Command Palette
Search for a command to run...
一键部署多语言文本转语音模型 Orpheus TTS
摘要
一句话总结
该方法将零样本文本到语音(TTS)模型直接以自监督语音表示模型作为条件,并分别对声学特征和音素时长预测器进行条件控制,以解耦节奏与音色特征。客观与主观评估证实,该方法在未见说话人上提升了说话人相似度与语音节奏迁移效果。
核心贡献
- 本文提出了一种零样本文本到语音框架,直接从大规模音频数据上训练的自监督语音表示模型中提取说话人嵌入向量。
- 该架构为声学特征和音素时长预测器采用独立的条件控制路径,以生成解耦的嵌入向量,从而将基于节奏的特征与声学属性分离。
- 客观与主观评估表明,该方法提升了未见说话人的说话人相似度,并实现了跨不同参考语音的有效节奏迁移。
引言
零样本文本到语音合成技术使系统无需目标特定训练数据即可为未见说话人或语言生成自然语音,这在可扩展的语音克隆与多语言部署中具有重要价值。先前的方法通常在韵律迁移方面表现不稳定,需要大量的适配录音,或在完全依赖语言编码器时丢失说话人身份特征。作者通过利用自监督语音表示作为条件信号来解决这些瓶颈,直接从未标注音频中有效提取说话人及韵律特征。其框架证明,这些预训练模型能够可靠地引导合成网络生成高保真语音输出,且无需进行任何零样本微调。
数据集
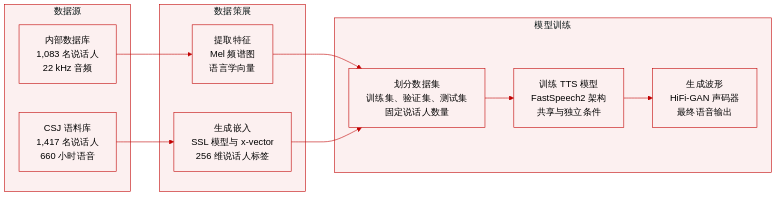
- 数据集构成与来源: 作者将内部专有日语语音数据库与公开可用的自发日语语料库(CSJ)相结合。
- 子集详情与划分: 内部数据集包含 1,083 名说话人,融合了新闻主播、配音演员等专业人员与非专业参与者。数据划分为训练集(978 名说话人,共 135,202 句语音)、验证集(52 名说话人,共 7,243 句语音)和测试集(53 名说话人,共 6,421 句语音)。CSJ 数据集提供了由 1,417 名说话人录制的 660 小时自发语音。
- 数据处理与使用: 内部录音采样率为 22.05 kHz,并手动标注了重音信息。作者提取帧移为 5.0 ms 的 80 维梅尔频谱图,并将其与 303 维语言向量对齐,以训练 FastSpeech2 模型。CSJ 语料库用于预训练 w2v2 和 HuBERT 自监督模型,以及传统的 x-vector 基线模型。这些模型将 16 kHz 音频转换为 256 维说话人嵌入向量,随后冻结并输入至 TTS 流水线。
- 条件控制与合成细节: 作者评估了共用条件与独立条件策略,将说话人嵌入向量分别通过平均池化或基于注意力的 LSTM 进行路由。所有实验配置下的最终波形均使用 HiFi-GAN 声码器重建。
方法
作者采用基于 FastSpeech2 的非自回归文本到语音(TTS)模型作为核心合成框架。该模型首先将输入文本编码为声学特征序列,随后由时长预测器处理以确定音素的时间位置,并由独立的预测器处理音高与能量。这些预测器的输出与编码后的文本一同输入解码器,以生成最终语音波形。核心创新在于如何通过自监督学习(SSL)模型(如 HuBERT 或 wav2vec 2.0)应用说话人条件控制,以提取丰富的说话人专属嵌入向量。
