Command Palette
Search for a command to run...
基于扩散模型的音频修复
基于扩散模型的音频修复
Eloi Moliner Vesa Välimäki
一键部署 Audio LDM 音频编辑教程
摘要
音频修复旨在重建受损录音中缺失的片段。大多数现有方法在缺口长度较短时能够产生合理的重建结果,但在重建超过约100毫秒的较大缺口时表现不佳。本文探讨了扩散模型(一类最新的深度学习模型)在音频修复任务中的应用。所提出的方法使用无条件训练的生成模型,可以以零样本方式条件化用于音频修复,并能够重建任意大小的缺口。此外,本文还提出了一种基于常数Q变换(constant-Q transform)改进的深度神经网络架构,使模型能够利用音频中的音高等变对称性。通过客观和主观指标对算法性能进行了评估,针对重建从短到中等大小(最长300毫秒)缺口的任务进行测试。正式听力测试结果表明,对于50毫秒范围内的短缺口,该方法的表现与基线方法相当;对于长达300毫秒的较宽缺口,我们的方法优于基线方法,并保持良好或可接受的音频质量。本文提出的方法可用于恢复遭受严重局部干扰或信号丢失的声音录音。
一句话总结
该无条件训练的扩散模型利用恒定Q变换架构,充分挖掘音频的音高等变对称性。通过零样本条件引导,该模型能够重建长达300毫秒的音频缺失片段。客观指标与主观听音测试表明,其在更宽的缺失区间上优于现有基线方法,同时保持良好的或可接受的音频质量,从而实现对存在严重局部干扰或信号丢失录音的稳健修复。
核心贡献
- 本文提出了一种针对无条件训练扩散模型的零样本条件引导策略,用于重建任意长度的缺失音频片段,解决了先前方法在超过100毫秒的缺失区间上失效的局限性。
- 提出了一种基于恒定Q变换改进的深度神经网络架构,显式利用音频的音高等变对称性,以增强频谱表示能力与重建保真度。
- 结合客观指标、主观度量与正式听音测试的评估结果表明,该方法在50毫秒缺失区间上与基线性能持平,在长达300毫秒的区间上优于现有方法,同时保持良好或可接受的音频质量。
引言
