Command Palette
Search for a command to run...
Jais和Jais-chat:以阿拉伯语为中心的基础指令微调开放生成大型语言模型
Jais和Jais-chat:以阿拉伯语为中心的基础指令微调开放生成大型语言模型
一键部署通义千问 72B Chat Int4 模型 Gradio Demo
摘要
我们推出了Jais和Jais-chat,这是两款全新的、以阿拉伯语为中心的、基于GPT-3解码器架构且经过指令微调的开放生成大型语言模型(LLMs)。这些模型在包含多种编程语言源代码的阿拉伯语和英语文本混合数据上进行预训练。拥有130亿参数的模型在广泛的评估中展现出比现有任何开放阿拉伯语和多语言模型更出色的阿拉伯语知识和推理能力,优势显著。此外,尽管使用的英语训练数据较少,这些模型在与英语中心且规模相似的开放模型相比,在英语任务上仍具有竞争力。我们详细描述了模型的训练、微调、安全对齐及评估过程。我们发布了该模型的两个开放版本——基础Jais模型和指令微调后的Jais-chat变体——旨在促进对阿拉伯语LLM的研究。
一句话总结
本文介绍了 Jais 和 Jais-chat,这是两款基于 GPT-3 仅解码器架构构建的 130 亿参数开源阿拉伯语中心基础模型及指令微调大语言模型。它们使用包含源代码的阿拉伯语和英语混合文本进行预训练,在阿拉伯语知识与推理方面优于现有开源模型,同时在英语方面保持竞争力(尽管训练数据较少),其发布旨在促进阿拉伯语 LLM 的研究。
核心贡献
- 本文介绍了 Jais 和 Jais-chat,这是两款基于 GPT-3 仅解码器架构的 130 亿参数生成式语言模型,使用包含多种编程语言源代码的阿拉伯语、英语及代码混合数据进行预训练。
