Command Palette
Search for a command to run...
深度任意多项式混沌神经网络:或深度人工神经网络如何从数据驱动的同构混沌理论中受益
深度任意多项式混沌神经网络:或深度人工神经网络如何从数据驱动的同构混沌理论中受益
Sergey Oladyshkin Timothy Praditia Ilja Kröker Farid Mohammadi Wolfgang Nowak Sebastian Otte
从探索性数据分析到深度神经网络 [完整教程]
摘要
人工智能和机器学习已广泛应用于数学计算、物理建模、计算科学、通信科学和随机分析等多个领域。基于深度人工神经网络(DANN)的方法在当今非常流行。根据学习任务的不同,DANN的确切形式由其多层架构、激活函数以及所谓的损失函数决定。然而,对于大多数基于DANN的深度学习方法而言,神经信号处理的核结构保持不变,其中节点响应被编码为神经活动的线性叠加,而非线性性由激活函数触发。在本文中,我们建议从多项式混沌展开(PCE)中已知的同构混沌理论视角来分析DANN中的神经信号处理。从PCE的角度来看,DANN中每个节点的(线性)响应可以看作是来自前一层的单个神经元的一元多元多项式,即单项式的线性加权和。从这个角度来看,传统的DANN结构隐式地(但错误地)依赖于神经信号的高斯分布。
一句话总结
深度任意多项式混沌神经网络使用数据驱动的多项式展开替代传统的线性激活函数,通过齐次混沌理论对神经信号处理进行建模,直接解决了限制传统深度人工神经网络的隐式高斯假设问题。
核心贡献
- 本文提出深度任意多项式混沌神经网络(DaPC NN),该架构在每个节点处用自适应的数据驱动多元正交多项式基,替代了传统深度网络中的隐式高斯假设。
- 通过齐次混沌理论重构神经信号处理核,该框架能够捕捉高阶的神经元同步交互,并将非线性直接嵌入多项式基中,从而消除了对传统激活函数的依赖。
- 在三个独立测试用例中的评估表明,该模型相对于参考验证数据集具有稳定的收敛性;系统性比较则量化了训练数据量对预测精度的影响,并与标准深度神经网络及任意多项式混沌方法进行了对比。
引言
