Command Palette
Search for a command to run...
全景一键分割:应用于农业数据
全景一键分割:应用于农业数据
Patrick Zimmer Michael Halstead Chris McCool
一键部署 Llama-3.3-70B-Instruct
摘要
在杂草控制中,精准农业有助于大幅减少除草剂的使用,从而带来经济和环境效益。其中的关键要素是从图像数据中定位并分割所有植物(作物和杂草)。现代实例分割技术可以实现这一目标,然而训练此类系统需要大量的人工标注数据,获取成本高且耗时费力。弱监督训练可以显著减少标注工作量和成本。本文提出了一种全景一键分割方法,这是一种高效且准确的离线工具,能够从点击输入生成伪标签,从而在新数据集创建过程中减少标注工作量。与传统的独立迭代处理场景中所有 N 个对象的方法不同,我们的方法联合估计场景中所有 N 个对象的像素级位置。这导致了一种高度高效的技术,大大缩短了训练时间。仅使用 10% 的数据来训练我们提出的全景一键分割方法,在具有挑战性的甜菜和玉米图像数据上分别取得了 68.1% 和 68.8% 的平均对象交并比(IoU),提供了与传统一键方法相当的性能,同时训练速度大约快 12 倍(一个数量级)。我们通过为剩余 90% 的数据从点击标注生成伪标签,展示了我们系统的实际应用价值。这些伪标签随后以半监督方式用于训练 Mask R-CNN,使甜菜和玉米数据的平均前景 IoU 绝对性能分别提高了 9.4 和 7.9 个百分点,证明了我们这种方法快速标注挑战性数据的潜力。最后,我们表明我们的全景一键分割技术在标注勾勒过程中能够恢复遗漏的点击,这进一步体现了其相对于传统方法的优势。
一句话总结
作者提出全景单点击分割(Panoptic One-Click Segmentation)方法,这是一种弱监督技术,通过联合估计场景中所有目标来生成基于点击的伪标签。该方法在仅使用10%标注数据的情况下,将训练时间缩短了一个数量级,在甜菜和玉米数据集上分别达到68.1%和68.8%的平均目标IoU,并在半监督训练中使Mask R-CNN的前景IoU分别提升了9.4和7.9个点。
核心贡献
- 该研究提出一种全景单点击分割框架,利用稀疏点击输入生成伪标签,以降低农业植物分割中的手动标注成本。
- 该方法同时联合估计场景中所有目标的像素级位置,取代传统的独立迭代处理流程,从而大幅缩短训练时间。
- 在甜菜和玉米数据集上的评估表明,仅使用10%标注数据进行训练即可达到68.1%和68.8%的平均目标IoU,运行速度约为基线方法的12倍,且生成的伪标签使下游Mask R-CNN的前景IoU分别提升了9.4和7.9个点。
引言
精准农业依赖于准确的植物分割以实现靶向除草并减少除草剂使用,但训练此类视觉系统传统上需要昂贵的像素级标注。现有的弱监督方法通过稀疏输入(如单次点击)生成伪标签,但由于在多次前向传播中独立处理每个目标,计算效率仍然较低。作者利用全景分割技术,在单次前向传播中仅凭每个实例的一次点击即可联合解析场景中的所有目标,从而构建出一种高效离线的标注工具。该方法将模型训练速度提升了一个数量级,并为绝大多数农业数据集成功生成了高质量伪标签,在几乎无需人工干预的情况下大幅提升了下游实例分割性能。