音频修复旨在重建录音中缺失或损坏的片段,这是恢复历史媒体、补偿网络丢包以及支持创意音频制作的基础任务。依赖自回归建模或稀疏信号表示的传统技术仅在100毫秒以内的缺失区间表现优异,因为它们依赖于信号平稳性假设,该假设在较长时段内不成立。尽管生成对抗网络等深度生成模型提供了更高的灵活性,但它们通常需要在特定退化类型上进行监督训练,这限制了其对未见音频上下文的适应能力。作者利用扩散模型突破这些限制,通过训练无条件生成网络,使其在推理阶段能够通过零样本方式进行条件引导。该方法引入了一种在可逆恒定Q变换域中运行的新架构,以利用音频中的音高等变对称性。该设计使模型无需辅助侧信息即可重建长达300毫秒的缺失片段,在持续优于现有基线方法的同时,保持了自然的感知质量。
数据集
- 数据集构成与来源:本文节选未提供数据集信息。文本仅概述了Vesa Välimäki的学术背景与职业归属。
- 各子集关键细节:未提及子集划分、数据规模或过滤标准。
- 论文的数据使用方式:节选未描述训练集划分、混合比例或模型集成细节。
- 处理细节:未包含裁剪策略、元数据构建或预处理步骤。
方法
提出的方法名为CQT-Diff+,利用扩散模型框架进行音频修复,其核心生成过程由去噪神经网络引导。整体架构设计用于在时频域中高效运行,利用恒定Q变换(CQT)挖掘和声音频信号的音高等变结构。扩散过程始于含噪输入波形 xT,并通过一系列步骤迭代去噪。在每个时间步 τ,模型使用深度神经网络 Dθ(xτ,τ) 预测去噪估计值 x^0,该网络遵循Karras等人[48]提出的预条件化策略进行参数化。该网络由一个在CQT域中运行的去噪模块 Fθ 组成,定义为 Fθ=ICQT∘Fθ′∘CQT。该结构使模型能够通过CQT处理输入波形,在变换域中应用神经网络,随后对变换结果进行逆变换以生成时域输出,并在整个过程中保持可微性。
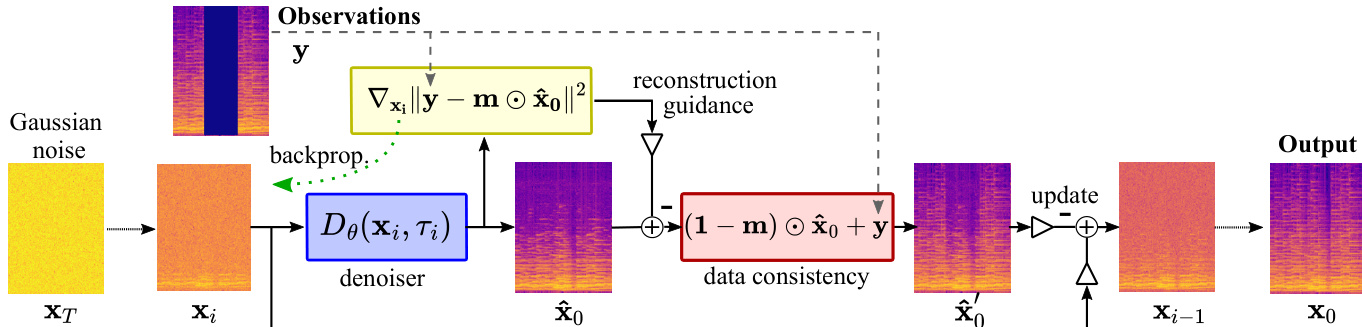