深度人工神经网络已成为现代机器学习的基石,广泛应用于科学和工程领域,用于将复杂的多维输入映射到输出。然而,标准架构依赖神经元输出的线性加权叠加,随后接以人工选择的激活函数,这通常会引入冗余的信号表示和主观的设计决策。传统多项式混沌展开通过将信号投影到正交多项式基上来消除冗余,提供了一种数学上严谨的替代方案,但其经典形式需要已知输入概率分布,这在纯数据驱动的神经网络训练中通常不可用。为弥补这一差距,作者提出了深度任意多项式混沌神经网络,该网络能够在每个网络层自适应地构建数据驱动的正交多项式基。该方法以高阶加权叠加替代僵化的线性组合与固定激活函数,降低了表示冗余,并为复杂建模任务提供了更稳健、更具理论基础框架。
数据集
-
构成与来源: 作者构建了两个独立的数据集用于基准测试其代理建模方法。第一个数据集是基于一个包含十个取值范围为 -5 到 5 的独立均匀分布输入的非线性解析函数生成的合成数据集。第二个数据集改编自先前文献中的简化二氧化碳注入基准模型,用于模拟多孔介质中具有强非线性冲击波传播的多相流。
-
子集细节与规模: 训练子集的大小固定,以确保实验的透明度,并避免使用主动学习或数据挖掘流程。对于解析函数,训练集包含 100、500 和 1,000 个样本。对于 CO₂ 基准测试,一种采样策略的训练集规模为 100、500 和 1,000,另一种策略则为 27、216 和 1,331。验证子集中,解析函数包含 1,000 个样本,CO₂ 基准测试包含 10,000 个样本。
-
数据使用与处理: 作者使用这些数据集训练自适应多项式混沌、深度自适应神经网络以及深度自适应多项式混沌神经网络。训练数据被严格划分为固定集合,以将模型性能与动态采样效应隔离。验证数据始终基于底层输入分布通过蒙特卡洛采样生成,以评估在注入速率、相对渗透率和地层孔隙度等关键不确定性来源上的预测质量。
-
其他处理策略: 为防止龙格现象和吉布斯效应等数值不稳定性在间断点附近出现,作者采用了专用的点选择策略而非随机采样。训练点通过 Sobol 序列或高斯积分点构建。高斯策略特别将样本位置与多项式阶数对齐以形成完整张量网格,从而优化代理模型的数值积分过程。
方法