- 详细阐述了全面的指令微调与安全对齐流程,以及一套自定义评估流水线。该流水线利用人工翻译与内部机器翻译系统对英语中心基准进行测试适配,以进行严格的阿拉伯语评估。
- 大量评估表明,尽管英语数据占比显著较低,该模型仍能在阿拉伯语知识与推理方面达到最先进水平,并在与英语中心开源模型规模相近的情况下保持竞争力。
引言
大语言模型已彻底改变自然语言处理领域,但尽管全球有超过 4 亿人使用阿拉伯语,该领域仍严重偏向英语。以往的开源模型要么仅专注于英语,要么在训练数据有限的情况下将其塞入超大规模多语言架构中,从而稀释了阿拉伯语的性能。作者采用了一种策略性的双语预训练方法来克服数据稀缺与语言失衡的挑战。本文推出了 Jais 和 Jais-chat,这是两款 130 亿参数的生成式模型,基于精心筛选的阿拉伯语、英语文本与编程代码混合数据构建。通过实施专门的阿拉伯语文本处理流水线、优化双语数据比例,并应用带有安全护栏的严格指令微调,作者提供了首批开源的阿拉伯语中心 LLM。这些模型在保持强大英语推理能力的同时,性能优于现有的多语言替代方案。
数据集
数据集构成与来源
- 作者构建了一个包含阿拉伯语、英语和编程代码的多语言预训练语料库,总计约 395 billion tokens。
- 阿拉伯语数据来源于十余个公共与内部来源,包括新闻档案、网络爬虫数据、维基百科、书籍、联合国会议记录以及专门区域语料库。
- 英语与代码数据主要源自 The Pile,该集合包含 22 个高质量数据集,涵盖网页、学术论文、法律文档、代码仓库及领域特定文本。
