Command Palette
Search for a command to run...
SetFit: 高效的无提示少样本学习
摘要
一句话总结
作者提出了一种框架,通过从文本中预测每个类别的视觉特征分布的均值与协方差,推断隐式类别统计信息。该方法通过丰富隐空间,提升了CLIP等基础模型在多个数据集上的跨域鲁棒性与少样本分类性能。
核心贡献
- 本文提出了一种预测框架,利用从文本中提取的统计信息来估计CLIP等基础模型中每个类别的视觉特征分布的均值与协方差。
- 该方法将文本输入视为统计摘要,而非辅助提示词或生成种子,从而丰富隐式特征空间以增强跨域鲁棒性。
- 在多个数据集上的综合评估表明,与以往的自适应技术相比,引入这些预测的分布统计信息能够持续提升少样本分类性能。
引言
以CLIP为代表的基础模型已显著推动了少样本学习的发展,但在训练数据有限时,它们往往难以保证跨域鲁棒性。以往结合文本的方法通常将其视为简单的提示词或辅助数据源,忽略了其在建模视觉特征统计结构方面的潜力。作者利用从文本中提取的统计信息来预测各类别视觉特征分布的均值与协方差。通过将这类基于文本的参数映射到隐空间中,该方法丰富了模型的表征能力,并在多个基准测试中实现了更鲁棒的少样本分类器。
数据集
- 作者选用ImageNet和iNaturalist作为基础数据集,使用在严格不相交的LAION400M语料库上预训练的CLIP ResNet50模型提取视觉与文本特征。
- 选择iNaturalist是因为其具有层级结构和细粒度物种类别,需要精确的协方差矩阵建模;评估则在预留的基础子集或九个跨域基准上进行,分别为:Caltech、EuroSAT、Food、Flowers、SUN397、DTD、Pets、Cars和UCF101。
- 作者将该数据集应用于少样本学习实验,完全依赖预训练的CLIP主干网络进行特征提取,未采用自定义的裁剪流程或元数据构建管线。
- 所有阶段均保持严格的分布隔离:LAION400M仅用于预训练,基础数据集用于模型自适应,不相交或跨域划分仅用于评估,以验证鲁棒的泛化能力。
方法
作者采用两阶段框架,直接从文本描述中预测类别的视觉特征分布均值与协方差,旨在通过文本引导的统计建模提升少样本学习性能。整体流程包含学习阶段与自适应阶段,如下图所示。