所提出的深度任意多项式混沌神经网络(DaPC NN)通过融合多项式混沌展开(PCE)理论的原则,重新设计了传统深度人工神经网络(DANN)的核心架构。根本性的转变在于每一层中神经信号的表示方式。传统 DANN 通过单项式的线性叠加(具体为零阶和一阶项)传播信号,形成线性加权和;而 DaPC NN 采用非线性的高阶多元多项式展开。该展开基于数据驱动的正交基构建,该基根据来自前一层传入神经响应的统计特性为每一层自适应形成。该方法确保了信号的最优且无冗余分解,解决了标准 DANN 中固有的隐式高斯假设及潜在的正交性破坏问题。
网络架构由一系列深层组成,表示为 L=1,…,L,其中每一层 L 包含一组隐藏节点 N=1,…,N(L)。层 L 中节点 N 的响应 R(L,N) 定义为多元正交多项式 Ψi(L) 的加权和,这些多项式是前一层所有节点经激活变换后的响应 A(L)(R(L−1)) 的函数。每个节点的总项数 M(L) 由前一层输入数量 N(L−1) 和期望的非线性阶数 d(L) 决定,遵循全阶截断方案。该公式使网络能够捕捉神经元之间的高阶交互,突破了单一神经元线性叠加的局限。
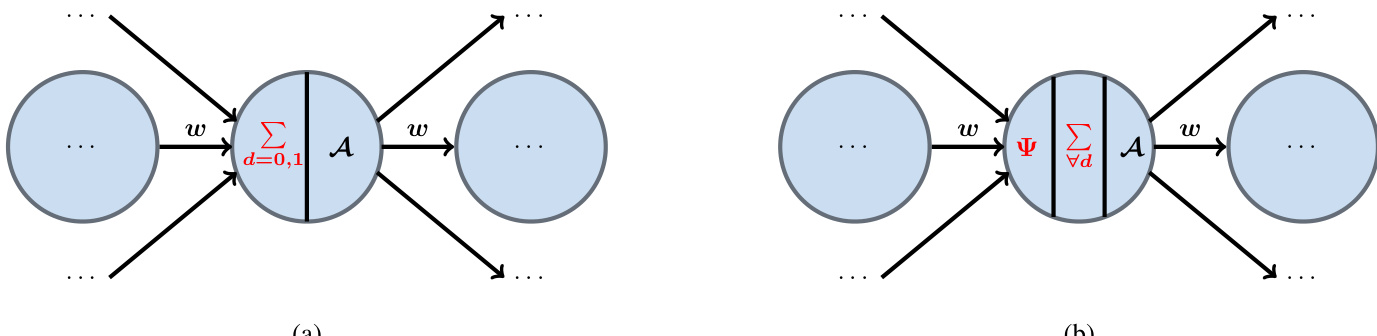
参见框架示意图,该图展示了两款架构的关键差异。图 (a) 描绘了传统 DANN 节点,其中传入信号被求和并通过激活函数 A。图 (b) 展示了 DaPC NN 节点,其中传入信号首先经过数据驱动滤波器处理,以构建该层的正交基 Ψ。随后响应被计算为这些基函数的加权和,权重 w 和阶数 d 决定了非线性程度。该滤波机制是核心创新,确保了正交表示。
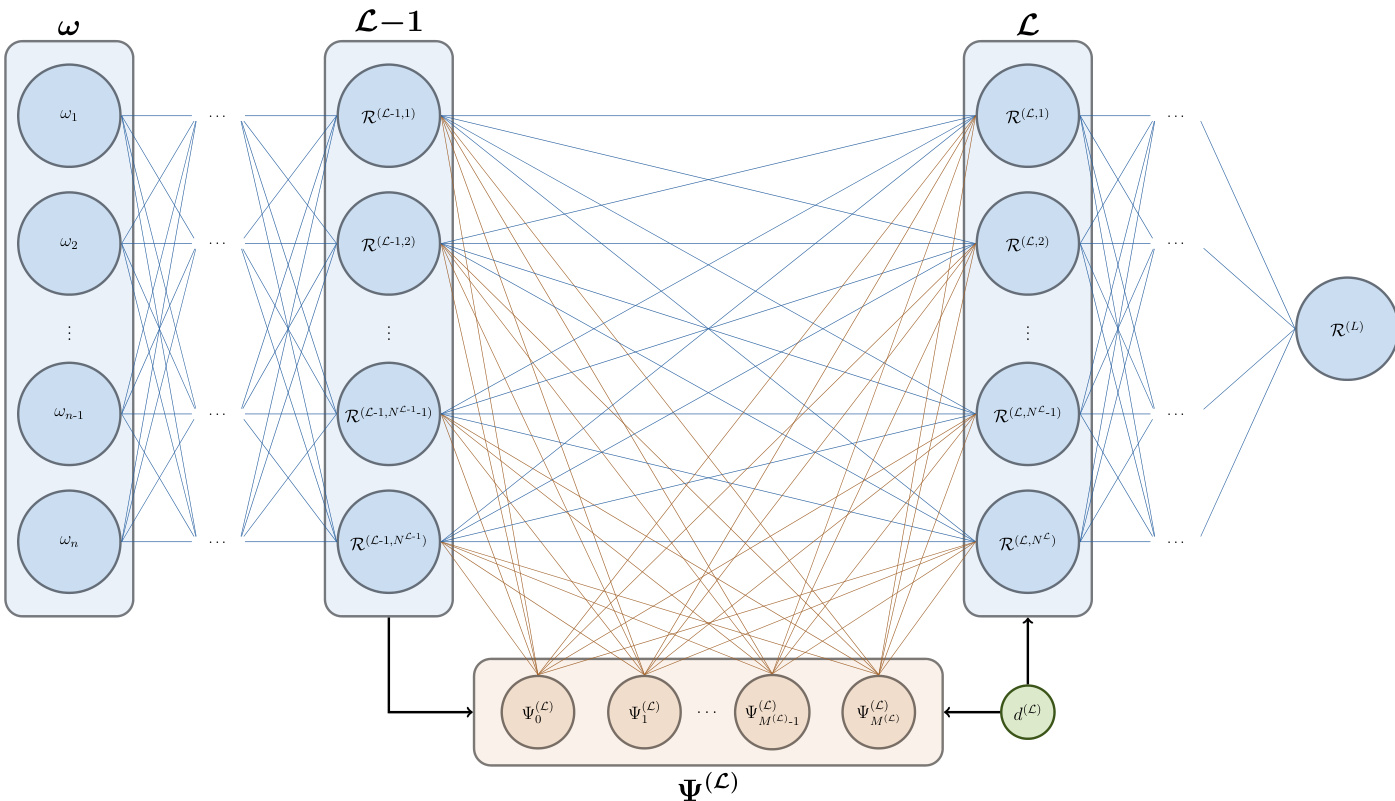
如下所示,整体 DaPC NN 框架包含一个接收原始输入 ω 的输入层 L−1。该层的响应 R(L−1) 被输入到下一层 L。对于每一层,正交基 Ψ(L) 均根据前一层的响应构建。该过程是顺序且数据驱动的,意味着基函数并非固定不变,而是适应网络的内部状态。非线性阶数 d(L) 是一个可配置的超参数,允许用户逐层控制表示的复杂度。激活函数 A(L) 在输入多项式基之前应用于前一层的响应,它是一个可由用户选择的独立组件。该框架具有灵活性,因为正交基与激活函数相互独立,允许结合两者的非线性特性。