子集详情与规模
- 阿拉伯语: 初始包含 55 billion 原生 tokens,并通过来自英语维基百科和 Books3 的 18 billion 机器翻译 tokens 进行增强。合并后的集合以 1.6 倍比例进行过采样,最终产出 116 billion tokens。
- 英语: 包含从 The Pile 采样的 232 billion tokens,其中 46 billion 来自 GitHub 子集。核心组成部分包括 Pile-CC、Books3、ArXiv、PubMed、Wikipedia、FreeLaw、Project Gutenberg 以及 YouTube 字幕。
- 指令微调: 包含按语言划分的 1000 万条 prompt-response pairs(提示-回复对),其中英语 600 万条,阿拉伯语 400 万条。英语子集包含来自 Super-NaturalInstructions、P3、xP3、Natural Questions 以及各种聊天机器人和代码数据集的精选样本。阿拉伯语子集包括翻译的英语指令、原生命名实体识别任务以及区域特定的问答对。
训练使用与混合比例
- 预训练混合比例固定为阿拉伯语、英语和代码的 1:2:0.4,该配置是通过对较小模型进行大量消融实验确定的。
- 作者先在完整的预训练语料库上训练基础模型,随后在 1000 万对数据集上应用指令微调,以使模型适配对话与助手任务。
- 下游评估依赖于涵盖知识、推理、偏见与安全指标的多项零样本基准测试,采用 LM-Evaluation-Harness 框架以及 MMLU 和 LiteratureQA 等人工翻译的数据集。