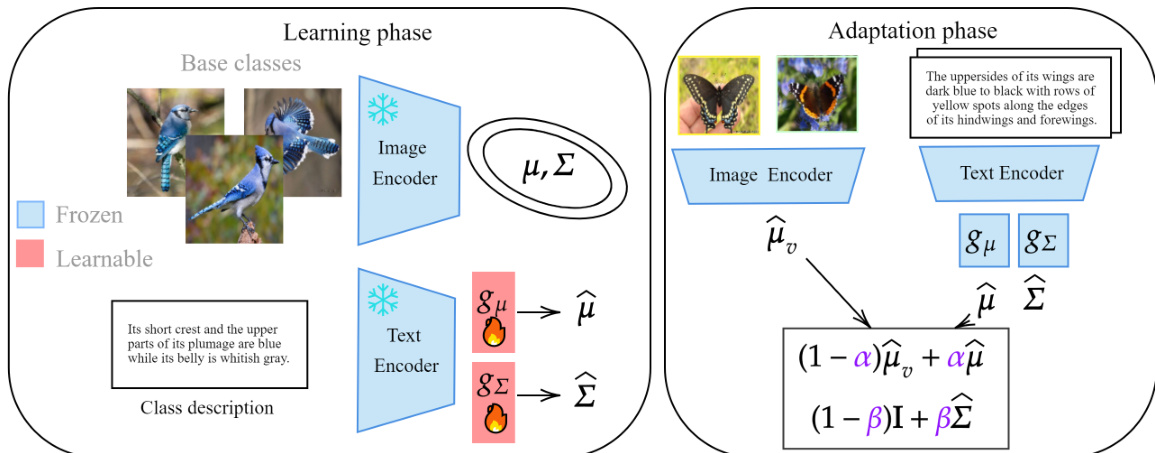
在学习阶段,该方法训练两个独立的映射网络,从文本中估计视觉特征的均值与协方差。框架始于预训练的图像编码器 fv 和文本编码器 ft,分别用于从图像及其对应的文本描述中提取特征。此阶段图像编码器保持冻结,文本编码器则根据设置可选择冻结或可学习。文本描述可通过预定义模板(如 "a photo of a {class}")生成,或使用GPT-3生成更丰富的视觉描述。对于每个类别,基于基础数据集中图像的视觉特征计算经验均值 μ~i 和协方差 Σ~i。随后,利用这些统计信息训练两个轻量级多层感知机(MLP),记为 gμ 和 gΣ,分别将文本特征 si 映射至预测的均值与对角协方差。每个网络的训练目标为预测统计量与经验统计量之间的 L2 损失,并辅以权重衰减等正则化项。
在自适应阶段,学习到的映射被应用于新的下游少样本任务。给定目标类别的少量标注样本,从可用图像中计算经验均值 μ^i,v。随后,使用学习到的系数 α 将文本编码器预测的均值 gμ(si) 与该经验均值进行插值:μ^i=(1−α)μ^i,v+αgμ(si)。该插值过程平衡了文本推导估计的可靠性与观测数据。针对协方差,由于少量样本的估计方差较高且不可靠,采用收缩方法。预测协方差 gΣ(si) 与单位矩阵 I 通过收缩系数 β 结合:Σ^i=(1−β)I+βgΣ(si)。这确保了协方差矩阵的稳定性与良好条件数。最终得到的均值与协方差估计值用于分类(通常通过高斯模型),使系统即使在视觉数据有限的情况下也能实现有效泛化。
实验
实验评估了一种将文本类别描述映射至视觉特征统计量的框架,验证了与CLIP对齐的文本表示能够可靠地预测域内与跨域场景下视觉分布的均值与协方差。当将其整合至用于少样本任务的马氏距离分类器时,这些基于文本的统计信息始终能超越仅依赖视觉的基线方法,其中协方差矩阵在一类分类与低样本量场景中尤为关键。最终,同时结合预测的均值与协方差在多个数据集上带来了稳健的性能提升,表明文本先验可有效弥补视觉样本的不足,并弥合零样本学习与少样本学习之间的差距。