音频修复的推理过程改编自标准扩散框架,用于求解线性逆问题。给定由二值掩码 m 定义缺失样本的观测音频信号 y,目标是恢复原始信号 x0。模型通过以观测数据为条件来引导扩散过程实现这一目标。具体做法是在反向扩散常微分方程的得分函数中引入受噪声扰动的似然得分,该得分融合了观测测量值。后验得分近似为先验得分与对数似然梯度的和,其中似然函数被建模为正态分布。由此产生一个重建引导项,将去噪估计值向观测数据拉近。为确保观测样本的完整性,每次迭代均应用数据一致性步骤,通过将掩码范围内的值替换为观测值 y 来更新输出。为减轻掩码边界处的伪影,此步骤使用掩码的平滑版本。
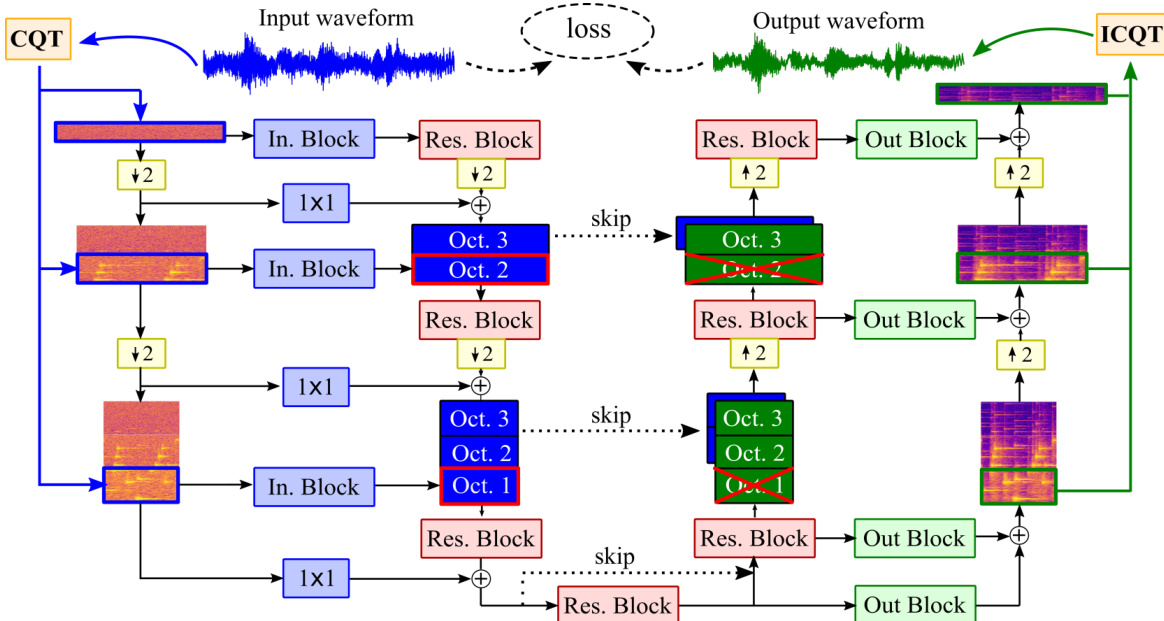
核心去噪器 Fθ′ 采用U-Net架构,该架构非常适合CQT提供的层次化表示。该架构设计用于处理多个八度频带的CQT频谱图,每个八度频带由编码器与解码器中的独立分支进行处理。U-Net结构包含对称的编码器与解码器,并通过跳跃连接桥接中间分辨率特征。编码器在每一层将输入频谱图下采样两倍,而解码器则进行上采样。在每个分辨率层级,编码器特征与解码器对应特征进行拼接。该架构采用双实数表示法,将复数CQT特征的实部与虚部堆叠为两个独立通道。该方法避免了复数层带来的计算开销,同时保留了实部与虚部之间的相位关系。为维持该对称性,卷积层中的偏置项等基于平移的操作被设为零,加法操作仅使用残差连接。
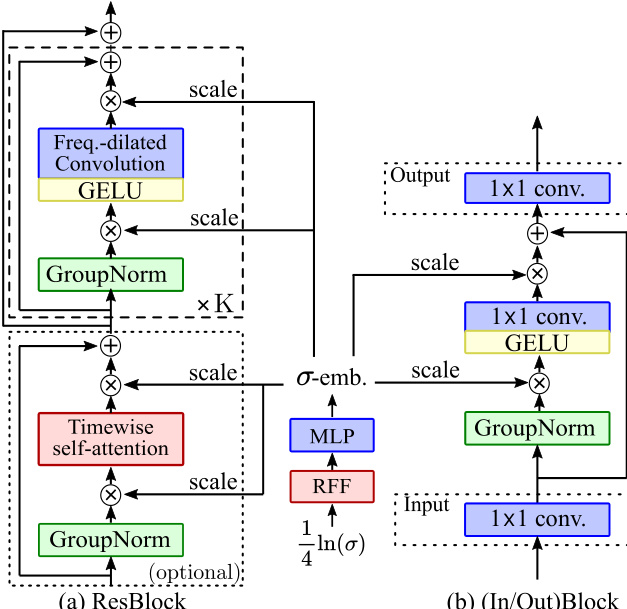
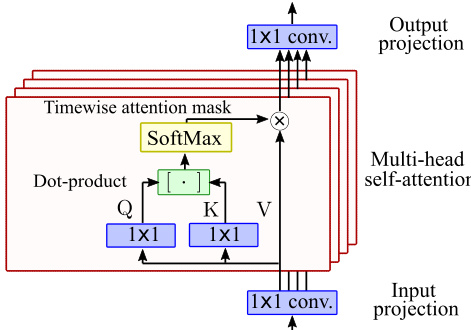
U-Net的构建模块在架构图中得到了进一步详细说明。主要构建模块为“残差块(Res. Block)”,如图3(a)所示。每个残差块包含一组无平移操作的组归一化层,后接GELU非线性激活函数以及时间与频率维度的卷积操作。频率卷积采用指数递增的膨胀率,以在利用音高等变性的同时提供广阔的感受野。在较深层中,引入了时间维度的自注意力层以捕捉全局时间依赖关系,这对修复任务至关重要。如图4所示的自注意力机制仅在时间维度上运行,以降低计算复杂度。该机制使用 1×1 卷积将特征投影至低维空间以进行查询与键值计算,随后应用带有时间掩码的点积注意力机制,最后投影回原始维度。整个架构以噪声水平 σ 为条件,使用噪声水平嵌入 σ-emb 进行引导。该嵌入通过随机傅里叶特征(RFF)与多层感知机(MLP)从噪声水平生成。该嵌入通过逐特征线性调制对特征进行调制,且不添加平移项。