处理、过滤与其他细节
- 所有原始输入均经过初始 detokenization 处理以统一文档边界,将每篇文章或网页视为独立单元。
- 作者应用严格的过滤规则,移除极短或极长的文档、阿拉伯语字符密度不足的文段,以及包含超过 100 字符单词的条目,以剔除 URL 与噪声。
- 标准化步骤会剥离不可打印的 Unicode 字符、罕见变音符号、嵌入的 HTML 与 JavaScript 代码,以及高频模板短语。轻量级 n-gram 语言模型进一步过滤噪声序列。
- 通过局部敏感哈希(LSH)进行模糊去重,使英语语料库规模缩减约 20%。阿拉伯语过滤策略有意保持较宽松,以保留稀缺的语言数据。
- 安全对齐流程整合了翻译后的拒绝回答数据集、原生区域特定问答,以及基于 OSACT4 微调的外部分类器,用于在生成前检测并拦截仇恨言论或冒犯性内容。
方法
作者为 Jais 采用基于 transformer 的架构,借鉴了类似 GPT-2 与 LLaMA 的因果仅解码器设计。该架构构成了模型生成能力的基础,其优化源自最新进展与实证研究。模型框架由一系列关键组件构建而成,旨在优化整体性能,尤其在多语言与指令类任务中表现突出。
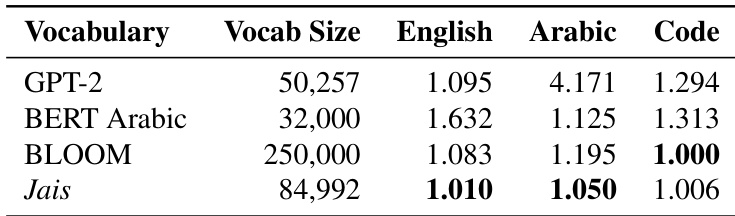
Jais tokenizer 作为关键组件,是一款基于英语与阿拉伯语平衡语料库,使用字节对编码(BPE)训练而成的自定义子词 tokenizer。该设计解决了 GPT-2 tokenizer 常见的过度切分问题,尤其针对阿拉伯语词汇,从而提升了跨语言对齐效果并降低了计算开销。该 tokenizer 的高 fertility score 证明了其有效性,表明尽管词表规模较小,其在多种语言类型上均表现强劲。 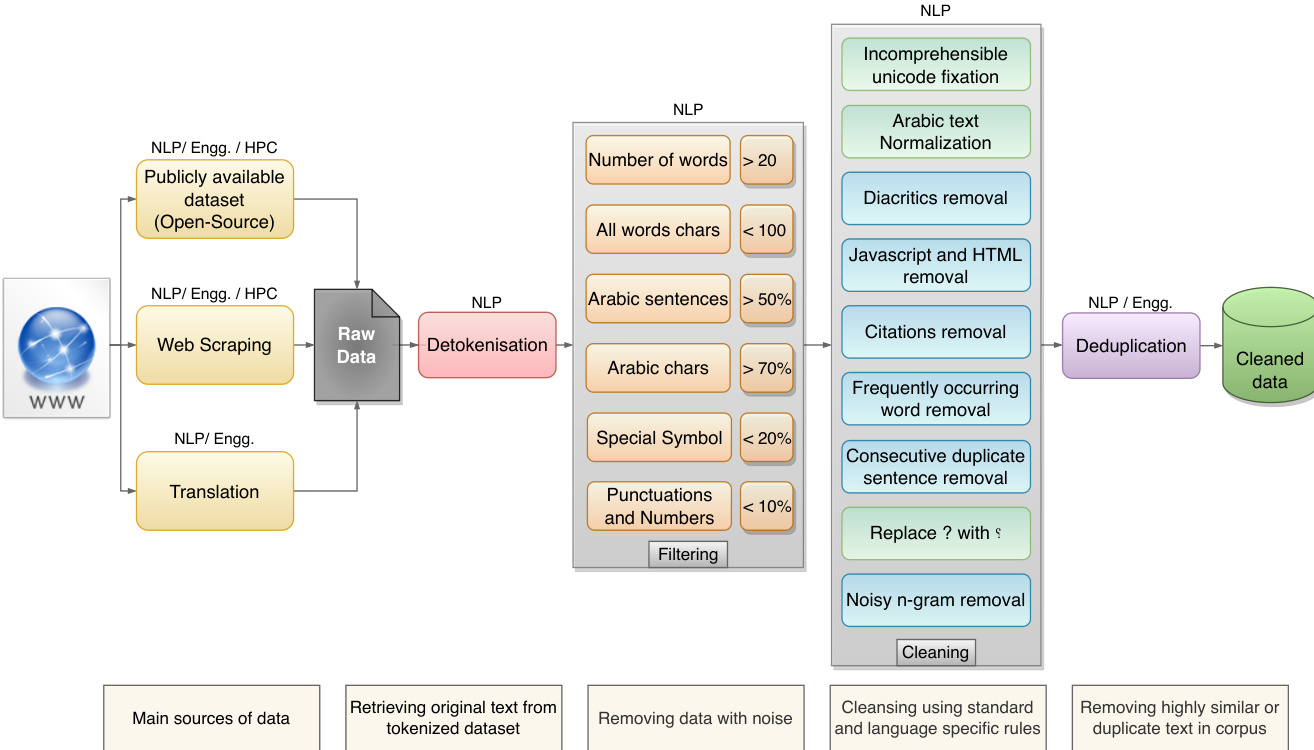
