Command Palette
Search for a command to run...
指令微调大语言模型在临床与生物医学任务中的零样本与小样本研究
指令微调大语言模型在临床与生物医学任务中的零样本与小样本研究
Yanis Labrak Mickael Rouvier Richard Dufour
大型语言模型,提示编程和少样本任务
摘要
大型语言模型(LLM)的近期出现推动了自然语言处理(NLP)领域的显著进步。尽管这些新模型在各种任务中表现出卓越的性能,但其在可处理任务的多样性以及应用领域方面的应用和潜力仍未得到充分探索。在此背景下,我们在13个真实的英语临床和生物医学NLP任务上评估了四种最先进的指令微调LLM(ChatGPT、Flan-T5 UL2、Tk-Instruct 和 Alpaca),包括命名实体识别(NER)、问答(QA)、关系抽取(RE)等。我们的总体结果表明,这些被评估的LLM在大多数任务的零样本和小样本场景中达到了最先进模型的性能水平,尤其在QA任务中表现出色,尽管它们此前从未接触过这些任务的示例。然而,我们也观察到,分类和关系抽取任务的表现低于专门为医学领域设计的特定训练模型(如PubMedBERT)所能达到的性能。最后,我们注意到,没有任何一个LLM在所有 studied 任务中均优于其他模型,某些模型在某些任务上表现得更为合适。
一句话总结
对四种经过指令微调的大语言模型(ChatGPT、Flan-T5 UL2、Tk-Instruct 和 Alpaca)在十三个英文临床与生物医学 NLP 任务上的评估表明,尽管这些模型在问答任务中达到了接近最先进的零样本与少样本性能,但在分类和关系抽取任务上仍逊于 PubMedBERT 等领域专用架构,且结果表明没有任何单一模型能在所有评估任务中全面领先。
核心贡献
- 本研究在零样本与少样本条件下,对四种指令微调大语言模型(ChatGPT、Flan-T5 UL2、Tk-Instruct 和 Alpaca)在十三个临床与生物医学自然语言处理任务上的表现进行了评估。
- 提出了一种新颖的递归思维链(Recursive Chain-of-Thought, RCoT)提示策略,通过逐步丰富输入指令,实现跨不同模型架构的命名实体识别。
- 实证分析表明,通用模型在大多数生物医学任务中取得了具有竞争力的性能,尽管在分类和关系抽取任务上仍不及 PubMedBERT 等领域专用架构,但展现出了明显的任务特定能力。
引言
医疗领域日益依赖自然语言处理来分析复杂的临床记录,但由于数据集稀缺且敏感,以及专家标注成本高昂,将先进模型部署于医疗场景仍面临挑战。传统的掩码语言模型需要大量标注数据,且在跨任务泛化方面表现不佳;而此前针对医疗领域大语言模型的评估往往局限于狭窄的任务集合与非标准化的自动指标。作者通过在十三个真实世界的临床与生物医学任务上对四种指令微调模型进行基准测试,填补了上述空白。研究使用标准准确率与 F1 分数,将零样本与少样本能力与微调后的 PubMedBERT 基线模型进行对比。此外,作者引入了递归思维链提示技术,这是一种新颖的方法,通过逐步丰富提示内容来模拟人类推理过程,从而支持跨不同大语言模型架构的命名实体识别。
数据集
数据集构成与来源
- 作者使用了五个科学与医疗 NLP 数据集:MedMCQA、GAD、SciTail、HoC 和 DEFT-2020。这些来源涵盖了多项选择题问答、关系抽取、自然语言推理、癌症特征分类以及语义文本相似度。
各子集关键细节
- MedMCQA 提供带有四个字母选项的科学问题,要求以单字符作答。
- GAD 包含用于基因-疾病关系抽取的语句,标注为正相关或负相关。
- SciTail 提供用于自然语言推理的前提-假设对,标注为蕴含(entails)或中立(neutral)。
- HoC 文档标注有一个或多个预定义的癌症特征,或标记为无。
- DEFT-2020 任务一作为语义文本相似度基准。
- 提供的摘录未指定具体的数据集规模或训练混合比例。
数据使用与处理
- 作者将所有子集转换为适用于 ChatGPT 和 Flan-T5 UL2 的结构化指令提示。
- 每个任务均采用零样本与五样本配置进行评估。
- 原始类别标签通过试错法进行手动优化,以符合模型预期,例如将 entailment 改为 entails 以获取可量化的性能提升。
- 所有提示均强制执行严格的输出约束,以禁止提供解释并确保格式合规。
元数据与额外处理
- 作者向 GAD 输入中注入标准化的实体占位符(如 @GENE和@DISEASE),以简化关系抽取流程。