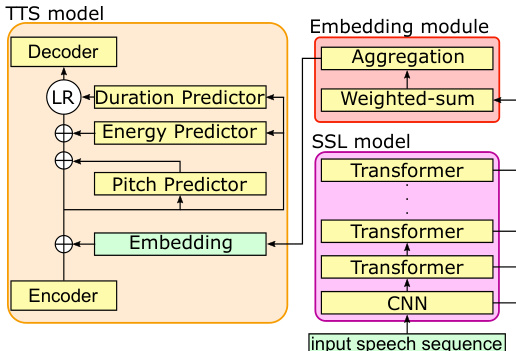
如图所示,输入语音序列由 SSL 模型处理,生成帧级语音表示向量序列。该序列中的每个向量均源自 SSL 模型不同层的输出,从而形成高维表示。随后,该序列被传入嵌入模块,旨在将其压缩为捕获说话人特征的定长向量。
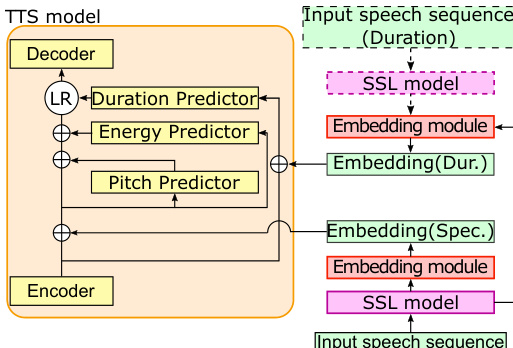
该嵌入模块由两个阶段组成。第一阶段为加权求和操作,将 SSL 模型各层在每个时间帧的输出进行组合,生成加权求和的语音表示向量。第二阶段为聚合操作,将该帧级序列压缩为单个定长嵌入向量。研究考虑了两种聚合方法:平均池化,即计算序列的均值;以及基于 LSTM 输出的软注意力机制,该机制利用注意力机制有选择地聚焦于更显著的帧,从而更好地捕捉语音节奏等时间动态。这种基于注意力的方法有望生成更具区分度的说话人特征嵌入。
此外,作者引入了一种独立条件控制机制,以将说话人的节奏与其声学特征解耦。该方法通过为时长预测器及其他声学预测器(音高与能量)获取独立的嵌入向量来实现。通过为每个预测器提供专属的嵌入向量进行条件控制,模型能够独立建模节奏属性(由时长预测器的嵌入控制)与声学属性(由其他预测器的嵌入控制)。这种分离使系统能够执行语音节奏迁移,即将一位说话人的声学特征与另一位说话人的节奏相结合。
实验
评估在平行与非平行合成条件下,比较了采用自监督学习模型与独立条件控制的零样本文本到语音方法与传统说话人嵌入技术。客观与主观实验验证了该方法成功解耦了基于节奏与声学特征,在未见领域说话人上实现了更优的说话人相似度与稳健性能。额外评估证实了模型显式迁移语音节奏的能力、对训练语言的较低依赖性,以及在使用更大架构时的泛化能力提升。总体而言,结果表明隔离韵律与声学表示显著提升了合成保真度,并实现了精确的语音控制。
作者进行了主观评估,将所提方法与零样本 TTS 中的传统方法进行比较,重点关注非平行条件下的自然度与相似度。结果表明,与基线相比,所提方法获得了更高的偏好评分,且与参考语音节奏的对齐度更好,尤其在捕捉说话人专属节奏特征方面表现更佳。在语音节奏迁移评估中,所提方法的偏好评分高于基线。与基线相比,所提方法展现出与参考语音节奏更好的对齐效果。与基线相比,所提方法在捕捉说话人专属节奏特征方面表现出更优的性能。

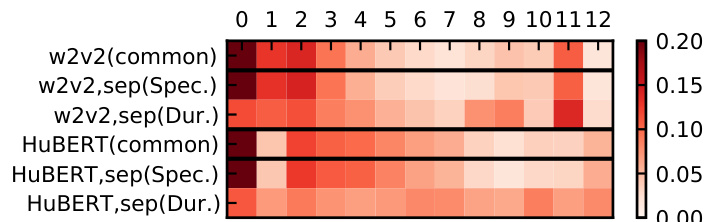
作者分析了 SSL 模型中不同层在零样本 TTS 说话人条件控制中的作用,重点关注对声学特征和音素时长的独立条件控制如何促成解耦嵌入。结果表明,所提方法通过利用 SSL 模型的不同层,有效分离了基于节奏与基于声学特征的说话人属性,其中较深层主要贡献于时长条件控制,较浅层则贡献于声学特征。独立条件控制实现了基于节奏与基于声学特征的说话人属性解耦。所提方法为不同的条件控制任务使用 SSL 模型的不同层,较深层对时长预测的影响更大。权重可视化表明,共用条件控制依赖较浅层(与 x-vector 类似),而独立条件控制则为各任务提取独立信息。