DaPC NN 的训练过程设计为与传统 DANN 保持一致。未知权重 wi(L,N) 通过最小化损失函数(通常均方误差 MSE)进行优化,并引入正则化项以防止过拟合。关键在于,正交基 Ψ(L) 并非固定参数,而是在训练过程中隐式构建的。权重通过基于输入分布和隐藏节点响应的数据驱动过程来确定基函数。这意味着正交基在迭代训练过程中会自适应地重新计算。基的构建依赖于任意多项式混沌(aPC)理论,该理论利用输入数据的统计矩来形成一组正交多项式。因此,训练后的权重不仅定义了网络的预测函数,还唯一确定了所有层对应的数据驱动正交基,使 DaPC NN 成为一个自包含的黑盒模型,同时为用户保持了训练过程的简便性。
实验
该评估在三个不同训练数据规模的基准问题上,将所提出的 DaPC NN 与传统 DANN 及 aPC 展开进行对比,以验证其在不同非线性条件下的预测精度、泛化能力及收敛行为。定性来看,DaPC NN 通过有效平衡模型灵活性与从多项式混沌理论继承的结构约束,始终展现出更优的验证性能和抗过拟合鲁棒性。相比之下,传统 DANN 存在严重的过拟合和泛化能力差的问题,而标准 aPC 展开在高度非线性场景中缺乏足够的灵活性,但受益于优化的训练点分布。尽管所有模型因依赖平滑基函数而难以准确捕捉强冲击波传播,但 DaPC NN 成为复杂不确定性量化任务中最可靠且可扩展的方法。
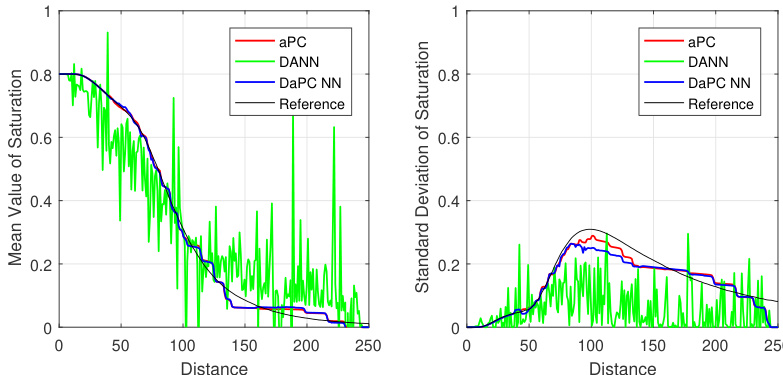
作者对比了 aPC、DANN 和 DaPC NN 模型在涉及冲击波传播的基准问题中预测 CO₂ 饱和度的性能。与 aPC 和 DANN 相比,DaPC NN 展现出更优的预测精度和稳定性,特别是在捕捉不同距离下的饱和度均值和标准差方面。DaPC NN 振荡减小且收敛性更好,表明其在处理问题的非线性和不连续性方面具有增强的鲁棒性。aPC 和 DANN 模型表现出显著的偏差和不稳定性,尤其是在使用 Sobol 序列训练时,凸显了其在当前场景下的局限性。DaPC NN 在预测 CO₂ 饱和度均值和标准差方面优于 aPC 和 DANN,且振荡更小。DaPC NN 展现出更好的收敛性和稳定性,尤其是在使用高斯积分点时,有效缓解了吉布斯效应。aPC 和 DANN 模型难以应对非线性冲击波传播,导致预测误差高且不稳定。