作者评估了在少样本分类任务中使用文本推导的均值与协方差预测的影响,并在多个数据集上对比了不同方法。结果表明,同时引入文本中的均值与协方差始终能提升基线性能,在一类设置及基线性能较低的数据集上提升尤为显著。协方差的优势在一类任务中更为明显,而均值预测在低样本量场景中更具优势。同时使用文本预测的均值与协方差在各类数据集与设置中均能稳定提升分类性能。协方差预测在一类分类任务中带来更大提升,尤其在低样本量场景下。文本均值预测在极低样本量场景中提供显著增益,而协方差的收益在不同样本量水平下更为一致。
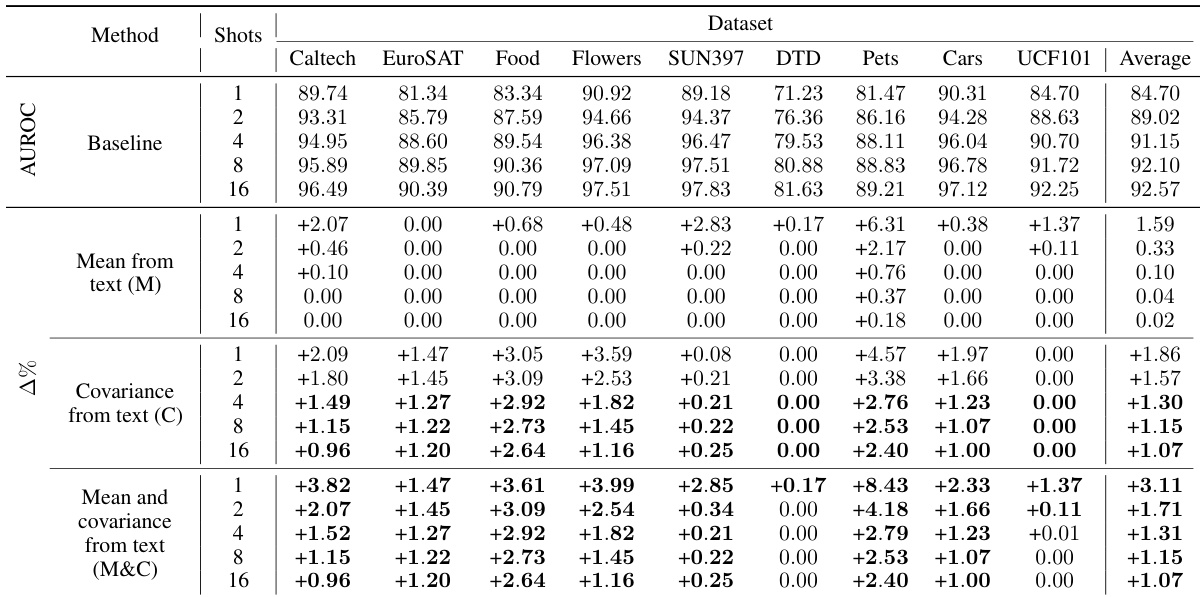
作者开展实验以评估基于文本的模型预测少样本分类任务视觉特征均值与协方差的能力。结果表明,引入文本预测的均值与协方差可在不同设置下提升分类性能,其中协方差尤其在在一类场景中提供稳定增益。性能提升在低样本量场景及基线性能较低的数据集上更为明显。从文本预测均值与协方差可显著提升少样本分类性能。协方差预测在一类与多类设置中均持续改善结果,尤其在低样本量场景下。该方法取得的增益可与使用少量标注样本相媲美,甚至能实现有效的零样本分类。
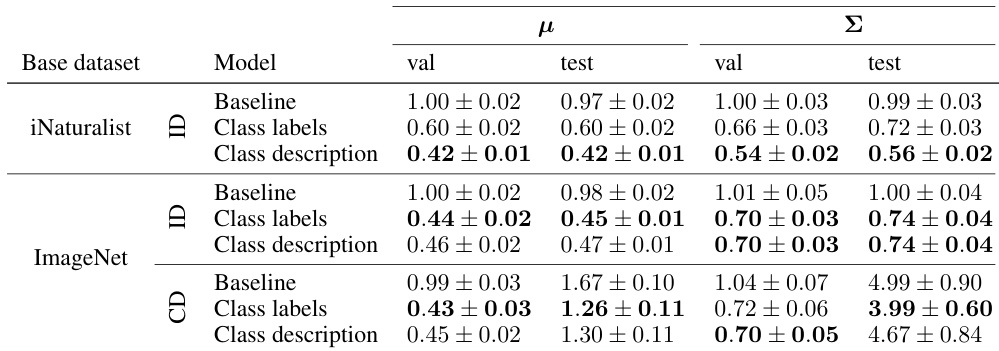
作者在多个数据集上评估了在少样本分类任务中使用文本推导的均值与协方差预测的影响。结果表明,在不同设置下,同时引入文本中的均值与协方差始终能超越基线性能,其中协方差在一类分类中贡献更大,均值在低样本量场景中带来更高增益。在基线性能相对于零样本性能较低的数据集上,改进尤为突出。在两类与多类设置中,使用文本推导的均值与协方差预测均能稳定提升分类性能。文本提供的协方差改进幅度大于均值,尤其在一类分类任务中。最大增益出现在低样本量场景及基线性能相对于零样本性能较低的数据集上。
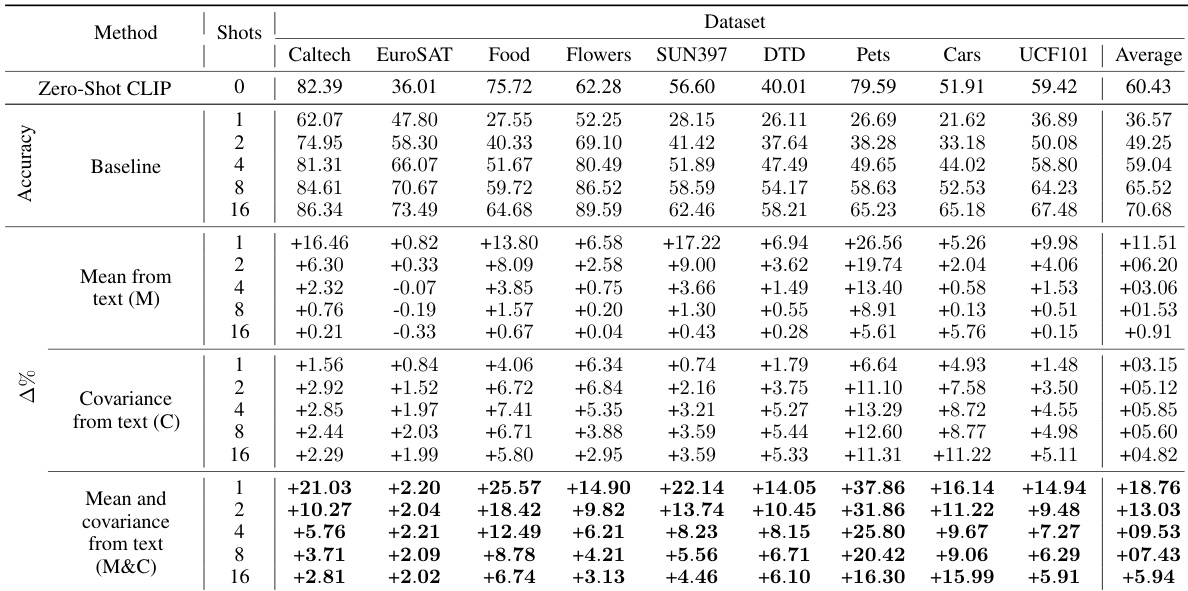
作者评估了从文本预测视觉特征均值与协方差对多个数据集及训练模式下少样本与零样本分类任务的影响。实验验证了引入这些基于文本的统计预测始终能提升分类准确率,其中协方差在一类设置中带来最显著增益,均值预测则在极低样本量场景中驱动明显改进。这些定性优势在基线性能较弱的数据集上尤为明显,表明文本先验能在数据稀缺时有效稳定特征分布。最终,该方法证明基于文本的统计建模可可靠地近似有限标注样本的优势,同时实现鲁棒的零样本迁移。