Command Palette
Search for a command to run...
一键部署 Chatterbox TTS
摘要
一句话总结
作者通过比较六个 SSL 模型在三个内部层上的表现,将朗读语音的 MOS 预测框架扩展至非脚本化语句,并在两个独立的自发语音语料库上测试这两种方法,全面评估了自监督语音表示在自发语音合成与质量预测中的应用,从而确立了适用于自发语音合成及 MOS 预测的普适性规律。
核心贡献
- 本研究系统评估了六个自监督语音学习模型在三个内部层上的表现,旨在为两阶段自发语音合成识别最优的中间声学表示。
- 该研究对现有的基于 SSL 的框架进行了适配,以自动预测合成自发语音的均值意见得分(MOS),将原本针对朗读语音的质量评估方法扩展至新领域。
- 基于两个独立自发语料库的实验确立了普适性趋势,量化了特定模型架构与层选择对合成保真度及自动化质量预测的直接影响。
引言
自监督学习模型在海量无标注数据集上训练,能够生成鲁棒的语音表示,为语音合成与质量评估带来显著优势。此类特征使语音合成系统能够处理混合质量的音频并建模复杂的韵律模式,这对于生成包含不流畅发音和呼吸声的自然自发语音至关重要,而这些特征正是传统方法难以应对的。既往研究主要集中于朗读语音,未能识别适用于自发合成的最优 SSL 架构或内部层,导致该领域的模型选择机制存在关键认知空白。此外,尽管 SSL 模型在预测朗读语音的 MOS 方面展现出潜力,但其用于评估合成自发语音质量的有效性尚未得到研究。作者通过系统比较六个 SSL 模型在三个内部层上的表现以优化自发语音合成性能,并将基于 SSL 的框架扩展至自发合成的 MOS 预测,从而填补了上述空白。基于两个自发语料库的实验提供了关于利用 SSL 表示构建更拟人化对话语音系统的普适性见解。
数据集
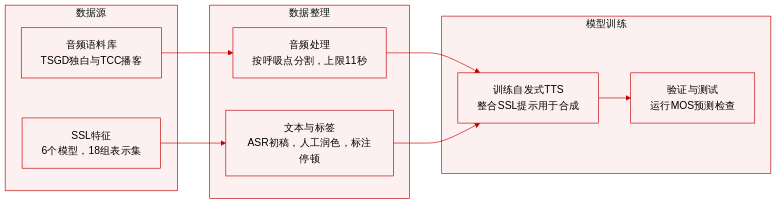
-
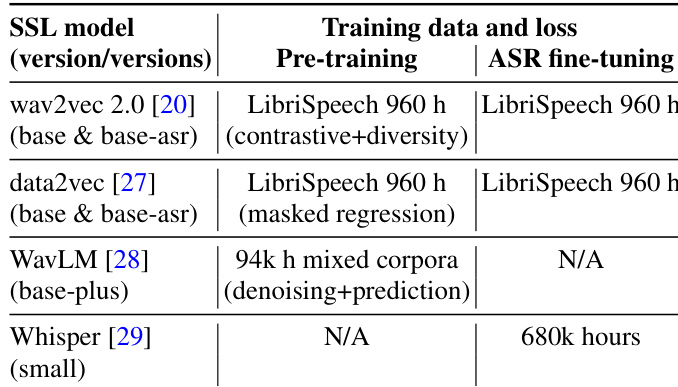
