Command Palette
Search for a command to run...
用 PyTorch 实现口罩佩戴检测
摘要
一句话总结
针对疫情期间训练数据有限的问题,本研究对三种目标检测架构(SSD、YOLOv4-tiny 和 YOLOv4-tiny-3l)进行了基准测试,用于实时口罩佩戴检测。最终为实际场景和移动应用选定 YOLOv4-tiny,在包含三个类别的 1,531 张图像的两个数据集集合上,取得了 85.31% 的平均精度均值(mAP)和 50.66 帧/秒的推理速度。
核心贡献
- 本研究评估了三种先进的目标检测架构,即 SSD、YOLOv4-tiny 和 YOLOv4-tiny-3l,旨在建立一个用于实时口罩佩戴合规性监测的有效框架。对比分析解决了在资源受限的移动设备上部署健康监测系统所面临的约束条件。
- 系统性性能评估确定 YOLOv4-tiny 为实际部署的最优架构,能够将个体准确分类为三个类别:正确佩戴口罩、未佩戴口罩以及佩戴口罩不规范。
- 所选模型仅使用 1,531 张图像的合并数据集,即达到 85.31% 的平均精度均值和 50.66 帧/秒的速度,证明了在训练数据有限的情况下,该模型仍具备在拥挤环境中进行可行实时检测的能力。
引言
自动口罩检测已成为在拥挤或受限环境中执行公共卫生协议的关键工具,以实时计算机视觉取代了易出错的 人工监控。然而,以往研究一直受限于面部特征点被遮挡、数据集规模有限或依赖合成数据、类别不平衡,以及模型缺乏实时速度或需要过高计算资源等问题。本文作者利用三种先进的目标检测架构来应对这些限制,最终确定 YOLOv4-tiny 为最优解决方案。该方法直接在包含三个合规类别的 1,531 张紧凑数据集上进行训练,无需预处理,实现了 85.31% 平均精度均值与 50.66 帧/秒速度的实用平衡,从而支持在移动设备和边缘设备上进行高效部署。

数据集
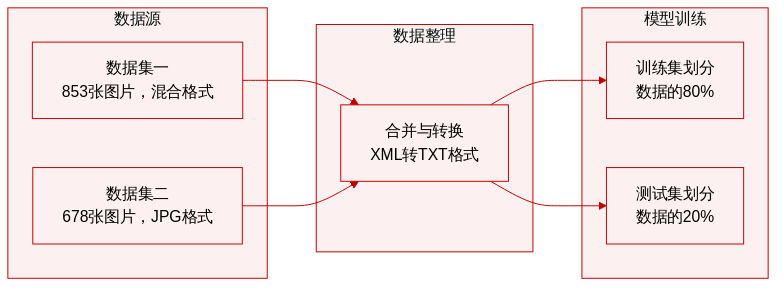
- 数据集构成与来源: 作者整合了两个外部图像集合,构建了用于口罩检测的统一库,最终形成包含 JPG 和 PNG 格式文件的混合数据集,涵盖三个类别:正确佩戴口罩、未佩戴口罩以及佩戴口罩不规范。
- 子集详情: 第一个来源提供 853 张 PNG、JPG 和 JPEG 格式图像,涵盖从单人到拥挤环境的多样化场景。第二个来源补充了 678 张 JPG 图像,对应相同的三个分类标签。
- 处理与元数据构建: 包含图像尺寸和边界框坐标的原始 XML 标注文件被转换为 TXT 格式,以确保与 YOLO 和 SSD 目标检测架构兼容。坐标元数据已标准化,用于追踪每个检测到的个体的右上角和左下角坐标。