实验
提出的CQT-Diff+方法通过与LPC和A-SPAIN-L基线进行对比,利用客观测量与主观听音测试,评估了其在25至300毫秒不同缺失长度下的音乐音频修复性能。这些实验验证了重建精度与感知相似度随缺失时长的变化规律,结果表明,尽管所有方法在极短缺失区间表现相当,但随着缺失尺寸增大,基于扩散的模型持续提供更优的听觉保真度。定性来看,传统方法倾向于产生人工化或衰减的输出,而CQT-Diff+能够生成连贯且符合音乐逻辑的重建结果,最长可达200毫秒,证明了其在不同缺失长度下合成逼真音频内容的稳健能力。
作者将提出的CQT-Diff+方法与LPC和A-SPAIN-L两种基线进行对比,评估其在音乐录音短至中等尺寸缺失区间修复任务中的表现。主观听音测试结果表明,CQT-Diff+在最短缺失长度上与基线表现相当,但在更长缺失区间持续优于基线,且在100毫秒、200毫秒和300毫秒处观察到显著的统计差异。所有方法的性能均随缺失长度增加而下降,但CQT-Diff+在所有测试时长内均保持较高的感知质量。CQT-Diff+在最短缺失长度上达到与基线相似的感知质量,但在更长缺失区间表现更优。所有方法的性能均随缺失长度增加而下降,CQT-Diff+在整个时长范围内维持更高质量。统计分析证实,在100毫秒、200毫秒和300毫秒的缺失长度下,CQT-Diff+显著优于LPC。
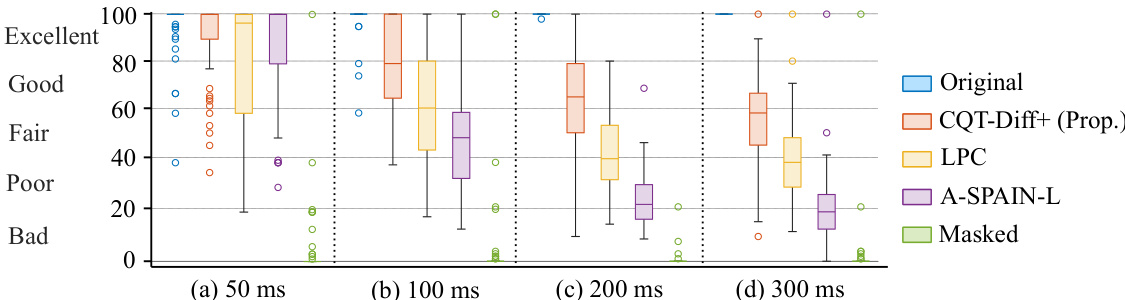
作者通过主观听音测试将CQT-Diff+方法与LPC和A-SPAIN-L基线进行对比,验证了其在修复不同长度音乐缺失片段时的感知质量。尽管所有方法的性能均随缺失时长增加而下降,但CQT-Diff+在整个测试范围内持续保持更优的音频保真度。这些发现证实,该方法在极短缺失区间与基线性能持平,而在较长区间提供显著更优的结果,展现了其在长跨度修复任务中增强的鲁棒性。