位置信息通过 Attention with Linear Biases (ALiBi) 引入,该方法根据 query 与 key 位置间的距离对 attention scores 施加线性惩罚。此方法支持向更长上下文高效外推,克服了传统可学习或正弦位置编码在序列延长时性能下降的局限。 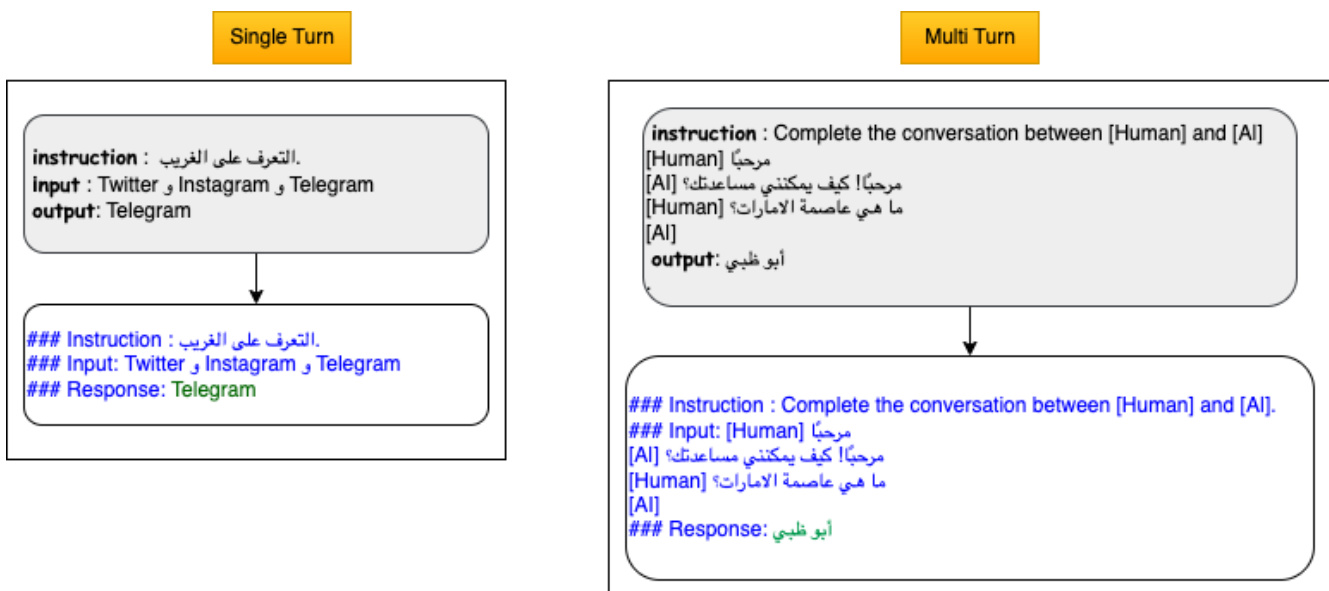
在每个 transformer block 内部,采用 SwiGLU 激活函数,结合了 Swish 与门控线性单元(GLU)的优势。该激活函数在提升模型性能的同时有效管理计算成本;为在相对于 GeLU 时保持一致的 FLOP 预算,前馈网络的 filter size 被调整为 38×dmodel,而非标准的 4×dmodel。模型超参数采用最大更新参数化(maximal update parametrization, μP)进行优化,使得 40M 参数模型的最优 batch size 与 learning rate 可直接迁移至 13B 参数模型,从而简化超参数搜索流程。
针对指令微调,模型通过在指令-回复对数据集上进行训练,适配对话式交互。每个样本均按特定模板构建,包含特殊标记以区分人类输入与模型预期回复,同时屏蔽 prompt tokens 的 loss,确保模型专注于生成回复。该结构支持单轮与多轮对话格式,具体见模板设计。指令微调变体 Jais-chat 进一步加入了安全措施,包括使用系统提示词引导模型负责任地行为,以及基于关键词的正则表达式过滤机制,用于检测并拦截潜在冒犯性内容。
