Command Palette
Search for a command to run...
使用 Hugging Face 进行零样本文本分类
摘要
一句话总结
DetectLLM 提出了两种零样本检测方法 DetectLLM-LRR 与 DetectLLM-NPR,分别利用对数秩信息优化推理速度与检测精度,在三个数据集和七种语言模型上,相较于现有最优方法分别实现了 3.9 和 1.75 个绝对 AUROC 点数的提升,且所需扰动数量少于先前方法。
核心贡献
- 本文提出 DetectLLM-LRR 与 DetectLLM-NPR 两种零样本方法,通过利用对数秩信息检测机器生成文本。DetectLLM-LRR 针对快速推理进行优化,而 DetectLLM-NPR 则通过对底层对数概率分布进行定向扰动来提升精度。
- 在三个数据集和七种语言模型上的实验表明,DetectLLM-LRR 与 DetectLLM-NPR 分别以 3.9 和 1.75 个 AUROC 点数超越现有基线方法。基于扰动的方法在实现相当检测性能的同时,所需扰动数量少于先前技术,从而降低了实际计算成本。
- 该研究分析了两种流水线在效率与性能之间的权衡,为针对特定速度或精度需求的零样本检测器提供了实际部署指南。
引言
大型语言模型的快速普及迫切需要在数字平台上自动区分人工撰写内容与 AI 生成文本,以防滥用行为破坏学术诚信并传播虚假信息。先前的检测方法通常依赖监督式黑盒分类器,针对新模型需要高昂的重新训练成本,而现有的零样本方法要么牺牲精度,要么通过大量扰动带来难以承受的计算开销。为突破这些限制,研究团队利用对数秩统计特性提出 DetectLLM 框架,该框架包含两种互补的零样本检测器。DetectLLM-LRR 通过结合对数似然与对数秩比率实现快速分类,DetectLLM-NPR 则采用收敛速度优于先前技术的扰动策略来提升检测精度。该方法在多个模型与数据集上得到验证,展现出稳定的性能提升,并为平衡检测速度与精度提供了实践指导。
数据集
- 数据集构成与来源: 研究采用三个成熟数据集来代表大语言模型可能产生显著影响的领域:用于新闻文章的 XSum、用于维基百科段落的 SQuAD,以及用于创意故事的 WritingPrompts。每个子集均提供人工撰写的参考文本。
- 子集细节与配对: 每项实验均严格依赖 300 组配对样本。每组样本包含一段原始人工撰写文本及其对应的机器生成文本。
- 处理与裁剪策略: 为标准化生成过程,研究将每段人工文本截断至前 30 个 token,并将该前缀作为初始提示词输入目标大语言模型。这种受控裁剪确保了所有子集上下文的一致性。
- 数据用途与可复现性: 配对文本仅作为评估基准,而非训练或混合语料。完整的合成数据生成流程已通过开源代码实现,并随论文一同发布以确保完全可复现。
方法
