间存在波动,无一致的优选策略。冻结编码器对词性标注与 STS 等任务影响更大,表明这些任务具有更强的上下文依赖性。分词粒度与性能相关,子词单元较少通常对应更高分数。
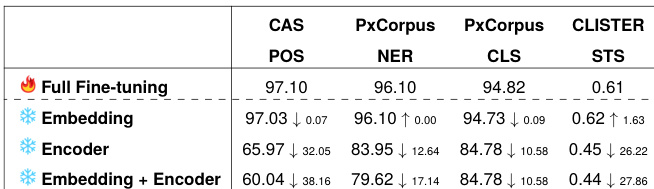
实验在多项下游任务上评估了多种分词策略(包括形态素增强与子词粒度),以考察其对法语生物医学语言模型的影响。结果表明,训练数据的选择对模型结果影响重大,领域特定语料库通常表现更优,尽管非领域数据源偶尔具备优势。尽管形态素增强持续提升了分割准确率,但未能可靠地改善下游任务性能,且包含较少子词单元的粗粒度分词通常与更高分数相关。此外,微调分析揭示了任务对冻结模型组件的特定依赖,证实没有任何单一分词策略能在所有生物医学自然语言处理应用中普遍优化结果。