Command Palette
Search for a command to run...
多模态网络,CLIP 和 VQGAN
摘要
一句话总结
Vita-CLIP 提出了一种统一的跨模态提示学习方案,通过结合全局、局部和摘要视觉提示与文本提示,在监督学习与零样本视频动作识别之间取得平衡,在 Kinetics-600、HMDB51 和 UCF101 数据集上实现了最先进的零样本性能,同时保持了具有竞争力的监督学习准确率。
核心贡献
- 为解决视频识别中监督准确率与零样本泛化能力之间的权衡问题,提出了一种统一的跨模态提示学习框架,在无需对整个主干网络进行微调的情况下适配预训练的 CLIP 模型。
- 该方法实现了一种结构化的视觉侧提示机制,包含用于数据分布建模的全局视频级提示、用于逐帧判别的局部帧级提示,以及用于提取浓缩表示的摘要提示,并辅以可学习的文本侧提示以增强文本上下文。
- 该方法在 Kinetics-600、HMDB51 和 UCF101 上实现了最先进的零样本性能,同时在 Kinetics-400 和 Something-Something V2 上保持了具有竞争力的监督学习性能,且可训练参数量显著减少。
引言
以 CLIP 为代表的多模态模型在图像理解方面已展现出强大的零样本迁移能力,但由于处理连续帧的计算成本较高以及大规模视频-文本数据集的稀缺,将其适配至视频识别领域仍面临挑战。早期的适配方法通常需要在两者之间做出妥协,要么仅将提示学习应用于单一模态,要么对整个视觉主干网络进行全量微调,这不可避免地会以牺牲零样本泛化能力为代价来换取监督学习准确率。为了解决这一权衡问题,研究者提出了一种名为 Vita-CLIP 的统一多模态提示框架,该框架保持原始 CLIP 主干网络冻结,同时在视觉和文本编码器中注入轻量级的可学习提示。通过在视觉提示中构建全局、帧级和摘要表示以捕捉时空动态特征,并利用可适配的文本向量增强稀疏的视频类别标签,该方法在无需大量微调的情况下,有效平衡了监督学习性能与强大的零样本泛化能力。
方法
研究者利用预训练的 CLIP 模型来适配视觉-语言表示以用于视频理解,在保留原始模型泛化能力的同时实现出色的监督学习性能。该框架通过冻结预训练的视觉和文本编码器,并利用多模态提示方案引入可学习参数来运作。整体架构包含一个视频编码器和一个文本编码器,两者均源自 CLIP 模型,并采用余弦相似度目标来对齐视频与文本表示。