研究利用两种互补的零样本检测特征:对数似然对数秩比率(LRR)与归一化扰动对数秩(NPR),以提升机器生成文本的识别能力。这些特征旨在捕捉文本生成模式的不同维度,尤其是能够区分合成输出与人工撰写内容的特征。
对数似然对数秩比率(LRR)定义为序列中所有 token 的平均对数似然与平均对数秩的绝对比值。具体计算方式如下:
LRR=t1∑i=1tlogrθ(xi∣x<i)t1∑i=1tlogpθ(xi∣x<i)=−∑i=1tlogrθ(xi∣x<i)∑i=1tlogpθ(xi∣x<i),其中 pθ(xi∣x<i) 表示模型在给定前文条件下对 token xi 的预测概率,rθ(xi∣x<i)≥1 表示相同条件下该 token 的排名。分子反映模型生成正确 token 的绝对置信度,分母则体现相对置信度,强调正确 token 在词表中的排名位置。该组合使 LRR 能够同时利用全局置信度(对数似然)与位置置信度(对数秩),从而提供更稳健的信号。如下图所示,机器生成文本通常呈现更高的 LRR 值,这是因为其倾向于生成对数似然较低但对数秩更易分辨的 token,使得 LRR 成为有效的判别特征。基于 LRR 的零样本检测方法被称为 DetectLLM-LRR。
实验
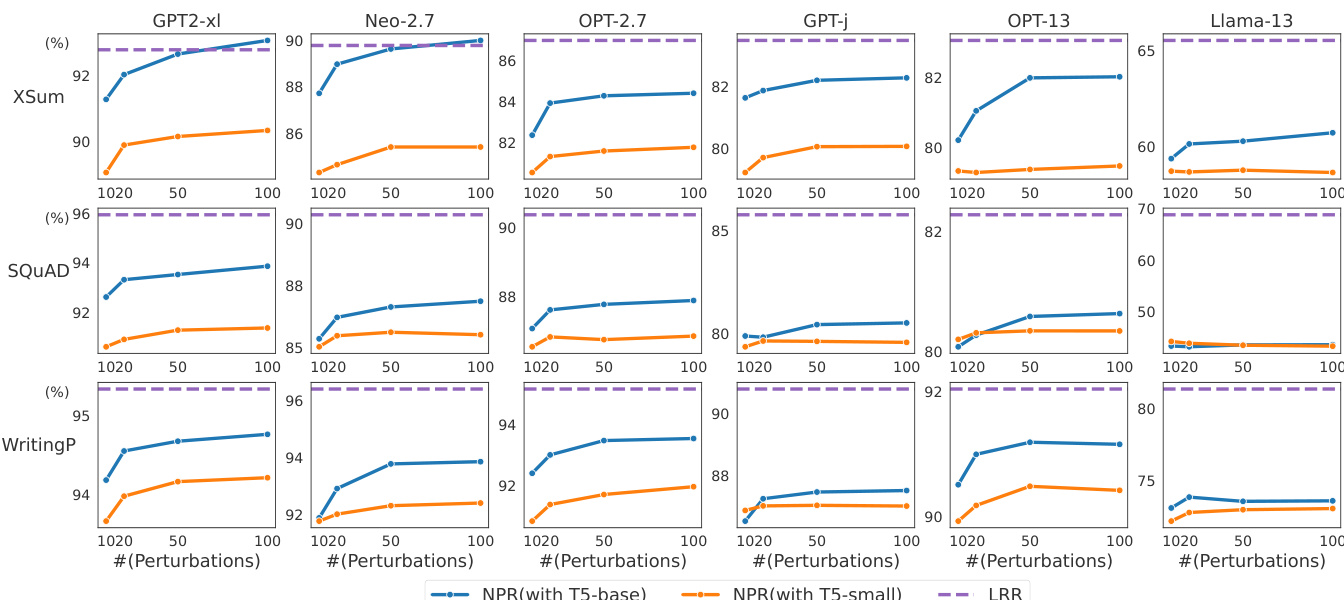