实验
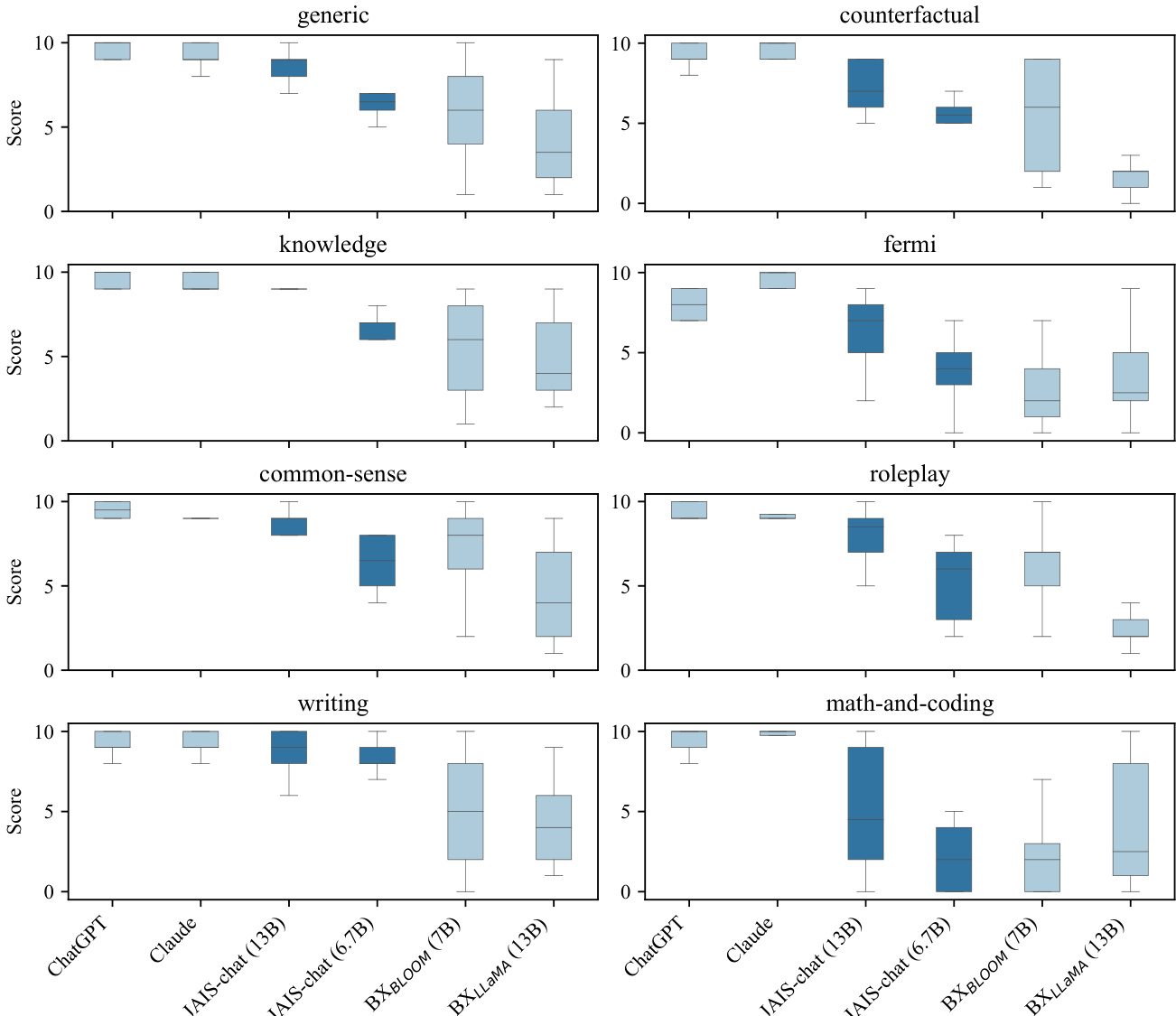
针对不同模型容量与阿拉伯语-英语数据比例的初步训练实验验证了跨语言迁移对大型架构的显著益处,使用混合数据集的中规模模型表现优于规模大得多的纯阿拉伯语模型。随后的生成评估利用自动化成对比较,将指令微调变体与领先的闭源及开源基线模型在阿拉伯语 prompt 上进行对比。结果表明,优化后的模型在文本生成方面极具竞争力,尤其在常识、知识与写作任务中表现突出,同时在复杂推理与代码任务中呈现预期内的局限。最终,这些发现证实,策略性的数据混合与定向微调使区域聚焦型系统能够交付与规模大得多的闭源模型相媲美的稳健性能。
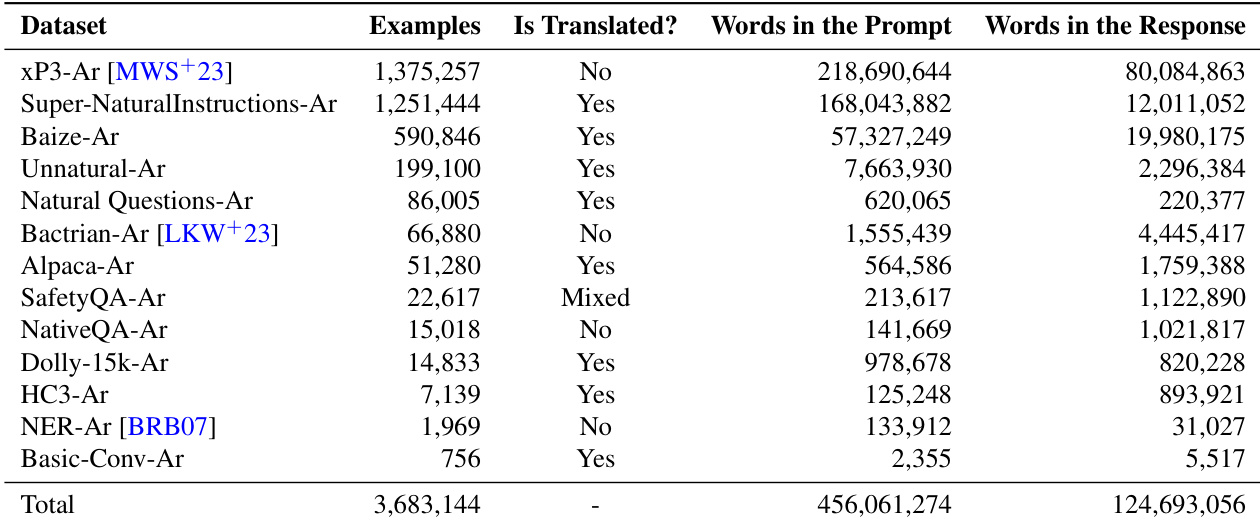
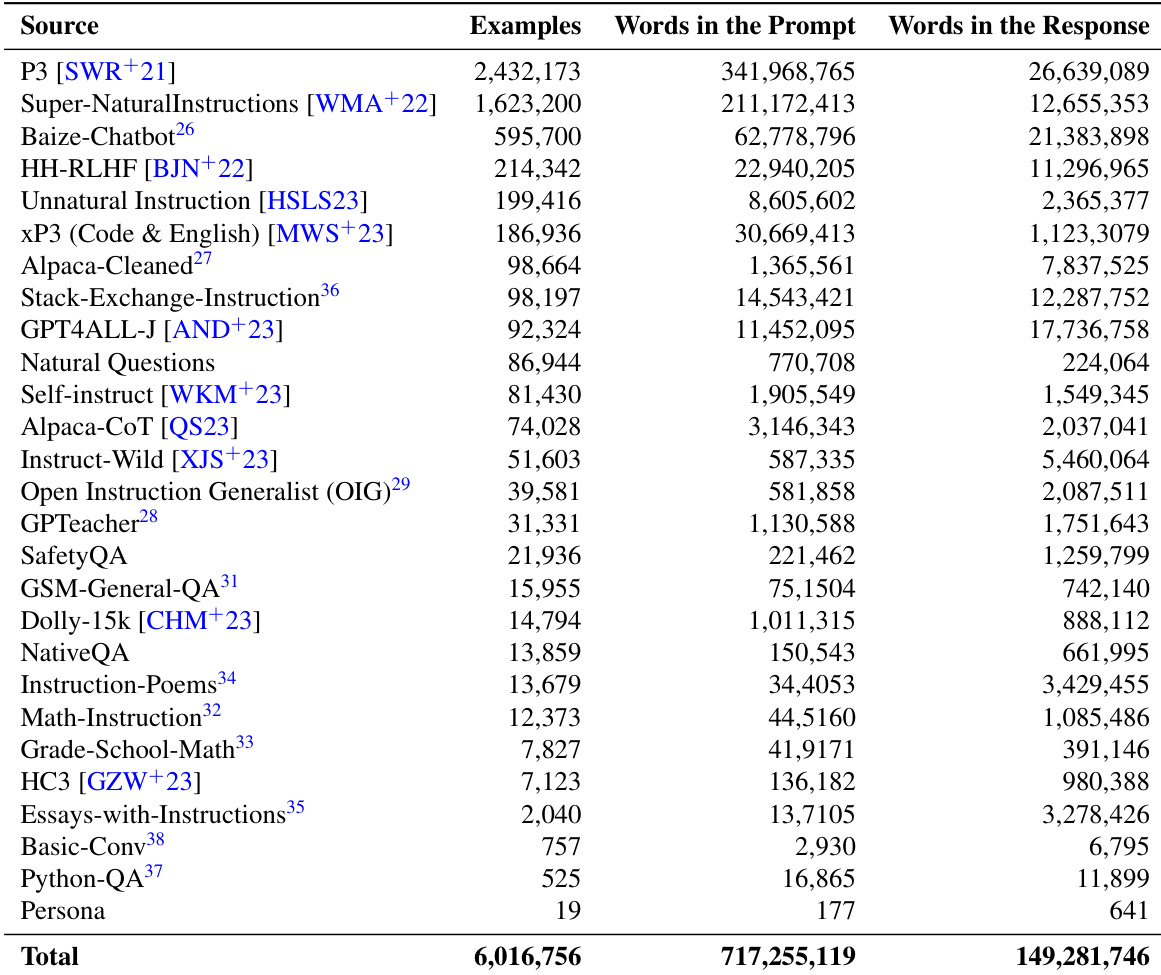
作者展示了下表,总结了用于评估的数据集,详细列出了样本数量、内容是否经过翻译以及 prompt 与回复中的词数。数据集在规模与来源上各不相同,部分为阿拉伯语专用,部分为多语言,下表突出了翻译状态与词数使用等数据特征的差异。表中的数据集包含阿拉伯语专用与多语言数据集的混合,规模与翻译状态各异。部分数据集规模庞大,样本超过 100 万条,而其他数据集规模较小,仅含数千条或少于该数量。prompt 与回复中的词数在不同数据集间差异显著,部分数据集在这两个类别中均具有极高的词数统计。
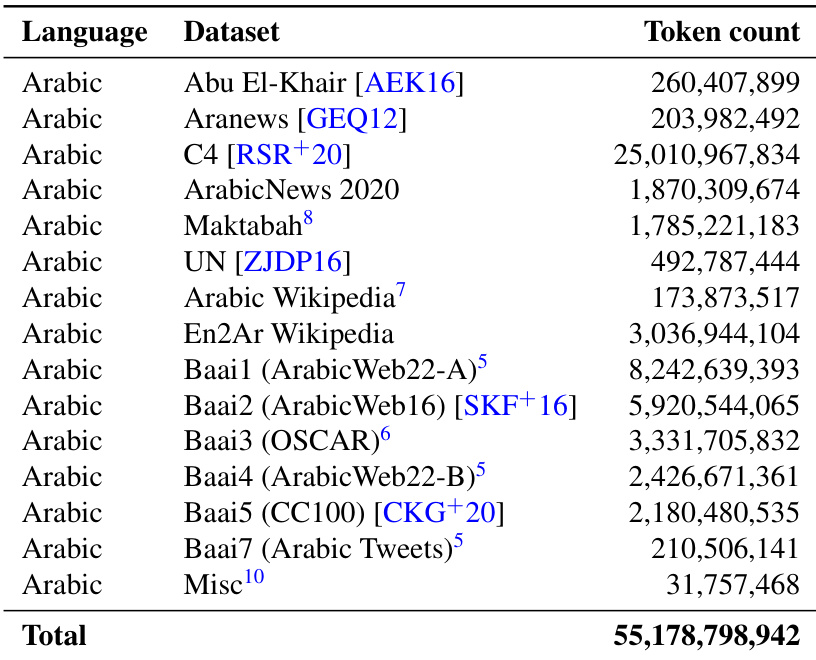