- 训练策略与数据使用: 合并后的数据集按 80% 训练集和 20% 测试集进行划分。作者指出最终实例分布中存在显著的类别不平衡问题,其中 6322 个样本标记为佩戴口罩,1377 个为未佩戴,247 个为佩戴口罩不规范。
方法
作者采用了 YOLO(You Only Look Once)系列目标检测模型。该系列模型通过将目标检测视为回归问题而非分类任务,旨在加速实时检测。由 Redmon 等人于 2016 年开发的基础 YOLO 模型后来被 SSD(Single Shot MultiBox Detector)改进,实现了更高的精度与速度。此后,YOLO 推出了多个版本,每一代均在精度和推理速度上有所提升。其中,YOLO-tiny 变体通过减少卷积层数量来降低模型复杂度,从而在牺牲部分精度的情况下提升运行速度。然而,在训练数据有限的场景中,由于复杂度降低且过拟合风险较小,YOLO-tiny 的性能可能优于标准 YOLO 模型。
为解决小目标检测难题,YOLOv3 引入了多尺度检测机制,在每个网格单元中使用三个特征图尺度和九个锚框。相比之下,YOLOv3-tiny 仅使用两个尺度和六个锚框,从而在速度与精度之间进行权衡。作者引用了这些变体之间的架构差异,指出 YOLOv3-tiny 在 COCO 数据集上达到了 33.2% 的平均精度均值(mAP),且运行速度比 YOLOv3 快 11 倍。

实验
本次评估使用了包含室内外场景的多样化数据集,测试了 YOLOv4-tiny 变体与 SSD 模型在不同人群密度、光照条件和种族背景下的表现,验证了其在实际场景中的泛化能力。一项专门针对检测类别合并的消融实验证实,与二分类相比,保留三个独立类别能显著提升模型的鲁棒性。此外,与以往架构的对比试验表明,所提出的轻量级方法在消除大量预处理步骤的同时,在精度和推理速度上均优于更重的替代方案。最终,研究结果证实该优化模型有效平衡了计算效率与可靠的检测性能,使其非常适合在实际多样化的监控环境中部署。
作者将所提方法与现有的口罩检测方案进行了对比,强调其模型在保持低计算成本和实时性能的同时,实现了更高的 mAP。研究强调了采用三分类系统的重要性,并证明了即使在数据集有限的情况下,模型在不同图像条件下仍具备鲁棒性。结果表明,该方法在精度和效率方面优于多项前期工作,尤其在实际应用场景中表现突出。所提方法在保持实时性能和低计算成本的前提下,取得了比现有方案更高的 mAP。三分类系统的使用提升了模型相较于二分类方案的鲁棒性与精度。尽管数据集规模有限,该方法在实际数据上仍展现出强劲性能,适用于移动设备与监控应用的部署。
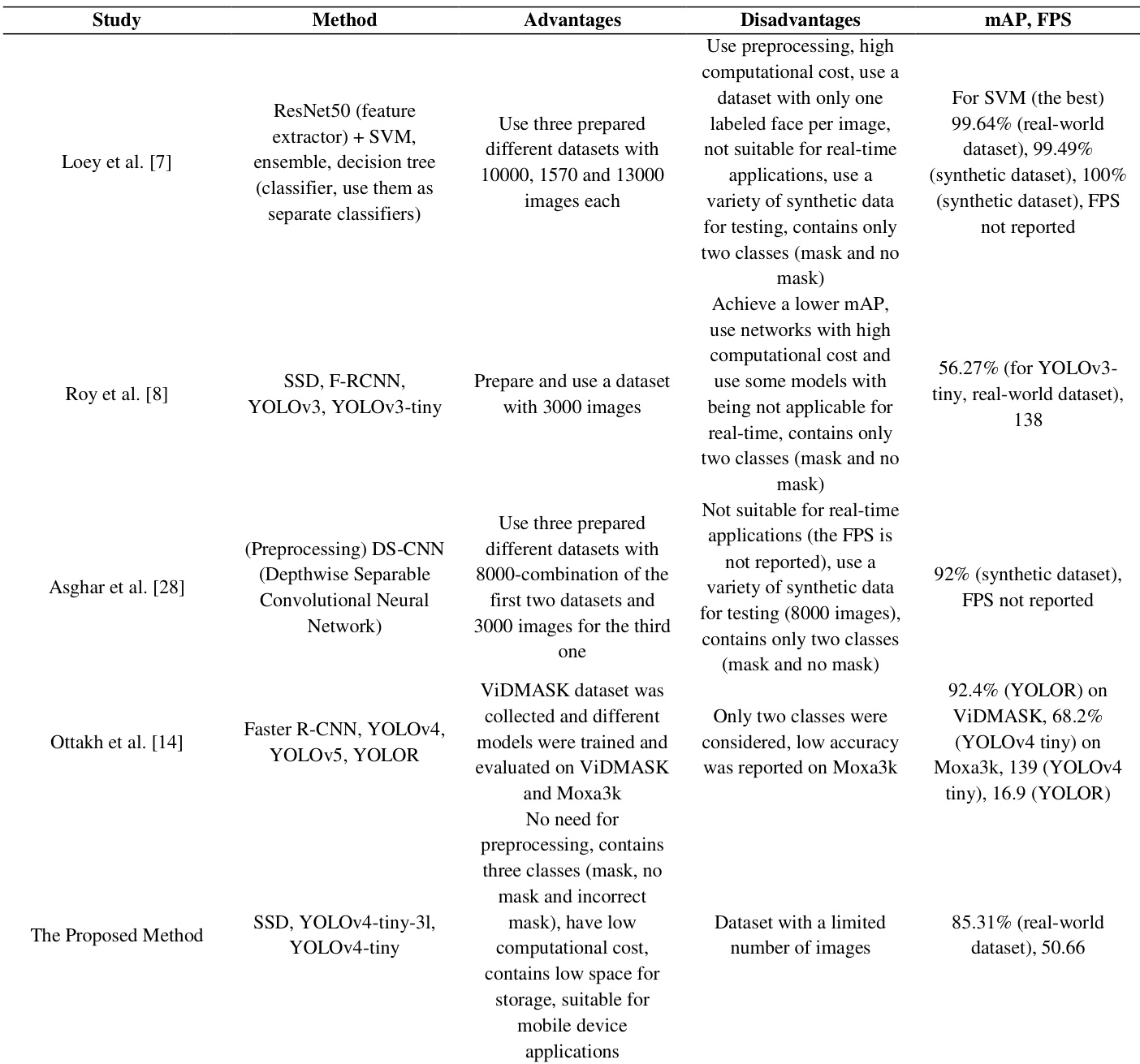