数据集
- 组成与来源: 作者在两个农业除草数据集(SB20与CN20)上评估该方法,数据集中包含多种类、多尺寸且频繁重叠的植物实例图像。
- 子集细节: 两个数据集的标注均包含关键点或茎部位置,用作交互式点击目标。由于遮挡或位于图像边缘,SB20中有63个实例和CN20中有30个实例缺乏明确的关键点。
- 训练策略与划分: 作者实现了一种半监督工作流,在少量手动标注数据上进行训练。每个数据集分配10%用于手动监督,并利用基于该10%划分训练出的模型为剩余90%生成伪标签。
- 处理与输入生成: 对于未预定义关键点的植物,作者计算二值掩码的质心以确定点击坐标。若该点落在掩码外部,则应用迭代二值腐蚀操作直至目标消失,并从倒数第二次迭代中随机选取一个坐标,以保证其位于有效范围内。训练期间,作者在点击位置上下增加10像素的随机噪声,以模拟人工标注的不确定性,同时确保坐标点保持在目标区域内。
方法
作者基于全景分割框架构建了一种新型单点击分割系统,该系统在单次前向传播中联合估计图像内所有目标的位置,相较于传统方法显著降低了计算开销。所提方法基于Panoptic-Deeplab模型,该模型通过生成三种输出将语义分割与实例分割相结合:语义分割图、中心偏移图和对象中心图。语义图将每个像素分类至特定类别,区分“things(可数目标,如植物)”与“stuff(不可数区域,如背景或纹理)”。中心图标识每个目标的中心位置,偏移图则提供指向最近目标中心的逐像素位移向量,从而在后处理阶段将像素正确分配至对应实例。
基线单点击分割方法独立处理每个目标,对图像中的 N 个目标需要执行 N 次前向传播。该方法将高斯编码点击变换图作为额外输入通道传入编码器-解码器网络,其中每次点击表示为标准差为8的二维高斯分布。当存在多个目标时,该流程会对每个正样本点击重复执行,并可额外将来自其他目标的负样本点击编码至次级点击图中以增强场景理解。然而,由于需重复处理同一图像,该迭代过程计算成本较高。
相比之下,所提出的全景单点击分割系统通过改进Panoptic-Deeplab架构实现单次前向传播。输入由RGB图像与点击变换图组成,该变换图既作为网络输入,也作为目标中心的地面真值。网络经过修改,仅预测两种输出:语义分割图与中心偏移图。目标中心估计分支被禁用,用户提供的点击位置在后处理阶段直接作为中心坐标使用,具体架构如图所示 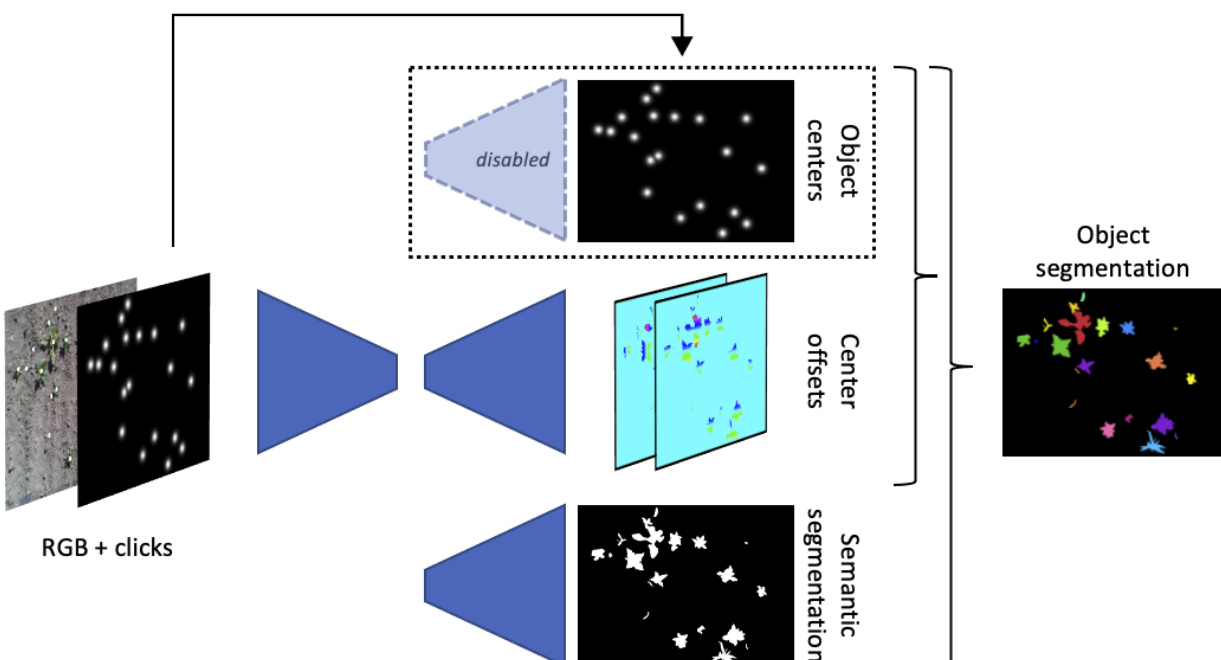 。该设计无需网络预测目标中心,简化了推理流程,并支持对所有目标进行联合处理。
。该设计无需网络预测目标中心,简化了推理流程,并支持对所有目标进行联合处理。
此外,该系统可通过重新引入目标中心估计分支作为第三种输出,扩展以修复缺失点击等标注错误。在此变体中,网络直接预测目标中心,即使用户输入不完整也能估计缺失的点击位置。点击图仍作为输入通道保留,但不再用于后处理,因为网络预测的中心坐标将替代原始标注。该改进在保持单次推理效率的同时,增强了对标注噪声的鲁棒性。整体架构将这些组件整合为统一框架,能够在单次前向传播中高效处理多个目标,具体结构如图所示 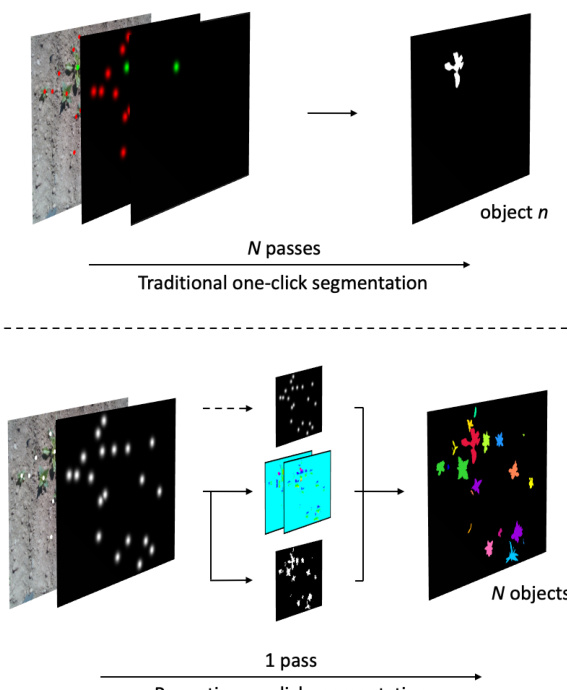 。