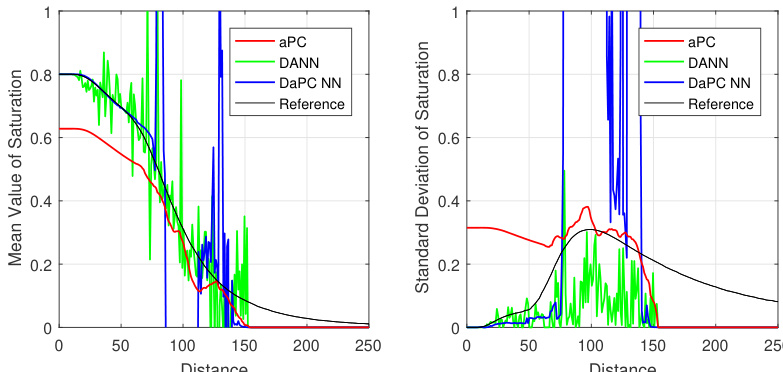
作者在不同测试用例(包括 Ishigami 函数、ON-10 问题和 CO₂ 基准)中对比了 aPC、DANN 和 DaPC NN 模型的性能。结果表明,DaPC NN 在验证精度上始终优于 aPC 和 DANN,尤其是在训练数据有限时,这归功于其平衡灵活性与正则化的能力。DaPC NN 还展现出更好的收敛性和更少的过拟合,尤其在高维和非线性场景中。在 CO₂ 基准测试中,所有模型在冲击波传播方面均面临挑战,但 DaPC NN 在使用高斯积分点训练时表现出更高的稳定性。与 aPC 和 DANN 相比,DaPC NN 实现了更优的验证性能,尤其是在小型训练数据集上。得益于正交基和正则化特性,DaPC NN 展现出更快的收敛速度和更低的过拟合率。在 CO₂ 基准测试中,DaPC NN 配合高斯积分点表现更佳,有效缓解了由非线性引起的振荡。
作者在不同测试用例中对比了 aPC、DANN 和 DaPC NN 模型的性能,重点关注不同训练数据规模下的预测精度与收敛性。与 aPC 和 DANN 相比,DaPC NN 始终展现出更优的验证性能和更快的收敛速度,尤其在处理非线性和高维问题时。DaPC NN 还表现出更少的过拟合和更好的泛化能力,尤其是在数据有限时进行训练;而 aPC 和 DANN 则在灵活性和正则化方面面临困难。在多个测试用例中,DaPC NN 展现出优于 aPC 和 DANN 的验证性能和更快的收敛速度。即使使用小型训练数据集,DaPC NN 仍表现出更少的过拟合和更好的泛化能力。aPC 和 DANN 在灵活性和正则化方面存在不足,导致在高维和非线性场景下性能较差。
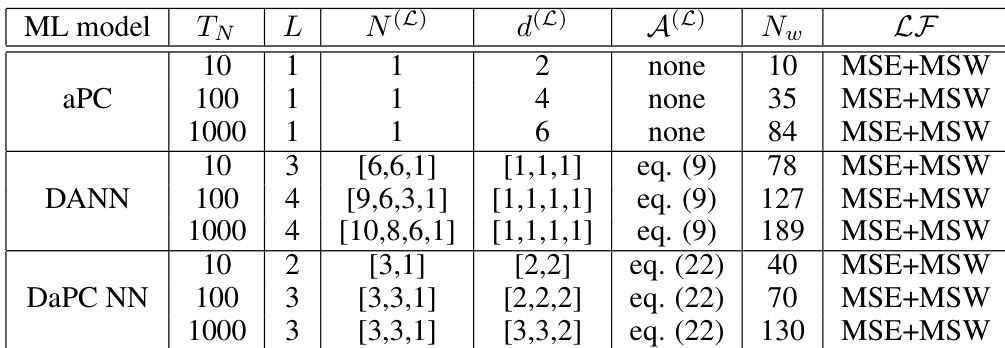
