Command Palette
Search for a command to run...
用于无监督机器翻译的快速回译
用于无监督机器翻译的快速回译
Benjamin Brimacombe Jiawei Zhou
快速部署 ChatGLM2-6b-32k
摘要
无监督机器翻译领域因Transformer与回译算法的结合而取得了显著进展。Transformer是一种强大的生成模型,而回译则利用Transformer的高质量翻译结果进行迭代式自我改进。然而,Transformer在回译过程中受限于自回归推理的运行时间,且回译方法因合成数据效率低下而受到制约。我们提出了一种针对Transformer回译的“一举两得”改进方案:快速回译(Quick Back-Translation, QBT)。QBT将编码器重新用作生成模型,并结合原始的自回归回译步骤,利用编码器生成的序列来训练解码器,从而提升了数据吞吐量和利用率。在多个WMT基准上的实验表明,相对较少的QBT精炼步骤即可提升当前无监督机器翻译模型的性能,并且在获得可比拟的翻译质量时,QBT在训练效率方面大幅优于仅使用标准回译的方法。
一句话总结
作者提出快速回译(Quick Back-Translation, QBT),这是一种无监督机器翻译方法。该方法将 Transformer 编码器重新用作生成模型,与标准的自回归回译并行训练解码器,从而在保持 WMT 基准测试中相当翻译质量的同时,提升数据吞吐量和训练效率。
核心贡献
- 快速回译(QBT)将 Transformer 编码器重新用作非自回归生成模型,以生成合成序列供解码器训练,与标准的自回归回译并行进行。
- 该方法颠覆了传统的知识蒸馏范式,利用双向编码器为强大的自回归解码器生成训练数据,从而提升合成数据的吞吐量与利用率。
- 多项 WMT 基准测试实验表明,QBT 在仅需少量精炼步骤的情况下,相比标准回译显著提升了训练效率,同时保持相当的翻译质量。
引言
无监督机器翻译使神经网络模型能够仅从单语语料中学习跨语言映射,使得在缺乏精心构建的平行语料库的低资源语言中实现自动翻译成为可能。现有方法主要依赖基于自回归解码器的迭代回译,其逐个生成 tokens,在长文本上计算成本高昂,同时持续面临维持足够合成数据多样性的挑战。作者将 Transformer 编码器作为独立的非自回归模型,用于快速生成合成翻译,并提出一种两阶段蒸馏框架,将高度多样的信号直接注入解码器。该策略在保留标准编码器-解码器架构的同时,实现了显著的训练加速与具有竞争力的翻译质量,尤其适用于长序列。
数据集
- 数据集构成与来源:提交的文本中未提供数据集构成或来源信息。
- 各子集关键细节:未说明子集规模、来源或过滤规则。
- 数据使用方式:未描述训练集划分、混合比例或数据使用流程。
- 处理细节:未概述裁剪策略、元数据构建或其他预处理步骤。
方法
提出的快速回译(QBT)框架通过重新将 Transformer 编码器用作非自回归(NAR)生成模型,重构了标准回译流水线,从而实现更快、更高效的数据利用。整体架构整合了三个核心组件:编码器回译(EBT)、编码器回译蒸馏(EBTD)与标准回译(BT)。根据训练目标的不同,这些组件可同步或分阶段应用。如图下所示,该框架以标准的 Transformer 编码器-解码器架构为起点,其中编码器以双向方式处理输入序列,解码器以自回归方式生成输出。核心创新在于修改该流程以利用编码器直接生成翻译的能力,从而消除合成数据生成过程中自回归推理的瓶颈。