。
实验
评估包含三项实验,旨在农业数据集上对比新型全景单点击分割框架与传统方法。第一项实验验证了通用分割性能与训练效率,表明全景方法能天然避免目标重叠,在保持相当精度的同时显著加快训练速度。后续实验验证了该框架在半监督学习中的实用性及其对缺失输入的鲁棒性,证明其能够从极少标注中有效生成高质量伪标签,并在绝大多数用户点击缺失的情况下成功恢复目标位置。综合结果表明,全景方法是一种高效且具备强韧性的工具,可加速数据集构建与标注恢复。
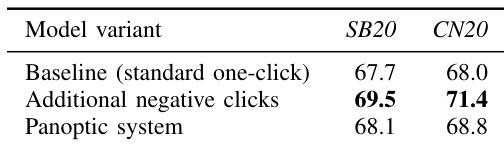
作者对比了以不同单点击分割方法作为伪标签来源时的半监督实例分割性能。结果表明,使用单点击模型生成的伪标签相比仅使用少量手动标注数据能提升性能,其中全景方法取得了具有竞争力的结果。全景系统对缺失输入点击表现出鲁棒性,即使在大量点击缺失的情况下仍能维持识别质量。与仅使用少量手动标注子集相比,使用单点击模型伪标签改善了实例分割性能。全景单点击系统达到了接近全监督基线的性能,且在部分场景下优于标准单点击方法。全景系统在输入点击大量缺失时仍能保持识别质量,表明其对缺失标注具有强鲁棒性。

作者对比了传统单点击分割方法与所提出的全景单点击方法,并在两个数据集上评估了性能。结果显示,全景系统以显著更快的训练速度达到了具有竞争力的分割精度,并对缺失输入点击表现出鲁棒性。全景方法在半监督学习任务中同样表现良好,生成的伪标签有效提升了实例分割性能。与基线方法相比,全景单点击系统在大幅缩短训练时间的同时实现了具有竞争力的分割性能。该全景方法减少了传统单点击系统中常见的重叠错误,并在输入点击缺失时展现出良好的鲁棒性。在半监督学习中,全景系统生成的伪标签相比仅使用少量手动标注数据,显著提升了实例分割性能。
作者通过在不同缺失点击比例下对比性能指标,评估了全景单点击分割系统从缺失输入点击中恢复的能力。结果表明,即使在大量点击缺失的情况下,系统仍能维持较高的识别质量,且性能仅随缺失点击比例的增加而缓慢下降。系统在目标中心估计方面表现出鲁棒性,预测中心产生的结果与用户提供的点击结果相近。全景系统在输入点击大量缺失时仍能保持高识别质量。随着缺失点击比例上升,性能呈渐进式下降,但在缺失75%点击时识别质量依然显著。当使用网络预测中心时,系统达到了与用户点击相当的识别质量,表明其具备强大的目标定位能力。

实验在两个数据集上将所提出的全景单点击分割系统与基线方法(传统方法与全监督方法)进行对比,以评估训练效率、分割精度及对不完整输入的韧性。第一组测试验证了该系统在半监督实例分割中的有效性,证明其生成的伪标签相比极少手动标注能大幅改善性能,并接近全监督水平。附加评估考察了模型处理缺失用户交互的能力,确认即使在绝大多数点击缺失的情况下,系统仍能维持高识别质量、最小化重叠误差并准确估计目标中心。总体而言,研究结果确立了全景方法作为一种更快、更精准且高度鲁棒的交互式分割任务替代方案。