实验在多种大语言模型规模、解码策略与扰动配置下,将提出的 LRR 与 NPR 零样本检测方法与传统基线进行对比。这些测试验证了检测精度随扰动数量与模型规模的变化规律,温度与采样策略等生成设置对性能的影响,以及检测精度与计算成本之间的内在权衡。定性来看,NPR 通过显著减少扰动数量实现更高精度,持续优于同类基于扰动的方法;而无需扰动的 LRR 方法在低温生成等场景下经常达到或超越基于扰动的方法性能。最终结果表明,两种方法均在各自类别中达到最优水平,并为根据资源限制平衡效率与精度提供了可操作指导。
研究在不同解码策略与温度条件下分析了零样本文本检测方法的性能。结果表明,部分无需扰动的方法在低温场景中能够取得与基于扰动的方法相当甚至更优的高性能。这些方法的效率差异显著,无需扰动的方法速度远快于需要多次扰动的方案。基于扰动的方法因需执行多次扰动,计算成本显著高于无需扰动的方法。不同的解码策略与温度对方法性能的影响各异,部分方法在各类条件下表现出较强的稳定性。
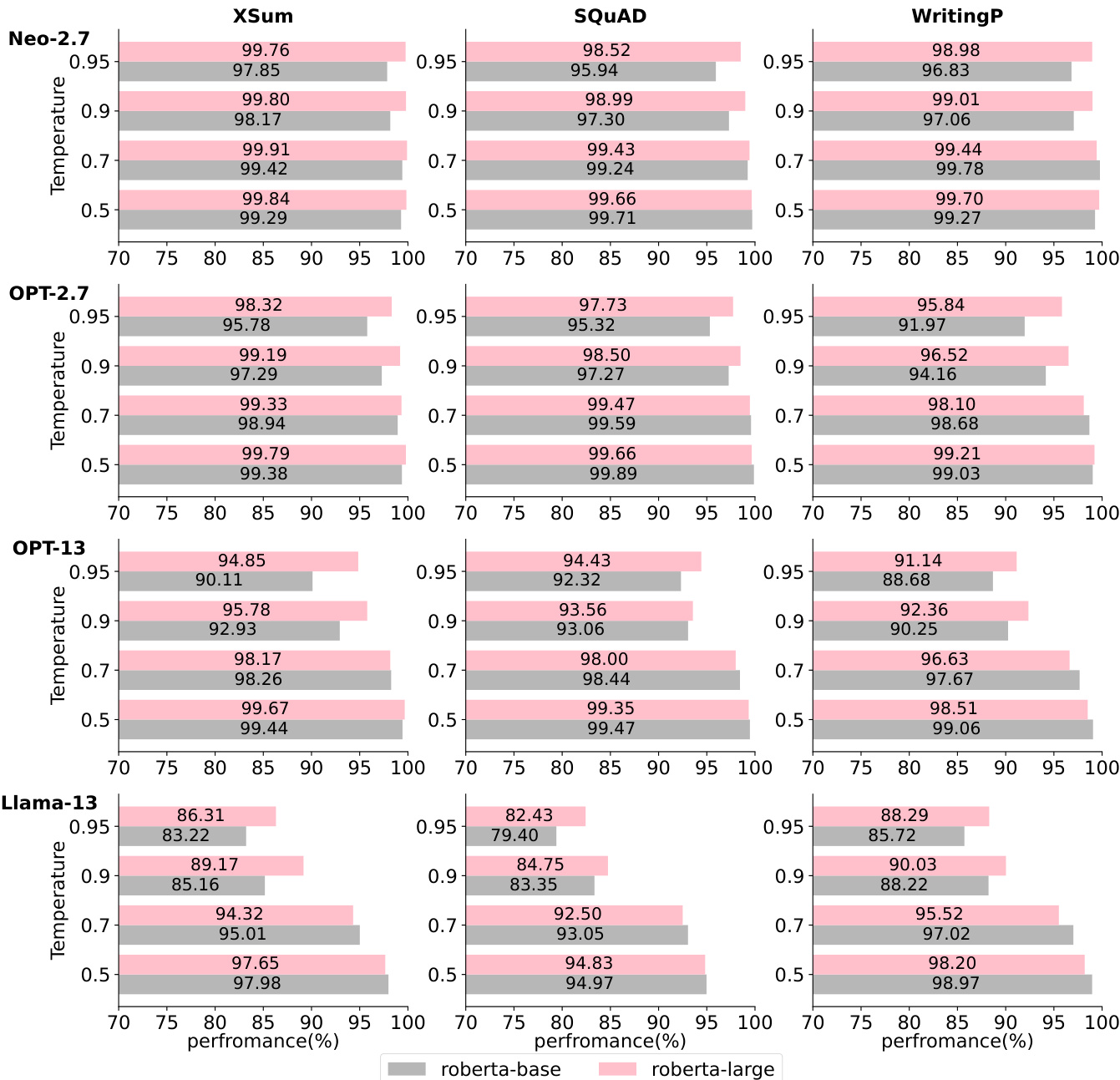
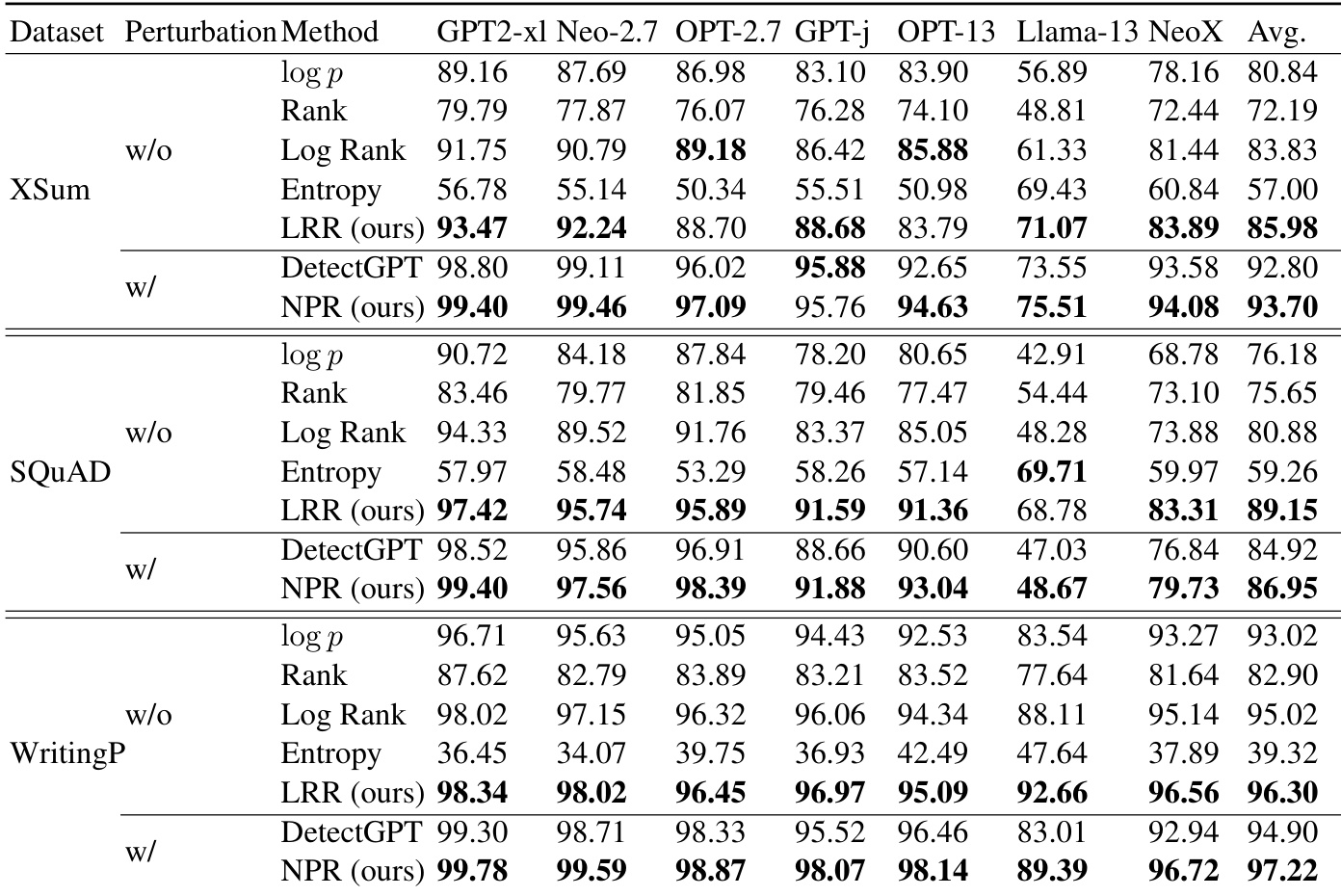
研究评估了多种用于检测机器生成文本的零样本方法,在不同语言模型与数据集上对比了基于扰动与无需扰动的方法。结果表明,提出的 NPR 方法在基于扰动的类别中持续优于 DetectGPT,而提出的 LRR 方法在无需扰动的方法中表现强劲,在某些条件下甚至超越基于扰动的方法。NPR 在所有数据集与模型的基于扰动方法中持续领先 DetectGPT。LRR 在无需扰动的方法中取得最佳性能,并能在特定数据集与条件下超越基于扰动的方法。所提方法对温度与解码策略的敏感度各不相同,LRR 在不同解码策略下均保持稳定。