数据集构成与来源 作者使用两个自发语音语料库和六个语音自监督学习(SSL)模型构建数据集。音频数据来源于 Trinity Speech-Gesture Dataset (TSGD) 第一部分和公共领域的 ThinkComputers Corpus (TCC)。模型特征取自四个预训练的 SSL 架构及两个官方 ASR 微调变体。
-
子集详情
- TSGD:包含 25 段独白,平均每段 10.6 分钟,由一位爱尔兰英语男性演讲者向静默但视觉可见的听众发表即兴、口语化演讲。
- TCC:约 9 小时的播客音频,由两位美国英语男性演讲者围绕准备的大纲即兴讨论科技话题。
- SSL 表示:所有六个模型共享相同的规格(765 维输出,12 层 Transformer,50 Hz 帧率)。特征从第 6、9 和 12 层提取以捕捉韵律线索,共生成 18 组不同的表示集。
-
处理与裁剪策略
- 两个语料库均在自然呼吸事件处进行分割,并以重叠方式重新组合,生成严格限制在 11 秒以内的语句。
- 转录文本通过自动语音识别生成并经人工校对。填充停顿、笑声和话语标记均按正字法写出。呼吸事件用分号标注,标准停顿用逗号标注,舌音等非词汇声音则被省略。
-
在模型中的使用
- 处理后的音频与 SSL 特征用于训练自发语音合成系统,并评估均值意见得分(MOS)预测任务。
- SSL 表示被直接集成至合成管线中,依赖中间层输出以实现最优的韵律控制。
- 由于在自发语音合成设置中已证实性能较差,梅尔频谱图基线被排除在所有对比之外。
方法
作者采用两阶段框架进行语音合成,其中第一阶段从输入文本生成声学特征,第二阶段将这些特征转换为高质量波形。如图所示,系统首先采用阶段 1 声学模型(具体为 FastPitch 1.1),该模型处理文本输入以生成梅尔频谱图。该模型采用带自动对齐的并行方式训练,无需显式对齐标注即可高效学习文本到声学的映射关系。阶段 1 模型首先在朗读语音语料库 LJ Speech 上进行 200 个轮次的预训练,随后利用迁移学习在自发语音语料库上进行微调,从而提升其向结构化程度较低语音数据泛化的能力。
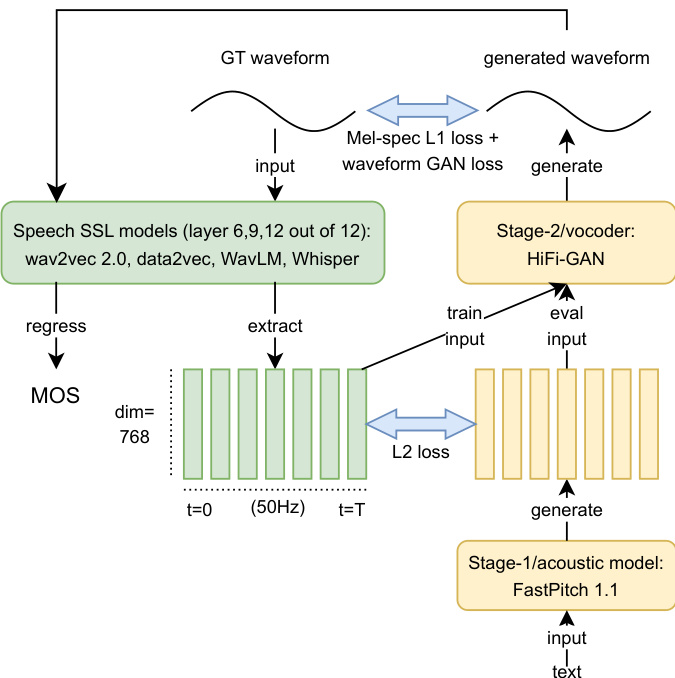