作者展示了下表,详细说明了用于 Jais 模型的阿拉伯语训练数据构成,按语言与 tokens 数量列出了多个数据集。数据来源于新闻、网页文本与社交媒体等多种渠道,总 tokens 数量显著由单一大型数据集主导。结果表明,对于较大规模的模型,引入英语数据可提升阿拉伯语任务性能,而对于较小规模模型,则会产生负面影响。阿拉伯语模型训练数据由新闻、网页与社交媒体等多个来源组成,其中单个数据集贡献了绝大部分 tokens。对于大模型,加入英语数据能提升其在阿拉伯语任务上的表现,但该趋势在小模型中相反。模型在阿拉伯语任务上的性能显著受模型规模与训练数据混合比例的影响,大模型展现出更优的跨语言迁移能力。
作者评估了 Jais-chat 模型在各类阿拉伯语文本生成任务中与多款开源及闭源模型的性能对比。结果显示,Jais-chat 在部分领域具备竞争力,尤其在写作与常识任务中表现良好,但在数学与代码等重度推理类别中不及大型模型。评估强调,模型规模与指令微调对性能影响显著,Jais-chat 尽管规模小于顶尖模型,仍在特定领域表现强劲。Jais-chat 在写作与常识任务中与大型模型表现相当,得分接近领先模型。在数学与代码等重度推理类别中,Jais-chat 不及大型模型,得分明显较低。像 Jais-chat 这样的指令微调模型在大多数任务类别中均优于非指令微调模型。
{"summary": "作者展示了下表,总结了用于训练与评估的数据来源,详细列出了各数据集中 prompt 与回复的样本数量及词数。