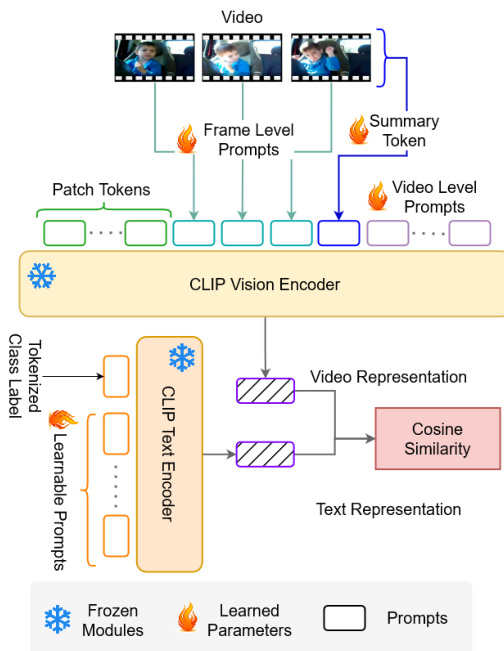
参见框架示意图。视频编码器处理帧序列 V∈RT×H×W×3,其中 T 表示帧数。每一帧被划分为 N 个大小为 P×P 的不重叠方形图块,这些图块被展平并通过线性层投影为 token 嵌入。每个帧的图块 token 序列前会添加一个分类 token xcls。生成的逐帧 token 序列在添加空间和时间位置编码后,输入到具有 Lv 层的视觉编码器进行处理。帧级表示通过从最后一层的输出中提取分类 token 并将其投影至较低维度 D′ 获得。最终的视频表示 v 通过对逐帧表示求平均得到。
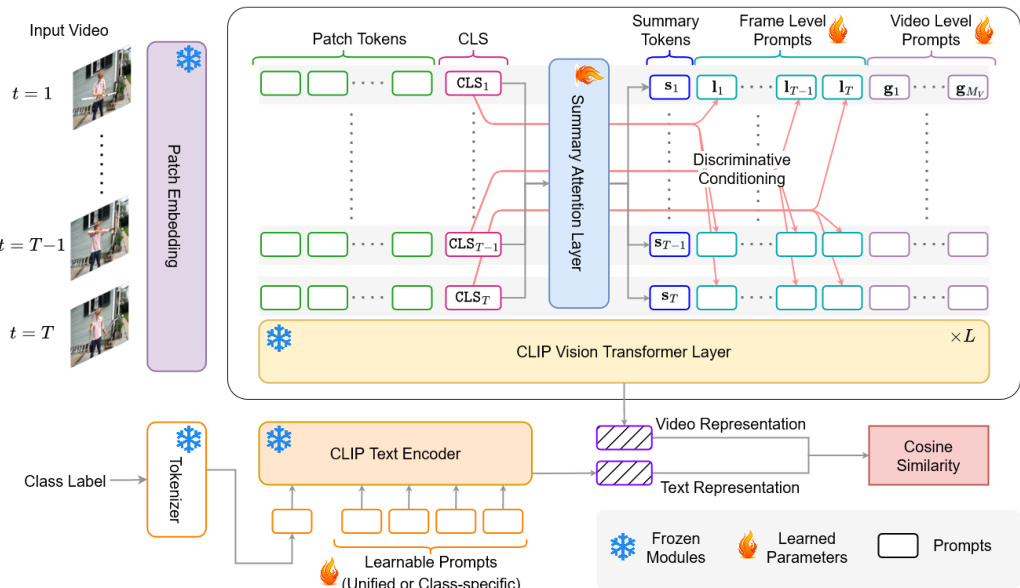
如图所示,视觉编码器提示学习方案在视觉 Transformer 的每一层 l 的 token 序列中引入了三种类型的可学习 token。单个摘要 token 用于聚合 clip 中所有帧的判别性信息,随后将其反馈至每一帧。该过程通过投影上一层的分类 token、执行多头自注意力(MHSA)操作,并将生成的摘要 token 附加到每一帧的 token 序列中(在冻结的自注意力层之前)来实现。此外,引入了 Mv 个视频级全局提示 token 作为随机初始化的可学习向量,以提供适配视频数据集分布的能力。帧级局部提示 token 的数量与帧数 T 相等,其以对应帧的分类 token 为条件,以增强判别性信息的流动。这些局部 token 定义为一个可学习向量与分类 token 之和。摘要 token、全局 token 和局部 token 会在冻结的自注意力操作之前附加到每一帧的序列中,并在注意力层之后移除这些额外 token,前馈网络仅应用于更新后的帧级 token。
在文本侧,采用提示学习方案来适配文本编码器。文本编码器的输入是一个包含可训练上下文向量和类别标签的 token 序列。研究者采用特定类别上下文(CSC)方案,为每个类别定义一组独立的训练向量。除零样本评估使用手动提示外,所有实验均使用这些特定类别的提示向量。文本编码器处理该 token 序列以生成文本表示 c。
