Command Palette
Search for a command to run...
一键部署 MedGemma-27b-text-it 医学推理大模型
摘要
一句话总结
作者提出了一种分析框架,通过在具有已知疾病和偏差效应的合成神经影像上训练卷积神经网络(CNN)分类器,系统评估医学影像中的 AI 偏差。该框架使研究人员能够在反事实数据场景中客观评估缓解策略,其中重加权(reweighing)被证明最为有效,且可解释 AI 方法有助于调查偏差的表现形式。
核心贡献
- 本研究引入了一种结构化分析框架,利用具有已知疾病效应和可控偏差来源的合成三维神经影像,系统探究虚假相关性在深度学习模型中的表现机制。注入偏差的真实标签知识使得研究人员能够客观测量缓解策略的有效性,而无需依赖难以识别的临床混杂因素。
- 该方法评估了受控偏差的影响,并在卷积神经网络分类器上利用反事实数据场景系统测试了三种偏差缓解策略。该实验设计将模型学习行为与未知的现实世界混杂因素隔离开来,以确保基准测试的可重复性。
- 实验结果表明,在带有偏差的数据集上训练会产生预期的子群体性能差异,并确定重加权是该配置下最有效的缓解策略。该框架进一步表明,可解释人工智能方法能够有效追踪模型决策过程中学到的偏差属性。
引言
医学影像人工智能正日益被部署以辅助临床决策,但带有偏差的训练数据通常导致模型在不同患者子群体中表现不均,从而威胁诊断公平性与患者安全。评估这些差异并测试缓解策略仍然十分困难,因为现实世界的影像数据集包含复杂且无法控制的虚假相关性,几乎难以隔离。尽管简单的基准数据集允许研究人员在受控环境中研究人为偏差,但它们缺乏临床三维扫描的解剖学规模与复杂性。为弥补这一差距,作者引入了一种结构化框架,将基准数据集的可定制控制与三维医学影像的真实维度相结合。该方法使研究人员能够系统追踪隐藏偏差在深度学习流水线中的表现,并在临床采用前客观验证公平性缓解技术的鲁棒性。
数据集

• 数据集构成与来源: 作者使用 SimBA 框架生成合成的 T1 加权脑部 MRI 扫描图像。基础模板为使用 LPBA40 标签注释的 SRI24 图谱,具有 173×211×155 的体素网格,各向同性分辨率为 1 mm。所有形态学变化均源自主成分分析模型,该模型使用来自 IXI 数据库的 50 张真实 T1 加权 MRI 的静止速度场进行训练,这些图像已非线性配准至图谱。
• 子集细节与结构: 每个生成的数据集包含 2002 张三维图像,分为两个目标类别:疾病(1000 张)与非疾病(1002 张)。这些图像根据是否存在额外的局部形态学效应进一步划分为两个偏差组。偏差组占疾病类的 70% 和非疾病类的 30%。作者创建了三个配对场景作为反事实对照:无偏差条件、近端偏差条件(效应作用于紧邻疾病区域的左侧壳核)以及远端偏差条件(效应作用于对侧半球的右侧中央后回)。
• 数据使用与训练设置: 合成图像用于训练卷积神经网络以预测疾病状态。偏差表示的故意不平衡旨在评估深度学习模型是否将偏差效应作为预测捷径加以利用。为确保跨场景的公平评估,作者在每个配对数据集中保持受试者和疾病效应一致,并应用分层抽样,使受试者和疾病效应的大小分布在所有类别和偏差组中保持一致。
• 处理与元数据构建: 疾病状态通过对左侧岛叶皮层应用局部形变进行编码。通过非线性形变,每个模拟受试者的全局脑部形态呈现唯一变化。作者预先对采样分布进行分层,以防止效应大小引入混杂变量。所有生成的数据集以及训练、验证和测试划分均与生成代码一同公开提供。
方法