作者通过多个测试用例对比了 aPC、DANN 和 DaPC NN 模型的性能,重点关注不同训练数据规模下的预测精度与收敛行为。与 aPC 和 DANN 相比,DaPC NN 始终展现出更优的验证性能和更快的收敛速度,尤其在捕捉复杂非线性行为和降低过拟合方面。训练数据分布与模型架构的选择显著影响预测可靠性,DaPC NN 即使在挑战性条件下也表现出鲁棒性。在不同测试用例中,DaPC NN 实现了优于 aPC 和 DANN 的验证性能和更快的收敛速度。DaPC NN 表现出更低的过拟合率和更高的预测精度,尤其是在训练数据有限时。模型性能高度依赖训练数据分布,DaPC NN 从优化的输入采样策略中获益显著。
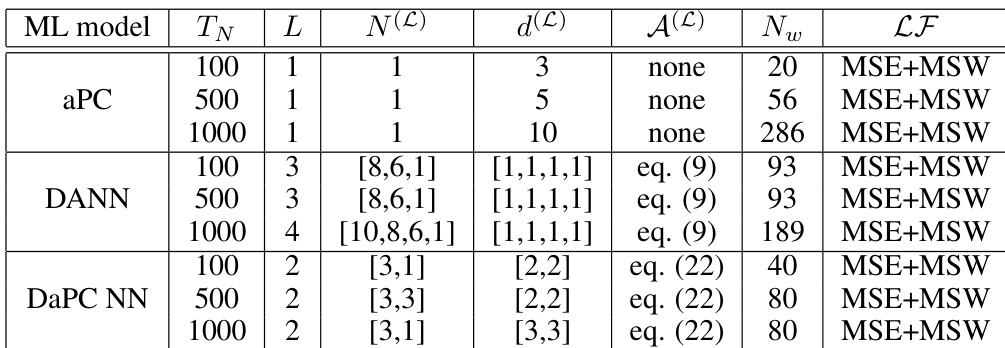
作者在不同测试用例中对比了 aPC、DANN 和 DaPC NN 模型的性能,重点关注不同训练集规模下对验证数据的预测能力。与其他模型相比,DaPC NN 始终展现出更优的性能,尤其在验证阶段,具有更快的收敛速度和更低的过拟合率。DaPC NN 以较少的自由度实现这一目标,并受益于 aPC 的正交结构;而 DANN 存在过拟合问题,aPC 在捕捉复杂非线性方面缺乏灵活性。在所有测试用例中,DaPC NN 相比 aPC 和 DANN 展现出更好的验证性能和更快的收敛速度。DaPC NN 利用 aPC 的正交性,以较少的自由度和降低的过拟合率取得了更优的结果。DANN 表现出显著的过拟合和较差的泛化能力,尤其是在小训练数据下;而 aPC 在捕捉复杂非线性行为时缺乏灵活性。
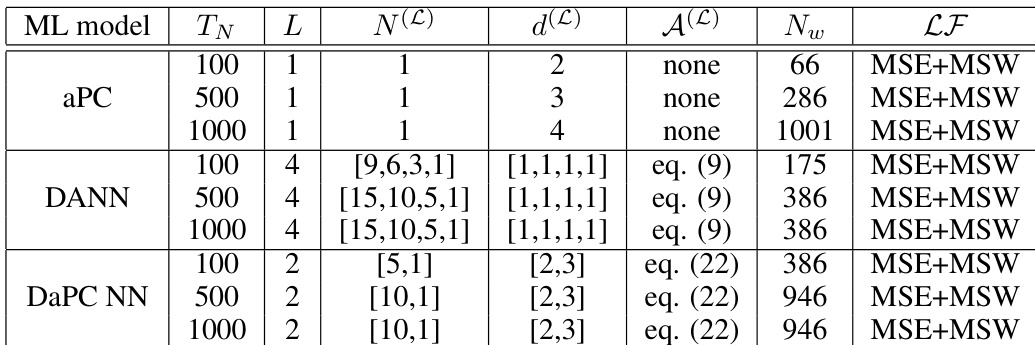
该评估在多个基准问题上对比了 aPC、DANN 和 DaPC 神经网络模型的性能,涵盖非线性冲击波传播和高维测试用例,同时调整训练数据规模与积分策略。这些实验验证了各架构在平衡灵活性与正则化以捕捉复杂不连续行为方面的有效性。定性结果表明,DaPC 模型始终提供更优的稳定性、更快的收敛速度和更低的过拟合率,尤其是在数据稀缺或采用优化采样条件时。相比之下,aPC 和 DANN 方法在泛化方面面临困难,并在处理陡峭梯度与高维非线性时表现出不稳定性。