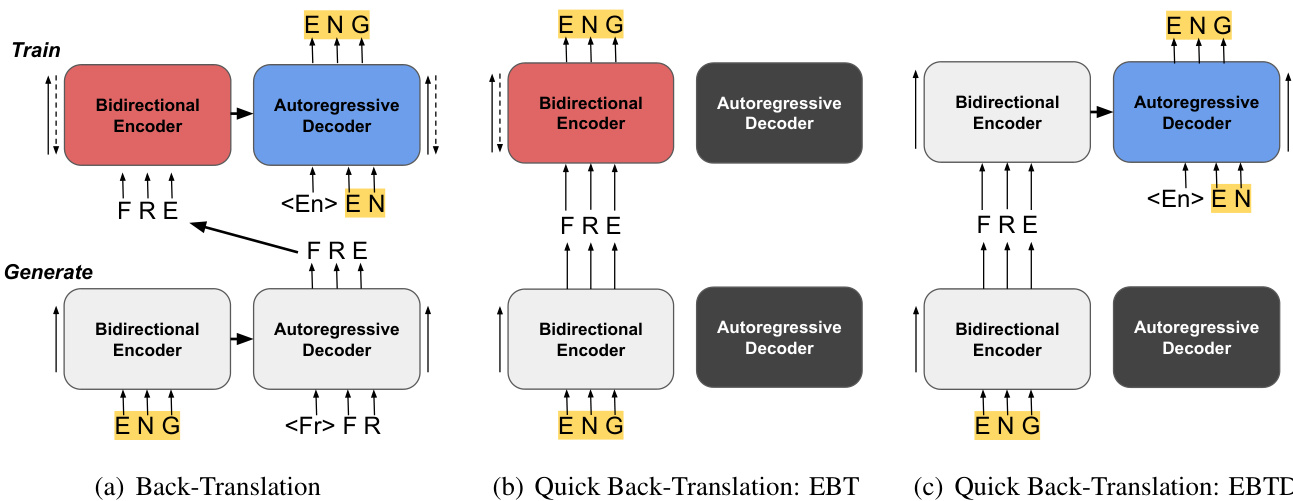
第一个组件编码器回译(EBT)旨在训练编码器以非自回归方式执行翻译。在此阶段,编码器用于从目标序列生成源序列,实质上将其视为精简版的 NAR 模型。生成的序列随后作为合成平行数据,用于更新编码器参数与嵌入表示。该过程在两个翻译方向上迭代应用,交替进行源到目标与目标到源的生成,从而使编码器与翻译目标对齐。得到的编码器随后可作为后续训练步骤中合成数据的快速生成器。
第二个组件编码器回译蒸馏(EBTD)利用编码器输出来优化解码器。在此步骤中,编码器用于从目标序列生成源序列,随后将这些配对输入完整的编码器-解码器模型。解码器使用编码器生成的源序列作为输入,被训练以预测原始目标序列。编码器参数在此过程中保持冻结,以保留其翻译质量。该蒸馏过程将多样化的训练信号注入解码器,在无需依赖标准回译缓慢的自回归采样的情况下,增强其生成能力。
最后一个组件标准回译(BT)用于微调完整模型并确保高质量翻译。它以传统方式运行,使用解码器从源序列生成合成目标序列,随后利用这些序列对编码器-解码器模型进行监督训练。QBT 框架以两种配置组合这些组件:QBT-Synced(同步模式),即在模型经标准 BT 训练收敛后同步应用 EBT 与 EBTD 以提升性能;以及 QBT-Staged(分阶段模式),即在从零开始的训练过程中按顺序应用各组件,以逐步构建编码器与解码器的翻译能力。该分阶段方法确保编码器首先掌握基础翻译技能,随后才被用于为解码器生成高质量合成数据。
实验
研究在标准 WMT 基准测试与编程语言任务上进行评估,测试了所提出的同步与分阶段回译框架在大规模、资源受限及长序列条件下的表现。大规模试验验证了该方法以极小计算开销持续优化现有模型的能力,而资源受限与长序列实验则证实了其卓越的训练效率与收敛稳定性。定性评估与表征对齐分析进一步表明,该方法能有效防止句法退化并增强编码器-解码器的一致性。最终,研究结果表明,将编码器重新用于回译,为多样化翻译任务提供了一种稳健且高度可扩展的传统基线替代方案。
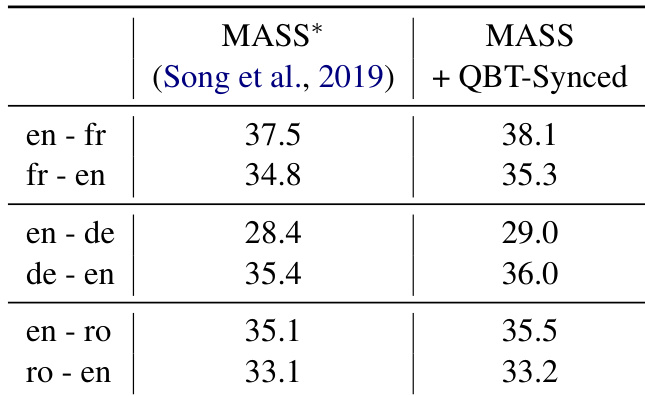
作者利用 WMT 数据集在机器翻译任务上评估了所提出的 QBT-Synced 方法,并与使用预训练 UMT 检查点初始化的基线模型进行对比。结果表明,该方法在不同语言对上实现了一致的性能提升,尤其在英法与英德翻译方向上,性能优于基线模型。QBT-Synced 在多个语言对上提升了基线性能,在英法与英德翻译中均取得增益。该方法在不同翻译方向上持续优于原始 UMT 模型,表明其改进具有稳健性。提升最显著的方向为英法翻译,所提方法在此方向上取得了高于基线的分数。
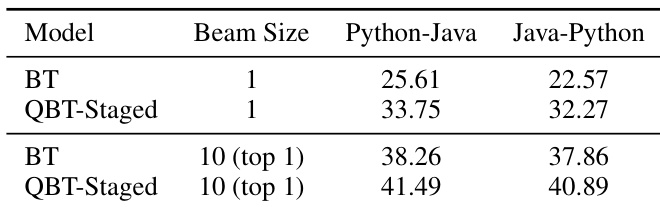