作者利用系统分析框架探究医学影像 AI 模型中偏差的影响,使用 Simulated Bias in Artificial Medical Images (SimBA) 工具生成合成神经影像。该框架通过将用户定义的偏差引入结构化神经影像数据集,实现受控的计算机模拟试验,从而评估此类偏差对深度学习流水线的影响。该方法的核心在于生成反事实配对受试者合成数据集,这些数据集要么在大脑特定空间区域包含已知偏差,要么完全不含偏差。随后,这些数据集在相同条件下用于训练卷积神经网络(CNN)分类器,从而直接评估偏差对不同子群体模型性能的影响。
如图所示:整体流水线始于使用 SimBA 生成合成神经影像,从而实现对偏差引入的精确控制。生成的数据集随后用于训练 CNN 分类器,模型架构由特征编码器和最终的全连接分类层组成。所有实验条件下的训练流程保持一致,确保观察到的任何性能差异均可归因于偏差的存在与否。
为评估偏差缓解策略的有效性,应用了三种不同的方法。重加权(Reweighing)按照 Calders 等人的提议实施,根据偏差组与疾病类别的组合调整样本权重。该方法旨在平衡训练过程中不同子群体的影响,从而降低模型对偏差特征的依赖。第二种方法为偏差消除(bias unlearning),遵循 Dinsdale 等人描述的方法。该技术涉及训练一个双头 CNN,一个头用于疾病分类,另一个头用于偏差组预测。在疾病分类头初步收敛后,训练偏差预测头,模型经历一个迭代过程,在此过程中最小化疾病预测的损失并最大化偏差预测的损失。这迫使特征编码器将偏差相关特征与疾病相关特征解耦,从而有效消除偏差。第三种策略为偏差组模型方法,涉及在全数据集上预训练 CNN,然后在偏差和非偏差子群体上分别训练独立的模型。计算每个子群体模型的性能指标(如准确率、真正例率和假正例率),并利用其差异量化子群体性能差距。
实验
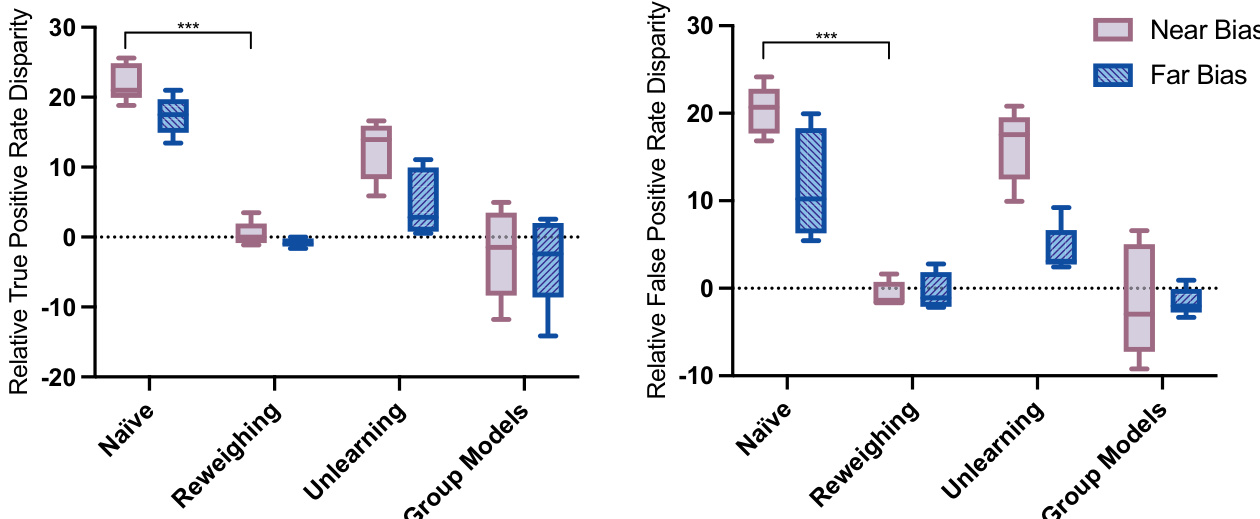
本研究利用带有模拟神经影像数据集的受控反事实框架,系统评估空间局部形态偏差如何影响深度学习模型,并测试各种缓解策略的有效性。实验结果表明,引入的偏差通过促进捷径学习触发了显著的子群体性能差异,当偏差区域距离目标疾病特征越远时,这些效应会减弱。对比测试显示,重加权成功消除了性能差距,而偏差消除未能将偏差与诊断特征解耦,组模型表现出的差异则由类别不平衡驱动而非模拟偏差。通过将模型可解释性输出与这些受控结果对齐,该框架在现实部署前为评估算法偏差和缓解策略建立了严格、客观的基线。
作者评估了模拟形态偏差对不同偏差场景下 CNN 模型性能的影响,并评估了偏差缓解策略的有效性。结果表明,偏差的存在导致显著的性能差异,各缓解方法在缩小这些差异方面的能力各不相同,可解释性分析也支持模型对偏差相关特征的依赖。与无偏差场景相比,偏差的存在显著增加了性能差异,且偏差越靠近疾病区域,差异越大。重加权能有效缓解性能差异,而偏差消除和组模型的效果有限或不一致。显著性分析显示,模型在预测时依赖偏差相关区域,可解释性结果与观察到的性能表现相符。
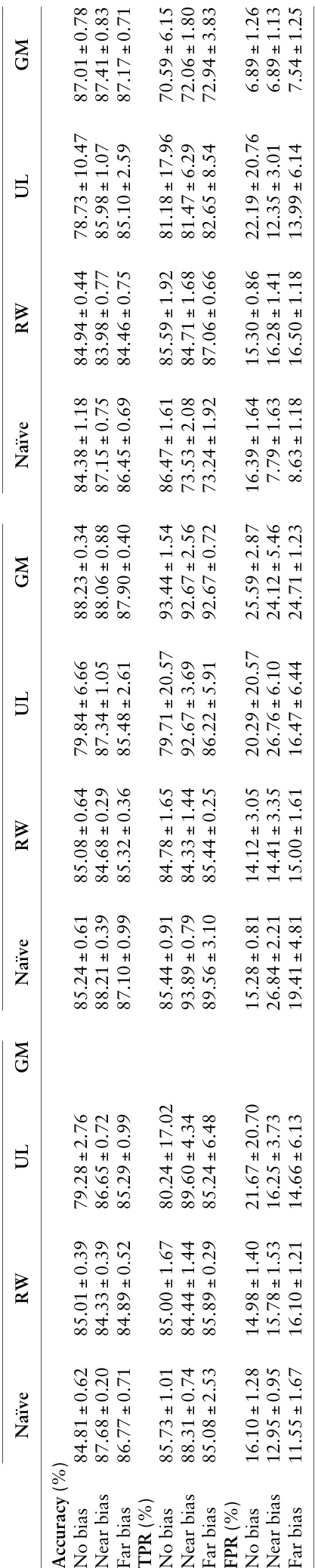
实验评估了模拟形态偏差对卷积神经网络的影响,并测试了多种降低其影响的策略。引入偏差会产生显著的性能差异,且当偏差位于疾病区域附近时差异加剧,可解释性分析证实了模型高度依赖这些偏差特征。在测试的干预措施中,重加权成功缩小了性能差距,而偏差消除和基于组的方法带来的改善有限或不一致。总体而言,本研究证明形态偏差会严重损害模型可靠性,并确定重加权为最有效的缓解策略。