下表突出了数据的规模与多样性,部分来源提供的样本与词数显著多于其他来源,尤其在指令遵循与通用语言任务背景下。", "highlights": ["下表列出了用于训练与评估的多个数据集,其 prompt 与回复的样本数量及词数各不相同。", "部分数据集(如 Super-NaturalInstructions 与 HH-RLHF)贡献了大量样本与词数,表明其在训练过程中发挥重要作用。", "所有数据集的总计数在样本与词数方面均显示显著贡献,反映出全面且多样化的数据收集工作。"]}
作者对比了 Jais 与其他语言模型(包括 GPT-2 与 BLOOM)在英语、阿拉伯语及代码任务上的词表规模与性能指标。结果表明,Jais 在保持相对较小词表规模的同时,在英语与阿拉伯语任务上均取得极具竞争力的性能。该模型在阿拉伯语任务中表现强劲,特定领域的得分接近甚至超越大型模型。尽管词表规模小于 BLOOM 等模型,Jais 在英语与阿拉伯语任务上仍保持竞争力。在阿拉伯语任务中,Jais 的表现优于 GPT-2 与 BERT Arabic,彰显出强大的阿拉伯语语言建模能力。该模型在英语、阿拉伯语与代码任务上均展现均衡性能,凸显了其在多语言与代码相关应用中的广泛适用性。
实验通过将 Jais 与 Jais-chat 模型与多样化的阿拉伯语及多语言数据集进行基准测试,验证了训练数据构成、模型规模与指令微调的影响。分析表明,大型架构从引入英语数据中获得显著的阿拉伯语性能提升,而小型模型受相同混合数据拖累,强调了需根据规模进行数据筛选的必要性。对比评估进一步揭示,指令微调模型在写作与常识生成方面表现优异,但在复杂推理与代码领域仍不及大型系统。此外,研究证实 Jais 凭借显著紧凑的词表即能提供具备竞争力的多语言与代码能力,证明高效率无需依赖庞大的参数量。