作者利用无监督编程语言翻译任务评估了所提出的 QBT-Staged 方法,并与基线 BT 方法进行比较。结果表明,QBT-Staged 在 Python-Java 与 Java-Python 两个方向上均取得了高于基线的 BLEU 分数,且随着 beam size 的增加,提升效果更为明显。在使用较大 beam size 进行解码时,该方法展现出一致的增益。QBT-Staged 在两种编程语言翻译方向上均优于基线 BT 模型。随着 beam size 提高,QBT-Staged 与基线之间的性能差距进一步扩大。QBT-Staged 在 Python-Java 与 Java-Python 翻译中均取得高于基线的 BLEU 分数。
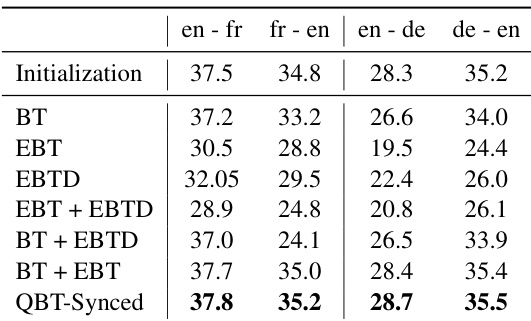
作者利用 WMT 数据集在机器翻译任务上评估了所提出的 QBT-Synced 方法,并与多种基线及消融实验进行对比。结果表明,QBT-Synced 方法在不同语言对上持续取得具有竞争力或更优的性能,在某些配置下增益显著。该方法在大规模与资源受限设置下均展现出有效性,其高效性通过更快的训练速度与提升的数据吞吐量得以体现。QBT-Synced 在所有语言对上取得最佳性能,优于或持平于其他方法(包括 BT、EBT 及 EBTD 的组合)。QBT-Synced 方法相较于初始化状态展现出一致的提升,尤其在英法与英德方向上。该方法在大规模与资源受限场景中均有效,在训练与推理阶段展现出稳健性与高效性。
作者利用 BLEU 分数作为评估指标,在多个语言对上将所提出的 QBT-Synced 方法与现有无监督机器翻译方法进行对比。结果表明,QBT-Synced 取得具有竞争力的性能,尤其在微调预训练模型时,在多个翻译方向上优于基线方法。该方法在不同语言对上持续优于或持平于已有模型的性能。QBT-Synced 在多个翻译方向上改进了基线模型,在各语言对上展现出一致的增益。所提方法取得与最先进模型相当或更优的性能,尤其在英德与英罗翻译中。QBT-Synced 在直接应用于未进行回译调优的预训练模型时仍能保持强劲性能,表明其在低资源设置下的有效性。
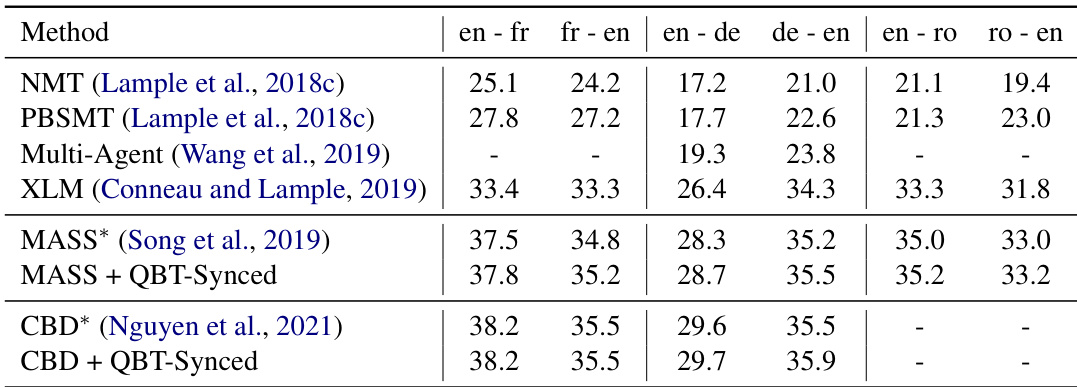
作者利用无监督机器翻译任务评估了所提出的 QBT-Staged 方法,并在多个语言对上与 BT 基线进行对比。结果表明,QBT-Staged 持续优于 BT 基线,在两个翻译方向上均观察到性能提升。该方法在不同语言对上展现出稳健的性能,并在所有评估任务中取得更高分数。QBT-Staged 在所有语言对上均优于 BT 基线。对于每种语言对,提升效果在两个翻译方向上保持一致。QBT-Staged 在所有评估任务中均取得高于基线的 BLEU 分数。
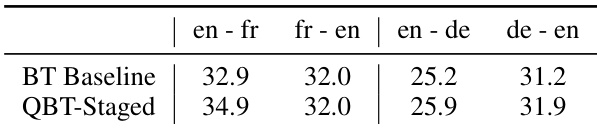
作者利用无监督机器翻译与编程语言翻译任务,评估了所提出的 QBT-Synced 与 QBT-Staged 方法,并在多个语言对上与已有基线模型进行对比。实验结果表明,两种方法均持续优于或持平于现有方法。QBT-Synced 在大规模与低资源设置下均带来稳健的质量提升与训练效率。同时,QBT-Staged 在双向代码翻译中展现出可靠的增益,且其性能随解码 beam size 的增加呈正向扩展。总体而言,研究结果验证了所提出的同步与分阶段策略在提升无监督翻译系统稳定性与质量方面的有效性。