作者对比了三种目标检测模型在口罩检测任务上的性能,重点关注速度与精度。结果表明,YOLOv4-tiny 模型在测试模型中速度最快,同时展现出较强的精度,尤其在检测“佩戴口罩不规范”类别时表现突出。这些模型在规模与多样性有限的数据集上进行了评估,但在包括实际场景在内的不同条件下仍保持了稳健的性能。YOLOv4-tiny 模型在测试模型中速度领先。与其他模型相比,YOLOv4-tiny 在“佩戴口罩不规范”类别上表现更佳。所有模型均达到了适用于实时应用的运行速度,其中 YOLOv4-tiny 速度最快。

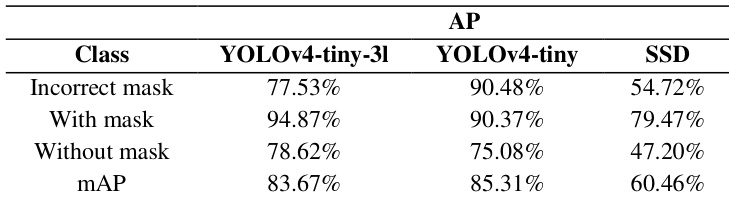
作者对比了 YOLOv4-tiny-3l、YOLOv4-tiny 和 SSD 模型在口罩检测任务上的性能,重点关注其对三个类别(佩戴口罩不规范、佩戴口罩、未佩戴口罩)的分类能力。结果表明,YOLOv4-tiny 在所有类别上的平均精度最高,尤其在“佩戴口罩不规范”类别上表现最佳,而 SSD 模型表现最差。这些模型在精度和速度方面均接受了评估,其中 YOLOv4-tiny 速度最快,适用于实时应用。研究强调了多分类方法的重要性,并证明尽管数据集存在局限,模型仍能对不同人群实现良好的泛化。YOLOv4-tiny 在平均精度上优于 YOLOv4-tiny-3l 和 SSD,尤其是在“佩戴口罩不规范”类别上。SSD 模型在所有类别上的性能均处于最低水平,尤其在检测“佩戴口罩不规范”类别时效果不佳。YOLOv4-tiny 实现了最高速度,使其非常适合用于实时监控应用。
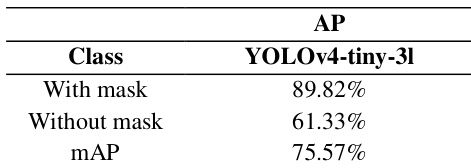
作者评估了 YOLOv4-tiny-3l 在口罩检测任务上的性能,并报告了不同类别的平均精度。该模型在“佩戴口罩”类别上取得了较高精度,而在“未佩戴口罩”类别上精度较低,最终得出中等水平的 mAP。结果表明,该模型在给定数据集上表现良好,尤其在检测正确佩戴口罩的样本时效果显著。YOLOv4-tiny-3l 在“佩戴口罩”类别上实现了较高的平均精度。与“佩戴口罩”类别相比,该模型在“未佩戴口罩”类别上的平均精度较低。整体 mAP 表明其在验证数据集上的性能处于中等水平。
实验在三项口罩检测任务上对比了多种目标检测架构,以评估其预测精度、计算效率与实时可行性。主要基准测试验证了所提方法与 YOLOv4-tiny 优于基础架构,证明其能够在最小化处理开销的情况下快速且准确地识别所有口罩类别。额外评估进一步证实,多分类策略显著增强了模型在不同成像条件下的鲁棒性,最终证明尽管训练数据有限,这些轻量级模型在实际移动设备与监控部署中仍具有高度可行性。