学习目标是在正确的视频-文本对中最大化视频表示 v 与文本表示 c 之间的余弦相似度。这通过优化余弦相似度损失函数实现,该函数衡量两种表示在共享嵌入空间中的对齐程度。该框架允许在不微调预训练编码器的情况下高效适配视频任务,从而保留其强大的泛化特性。
实验
该模型在 Kinetics-400 上使用冻结的主干网络和轻量级提示方案进行训练,随后在多个基准测试上进行评估,以检验监督识别与零样本泛化能力。监督实验验证了该方法在显著降低计算开销的同时,相比全量微调方案取得了具有竞争力的准确率。零样本评估进一步证明,单一统一的训练协议能够有效适配未见过的类别,而无需单独的模型配置。互补的消融实验确认,集成的局部、全局和摘要提示成功引导网络聚焦于判别性时空特征,最终在任务特定性能与跨域适应能力之间建立了稳健的平衡。
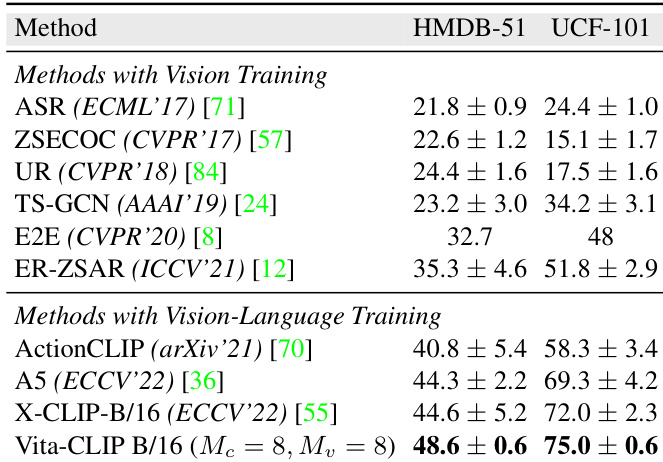
研究者展示了在 HMDB51 和 UCF101 数据集上的零样本性能对比,评估了仅使用视觉训练与视觉-语言训练的方法。结果表明,所提出的 Vita-CLIP 方法在视觉-语言训练方法中于两个数据集上均取得了最高准确率,优于以往方法。在视觉-语言训练方法中,Vita-CLIP 在 HMDB51 和 UCF101 上实现了最先进的性能。视觉-语言训练方法在 HMDB51 和 UCF101 上均优于仅视觉训练的方法。在视觉-语言方法中,Vita-CLIP 相较于以往方法在 HMDB51 和 UCF101 上均展现出显著改进。
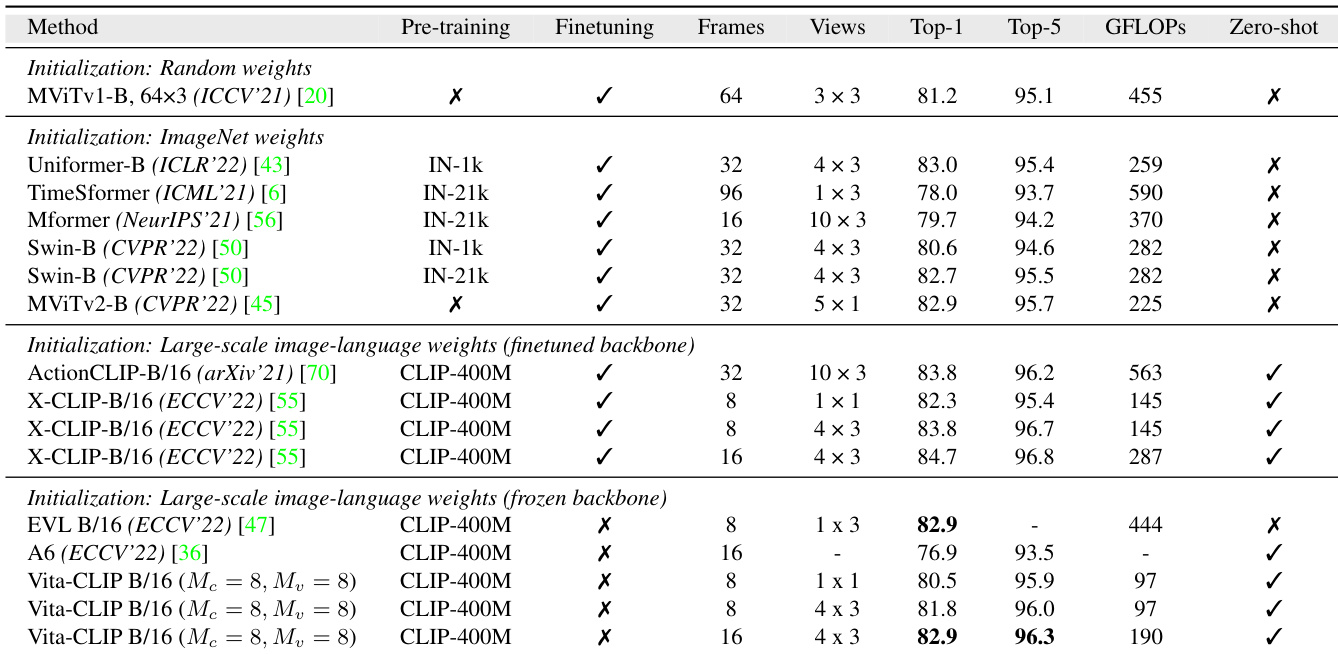
研究者在监督训练设置下将所提方法与多种最先进方法在 Kinetics-400 上进行对比,重点突出性能、计算效率与零样本能力。结果表明,该方法以显著更低的计算成本实现了具有竞争力或更优的准确率,并保留了零样本评估能力,优于需要微调或具有更高 FLOP 计数的方法。所提方法在保持主干网络冻结的同时,使用大幅减少的 FLOPs 实现了与现有方法相当或更优的准确率。该方法在零样本评估中优于基线模型,在其他方法无法保持能力的情况下仍能稳定输出。该方法在不同初始化策略下均表现出强劲性能,尤其在大规模图像-语言预训练与冻结主干网络的设置下。
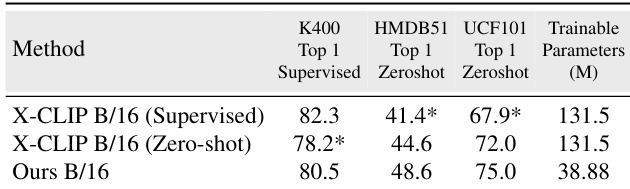