生成梅尔频谱图后,阶段 2 声码器 HiFi-GAN 将这些声学特征合成为最终波形。声码器训练批次大小为 160,使用 0.5 秒的随机音频片段,并在原始 22 kHz 采样率下运行。训练期间,模型同时最小化梅尔频谱 L1 损失与波形 GAN 损失,以确保感知质量及对真实波形的保真度。阶段 2 模型在 36 种配置下训练 8 万步,对应从两个自发语料库导出的 18 种不同语音 SSL 表示。
此外,作者集成了一套 MOS 预测系统以评估合成语音质量。该系统基于 wav2vec 2.0 基础模型,配备均值池化头与线性投影层,用于预测标量 MOS 值。该架构改编自既往研究,作者在保持固定模型结构的前提下,探索了多种权重初始化方式与训练数据划分方案,以评估其在自发语音合成上的性能。MOS 预测在阶段 1 模型的输出端执行,提取语音 SSL 特征并进行回归以预测 MOS 得分。
实验
本研究在双阶段语音合成管线中评估了六个自监督语音模型在多个网络层上的表现,通过声码器重建测试验证声学保真度,通过主观听音实验评估感知质量,并通过自动化质量预测检验泛化能力。实验表明,中间层表示(尤其是 ASR 微调模型的第 9 层)始终能产生最高的感知音频质量,而更深层的表示则会降低合成性能。关键在于,主观质量与声码器重建误差之间不存在相关性,这凸显了表示的声学丰富度与其从文本可预测性之间的根本权衡。最后,自动化 MOS 预测在零样本设置中被证明无效,表明针对自发语音数据进行微调对于可靠的质量评估至关重要。
作者在双阶段语音合成系统中对比了多种自监督语音表示,通过声码器误差与主观听音测试评估其性能。结果表明,中间层(尤其是第 9 层)比更深或更浅的层能产生更好的语音合成质量;ASR 微调提升了性能,尽管声码器误差有所增加,这表明声学信息与预测精度之间存在权衡。性能最佳的模型结合了 data2vec、ASR 微调与第 9 层表示,在未取得最低声码化误差的情况下仍实现了较高的主观质量。在不同模型与语料库中,SSL 模型的第 9 层在主观语音合成质量上始终优于第 6 层和第 12 层。ASR 微调提升了语音合成质量但增加了声码器误差,表明声学保真度与文本到表示预测精度之间存在权衡。Whisper 取得了最低的声码器误差,但在语音合成质量上表现欠佳,这表明高声学信息含量并不必然转化为更优的感知语音质量。