- 提供的文本中未详细说明任何裁剪策略或复杂的元数据构建流程。
方法
作者在推理阶段采用少样本学习框架,在此框架下,仅提供少量任务示例作为条件,且不更新模型权重。这些示例通常由指令、上下文和期望的补全内容组成,例如自然语言推理(NLI)任务中的前提、假设及对应标签。少样本技术涉及向模型展示 k 个上下文与补全示例,随后提供一个最终的上下文示例,模型需据此生成补全内容。k 的取值通常在 3 到 100 之间,受限于模型的上下文窗口大小。例如,Flan-UL2 最多支持 2,048 个 token。
为在随机选取示例的基础上进一步提升少样本性能,研究引入了一种基于检索的模块,该模块采用 Sentence-Transformers(Reimers 和 Gurevych, 2019)。该模块从训练集中检索语义最相似的 k 个示例。流程首先使用固定的 PubMedBERT(Gu et al., 2021)模型将训练集中的每个指令提示嵌入到向量空间中。对于给定的测试实例,查询向量会与所有训练示例进行余弦距离计算,并选取距离最近的 top k 个示例。在实现中,k 设置为 5。
输入指令提示由三个部分拼接而成:指定任务、描述数据并概述预期模型行为的指令;包含相关信息的输入参数;以及用于引导生成的输出空间约束。这种结构化格式提升了模型在各类任务上的性能。
针对命名实体识别(NER),评估了两种推理方法。第一种改编自 Ye 等人(2023)的研究,仅适用于 ChatGPT,采用单词由双竖线分隔、标签由单竖线分隔的格式。第二种方法命名为递归思维链(RCoT),具有更强的通用性,可适用于所有测试过的生成式模型。RCoT 扩展了思维链(CoT)框架(Wei et al., 2022b),并基于 Wang 等人(2022b)的工作。该方法通过迭代处理序列中的每个 token,将当前预测状态作为输入,以生成下一个 token 的标签。这确保了每个 token 都能获得标签,并防止生成过程中出现遗漏。然而,由于该方法的时间复杂度为 ON(其中 N 为序列中的 token 数量),相较于 ChatGPT 专用方法的 O1 复杂度,其计算成本显著更高。
RCoT 提示格式的示例包含详细指令、约束条件、一组五个少样本示例,随后是当前句子以及针对特定 token 标签的查询。该方法在保持与模型推理过程一致的同时,确保了实体标注的精确性。
实验
实验设置使用零样本与少样本提示协议,在十三个临床与自然语言处理任务上将四种指令微调大语言模型与生物医学基线模型进行对比评估。该评估验证了通用模型在专业医疗领域的泛化能力,结果表明,尽管少样本学习能有效缓解幻觉问题并提升整体准确率,但模型在分类和关系抽取任务上仍落后于任务专用架构。因此,研究结论指出,问答是目前大语言模型最可靠的应用场景;由于没有任何单一模型能在所有任务中全面领先,实践者必须根据具体的临床需求仔细匹配模型能力。
作者在多项临床与生物医学任务上评估了多种大语言模型,涵盖分类、问答、关系抽取及命名实体识别。结果表明,尽管生成式模型在问答任务上表现良好,但在分类和关系抽取任务上不及领域专用模型,且性能在不同任务与模型间存在显著差异。在零样本设置下,生成式模型在问答任务上的表现优于领域专用模型。分类与关系抽取任务中,生成式模型的表现弱于专用模型。各模型性能表现各异,部分模型在特定任务中表现突出,而在其他任务中则相对较弱。
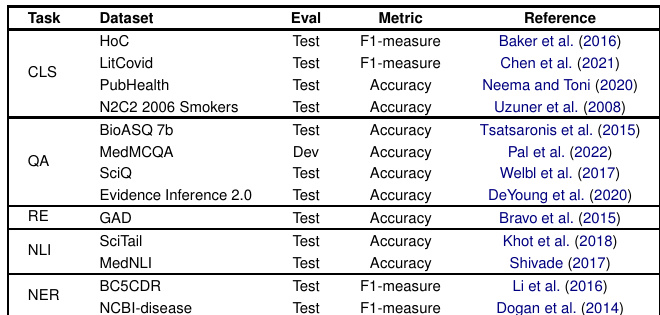
作者在多项临床与生物医学任务上评估了多种大语言模型,将其在零样本与少样本设置下的性能与生物医学专用模型进行对比。结果显示,生成式模型在问答任务上表现良好,尤其在少样本场景下;但在分类和关系抽取任务上,其性能仍不及专用模型。生成式模型在问答任务上取得了强劲表现,尤其在少样本设置下,部分情况下甚至超越了专用模型。分类与关系抽取任务中,生成式模型的性能始终低于生物医学专用基线模型。Alpaca 在所有任务的少样本场景中均展现出显著提升,表明其对新指令具有高度适应性。
本研究在临床与生物医学任务(包括分类、问答和关系抽取)上评估了多种大语言模型,采用零样本与少样本设置,并与领域专用基线进行对比。这些实验验证了生成式架构与专用架构在不同任务类型和提示条件下的相对有效性。定性来看,生成式模型在问答任务中展现出强大能力,尤其是在利用少样本示例时;但在分类和关系抽取任务上,其表现始终落后于专用模型。总体而言,模型性能高度依赖具体任务,部分架构(如 Alpaca)在少样本场景中表现出显著的适应性与性能提升。