研究者在 K400、HMDB51 和 UCF101 的监督与零样本设置下,将所提方法与 X-CLIP 进行对比,展示了在两种场景下更优的性能,同时使用了显著更少的可训练参数。该方法在一致条件下仅使用单一模型训练,便在两种设置下均取得了高于 X-CLIP 的准确率,避免了单独配置训练流程的需求。该方法在不牺牲监督学习性能的前提下保持了强大的零样本能力,凸显了两种模式之间的平衡权衡。所提方法在 K400、HMDB51 和 UCF101 的监督与零样本设置中均优于 X-CLIP。它在两种设置下均以大幅减少的可训练参数实现了更高的准确率。与需要不同配置的 X-CLIP 不同,该方法仅使用单一模型和训练设置即可完成监督与零样本评估。
研究者对所提方法中不同视频提示组件的影响进行了消融实验。结果表明,添加全局视频级提示可提升性能,进一步引入局部帧级提示和摘要 token 会带来额外增益,表明这些组件具有互补性并共同提升模型准确率。当同时使用三种提示类型时,性能达到最佳。添加全局视频级提示可提升基线性能。引入局部帧级提示可进一步提高准确率。在全局与局部提示的基础上结合使用摘要 token,可获得最高性能。
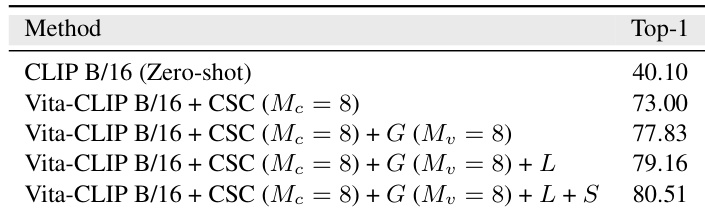
研究者在监督训练设置下将 Vita-CLIP 与现有方法在 Kinetics-400 上进行对比,突出其以更低计算成本实现具有竞争力的性能,并保留零样本能力。结果表明,Vita-CLIP 在参数量更少且能泛化至未见类别的情况下,优于其他采用冻结主干的方法。与微调主干的方法相比,Vita-CLIP 在冻结主干且计算成本更低的情况下取得了具有竞争力的 top-1 准确率。Vita-CLIP 支持零样本评估,而许多其他方法需要微调主干且无法用于零样本识别。在采用冻结主干的方法中,Vita-CLIP 在相同基准测试上的性能高于 B2 及其他方法。

评估设置涵盖多个视频识别基准测试的监督与零样本场景,通过与既定基线对比验证了该方法的准确率、计算效率与参数经济性。对比实验确认,该框架在保持主干网络冻结且仅需单一统一训练配置的情况下,持续优于以往方法;消融实验进一步验证,结合全局视频、局部帧级与摘要提示能够产生互补的性能提升。总体而言,研究结果表明,所提方法在无需牺牲监督学习准确率的前提下,以显著降低的计算开销和强大的零样本泛化能力实现了最先进的识别性能。