作者进行了主观评估,比较了使用 HuBERT 嵌入的所提方法与 x-vector 基线在自然度与相似度上的表现。结果显示,所提方法在保持与 x-vector 相当的自然度同时,显著提升了相似度,尤其在捕捉基于节奏的说话人特征方面。基于 LSTM 的 HuBERT 嵌入聚合在相似度上优于平均聚合,表明说话人特征解耦效果更好。所提方法在保持相当自然度的同时,相似度高于 x-vector。HuBERT(LSTM)在相似度上优于 HuBERT(平均),表明说话人特征解耦更优。所提方法在未见领域说话人(尤其是配音演员与儿童)上表现出更高的相似度。

作者比较了在平行与非平行条件下,采用 SSL 模型的所提零样本 TTS 方法与传统的 x-vector 方法。结果表明,所提方法(尤其是采用独立条件控制与 LSTM 聚合时)在平行条件下于梅尔频谱图与音素时长指标上均取得更优性能,在非平行设置下则呈现相当或提升的结果。所提方法展现出更卓越的节奏迁移能力与对未见领域说话人的处理优势。在平行条件下,采用独立条件控制与 LSTM 聚合的所提方法在梅尔频谱图与音素时长上优于 x-vector。在非平行条件下,所提方法在梅尔频谱图上的性能相当或更优,同时保持相似的音素时长精度。与 x-vector 相比,所提方法能够实现有效的语音节奏迁移,并取得更高的相似度评分,尤其在未见领域说话人上。
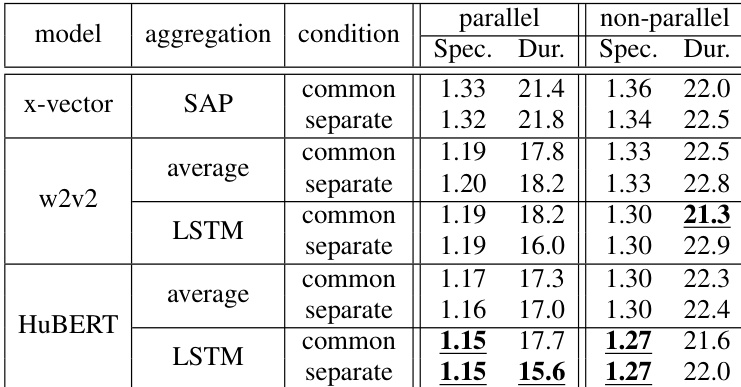
作者评估了在平行与非平行条件下采用 SSL 模型的所提零样本 TTS 方法,并与传统的 x-vector 方法进行比较。结果显示,所提方法在特定方面表现更优,尤其在捕捉基于节奏的说话人特征与实现语音节奏迁移方面,而其有效性因数据条件与模型配置而异。在平行与非平行条件下,所提方法在捕捉基于节奏的说话人特征方面均优于传统方法。所提方法能够实现有效的语音节奏迁移,这由更高的偏好评分及更接近参考语音的语速所证实。模型性能随训练数据与规模变化,在更大规模数据集上训练的大型模型在复现语音特征方面表现更佳。
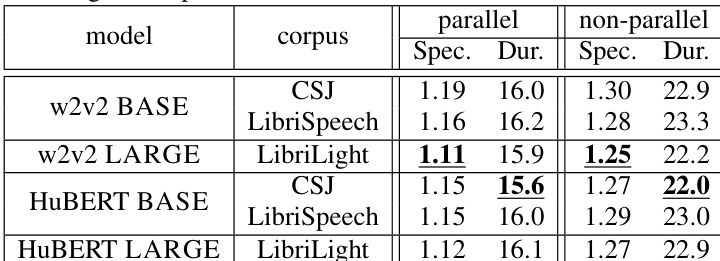
主观与客观评估在平行与非平行训练条件下,比较了利用 SSL 嵌入及独立声学与时长条件控制的所提零样本 TTS 框架与传统 x-vector 基线。实验分析验证了该架构通过为不同模型层分配不同角色,有效解耦了说话人的节奏与声学特征,其中较深层主要控制音素时长,较浅层捕捉声学特征。定性评估一致表明,所提方法在保持相当自然度的同时,实现了更优的语音节奏迁移、更高的听众偏好度,并提升了未见领域说话人的相似度。总体而言,研究结果证实,与传统说话人建模技术相比,解耦条件控制与优化的特征聚合显著增强了节奏保真度与跨条件泛化能力。