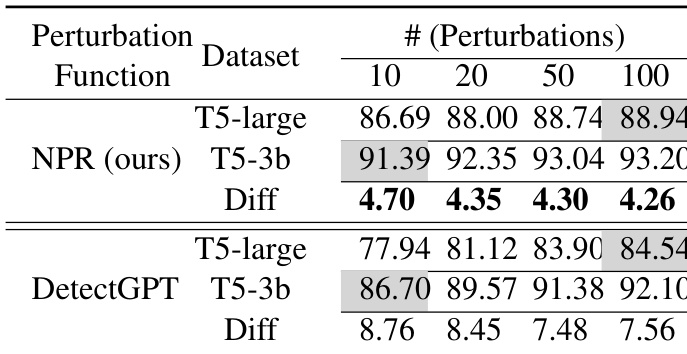
研究在不同条件下对比了所提方法 NPR 与 LRR 及现有零样本检测方法的性能。结果表明,NPR 在不同扰动数量与扰动函数规模下均持续优于 DetectGPT,而 LRR 以较低的计算成本实现了具有竞争力的性能。分析凸显了性能与效率之间的权衡,主要体现在扰动数量与所用扰动函数规模方面。NPR 在不同扰动数量与扰动函数下持续领先 DetectGPT。与基于扰动的方法相比,LRR 以更低计算成本实现同等竞争力性能。基于扰动的方法性能对扰动函数规模较为敏感,函数规模越大通常效果越好。
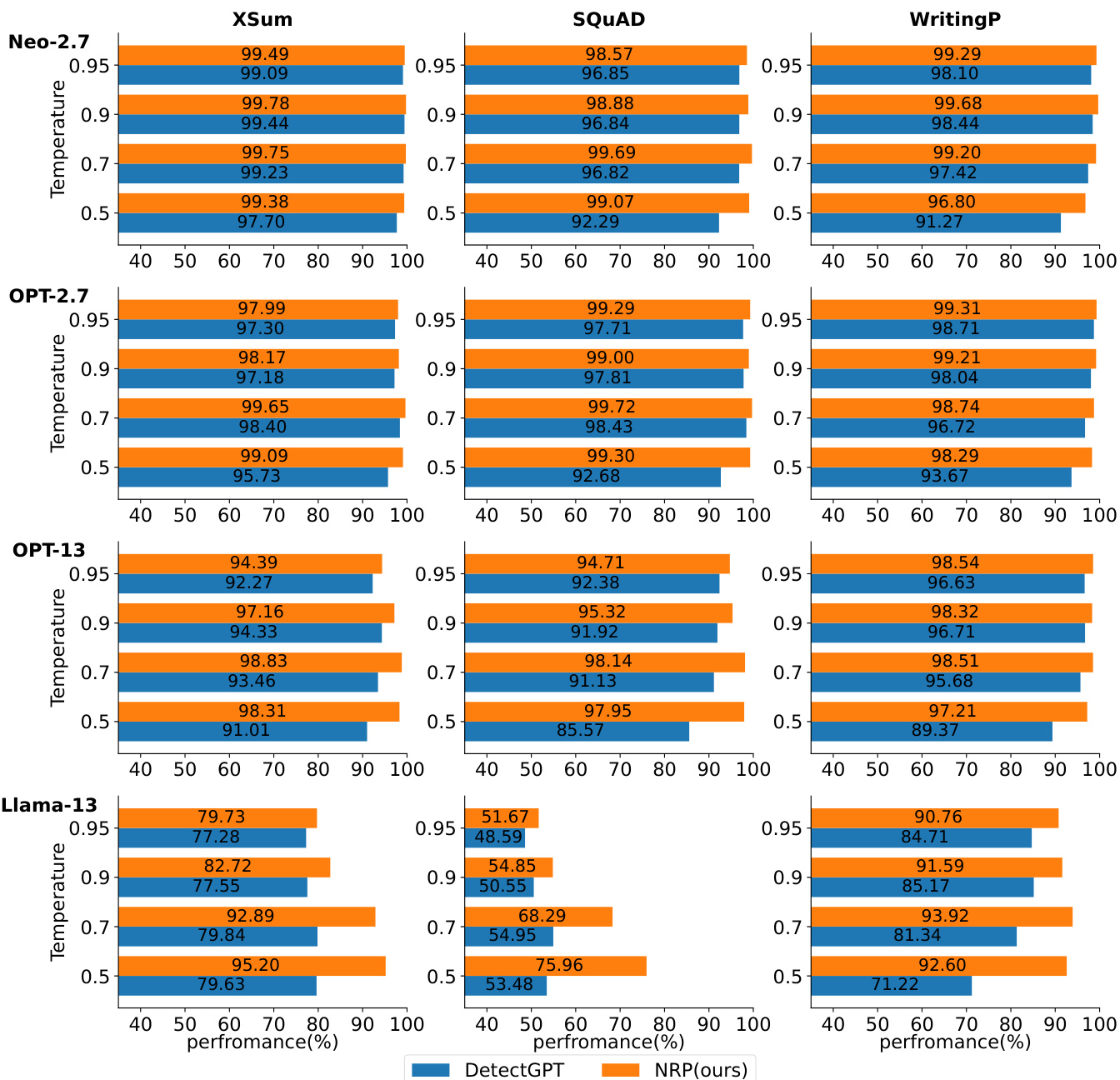
研究在多个数据集与大语言模型上对比了所提方法 LRR 与 NPR 及现有零样本检测方案。结果表明,LRR 在无需扰动的方法中持续保持高性能,经常超越部分基于扰动的方法,而 NPR 在基于扰动设置中持续优于 DetectGPT。研究同时指出,LRR 在性能与效率之间取得良好平衡,所需计算资源显著少于基于扰动的方法。LRR 在无需扰动方法中位居前列,在多个数据集上超越 DetectGPT 及其他基线。NPR 在所有数据集与大语言模型的基于扰动检测中持续领先 DetectGPT。与 NPR 和 DetectGPT 等基于扰动的方法相比,LRR 以显著更低的计算成本提供高检测精度。