作者评估了 SSL 表示在自发语音合成与 MOS 预测中的表现,分析了不同模型、层及微调策略下的性能。结果表明,第 9 层表示通常比更深或更浅的层能产生更好的主观语音合成质量;微调提升了 MOS 预测精度,尽管零样本性能依然较差。研究强调了表示中的声学信息与其文本可预测性之间的权衡。语音合成质量与声码化误差的趋势并不一致,表明较低的误差并不必然带来更好的感知质量。在多个 SSL 模型中,第 9 层表示始终在主观语音合成质量上优于更深或更浅的层。微调 SSL 模型提升了 MOS 预测性能,微调后的 wav2vec2.0-base-asr 展现了具有竞争力的结果。声码化误差与感知语音合成质量之间不存在相关性,表明声学保真度与文本到语音可预测性之间存在权衡。
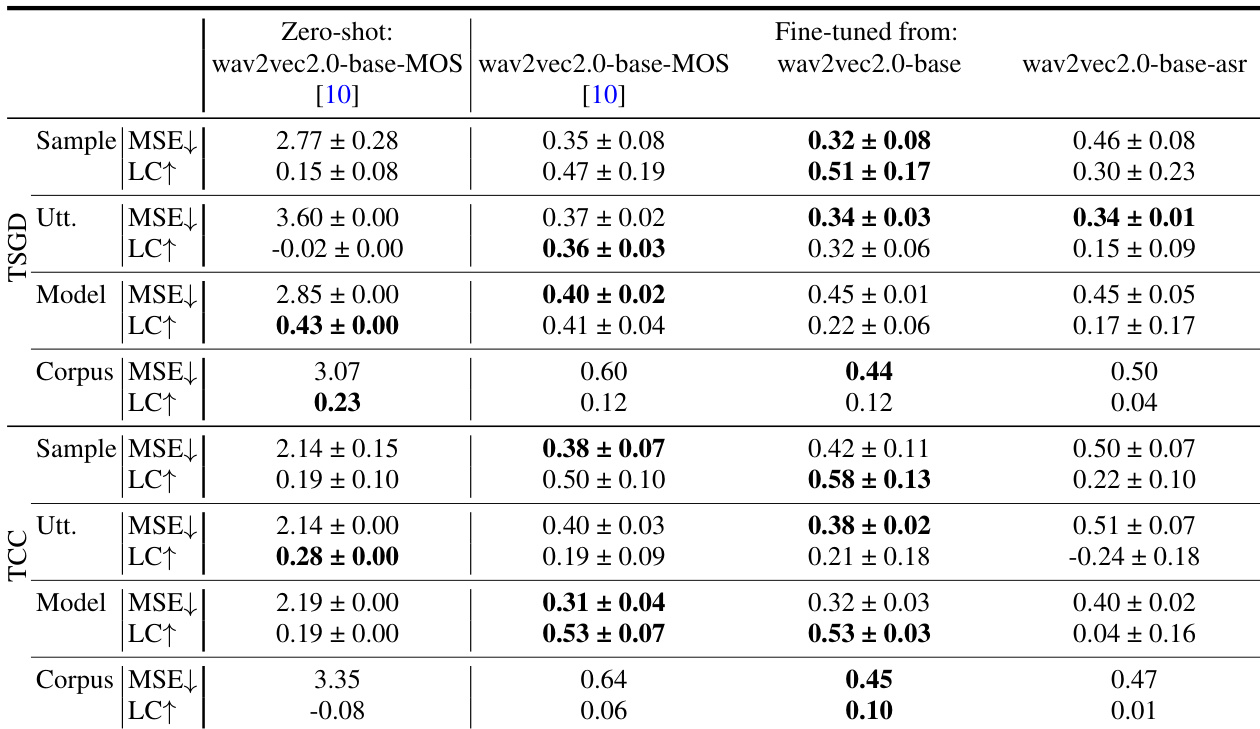
作者在双阶段语音合成系统中评估了不同层与模型下的自监督语音表示,分析了主观质量与声码器误差。结果表明,中间层(尤其是第 9 层)比更深或更浅的层能产生更好的主观质量;ASR 微调提升了性能,尽管声码器误差较高,这表明声学保真度与文本可预测性之间存在权衡。性能最佳的系统结合了 data2vec 与第 9 层的 ASR 微调,在两个语料库上均实现了较高的主观质量。在多个 SSL 模型中,第 9 层在主观语音合成质量上始终优于第 6 层和第 12 层。ASR 微调提升了主观语音合成质量但增加了声码器误差,表明声学信息与文本可预测性之间存在权衡。性能最佳的系统结合了 data2vec 与第 9 层的 ASR 微调,在两个语料库上均实现了较高的主观质量。
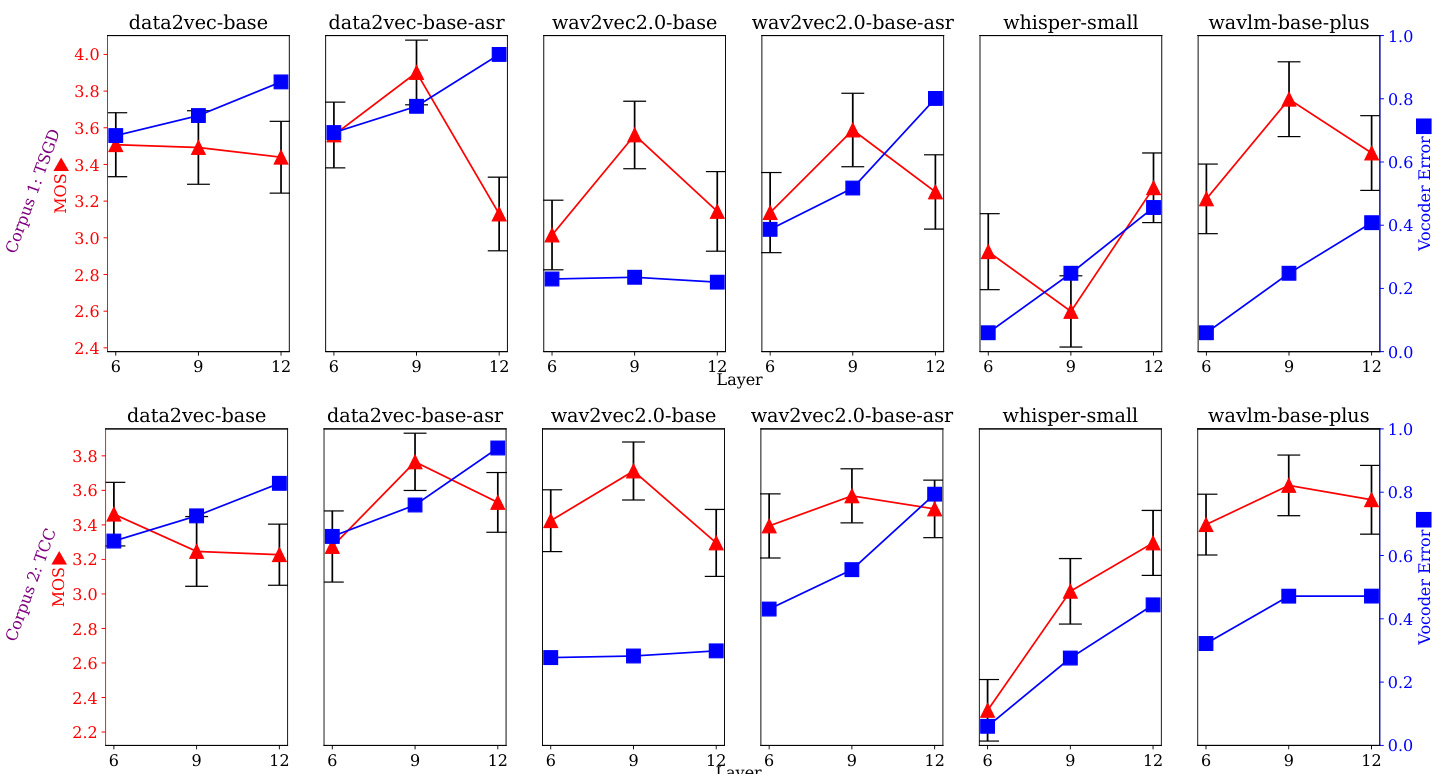
实验通过主观听音测试与声码器误差指标,验证了网络层深度与自动语音识别微调在双阶段语音合成系统中对多种自监督语音表示的影响。结果一致表明,中间层能提供更优的感知语音质量,而微调在增加重建误差的同时提升了人工评分,凸显了声学保真度与文本可预测性之间的根本权衡。这些发现表明,客观误差指标并不能可靠地反映听者感知,证实了精心挑选的中间表示结合针对性微调能够生成最自然的合成语音。