研究在多个数据集与语言模型上对比了所提方法 LRR 与 NPR 及现有零样本检测方案。结果表明,NPR 在基于扰动的方法中持续优于 DetectGPT,而 LRR 在无需扰动的方法中表现强劲,经常与基于扰动的方法持平甚至超越。研究同时强调了性能与计算效率之间的权衡,尤其与扰动数量及扰动函数规模密切相关。NPR 在所有数据集与模型的基于扰动方法中持续领先 DetectGPT。LRR 在无需扰动的方法中取得高性能,经常超越 DetectGPT 等基于扰动的方法。基于扰动的方法性能对扰动函数规模较为敏感,规模越大通常效果越好,但计算成本也相应更高。
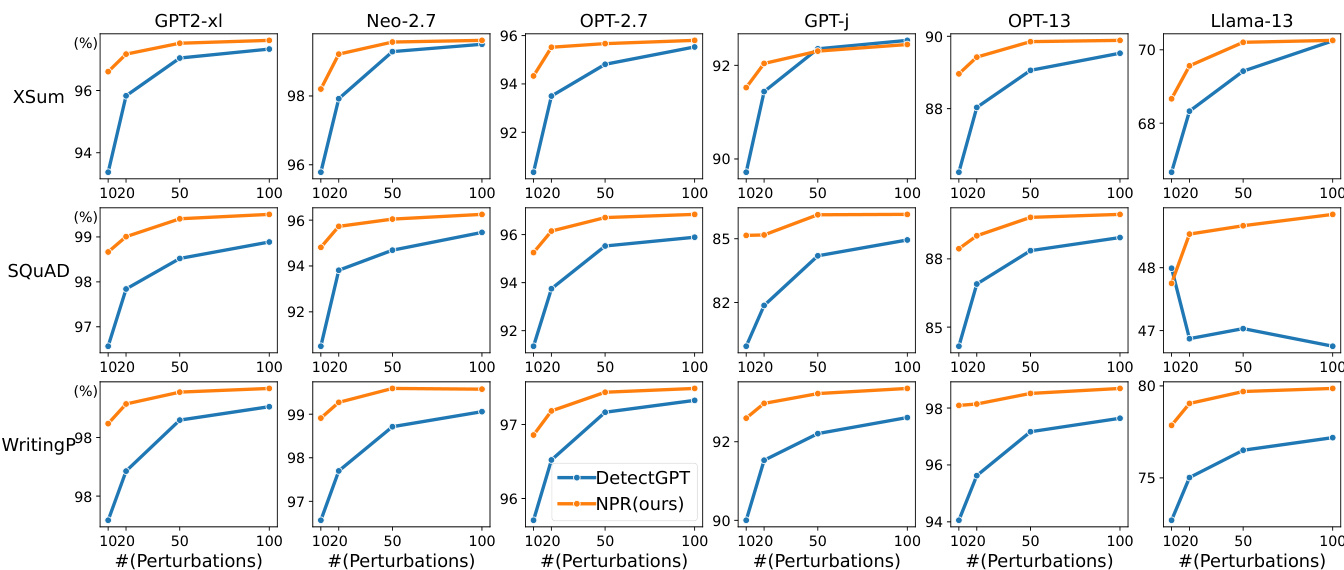
实验在多个数据集与语言模型上评估零样本机器生成文本检测方法,在不同解码策略、温度与扰动函数规模下对比基于扰动与无需扰动的方法,以验证其相对性能、计算效率与鲁棒性。结果表明,无需扰动的方法(尤其是 LRR)在实现高检测精度的同时,所需计算资源显著少于基于扰动的替代方案。此外,所提 NPR 方法持续优于现有基于扰动的基线,两种方法对生成参数的敏感度各不相同,无需扰动技术展现出更优的稳定性。最终结论明确了检测精度与计算成本之间的清晰权衡,确立了无需扰动方法作为高效可靠替代方案的地位。