Command Palette
Search for a command to run...
朗读与自发语音合成中自监督语音表示的比较研究
朗读与自发语音合成中自监督语音表示的比较研究
Siyang Wang Gustav Eje Henter Joakim Gustafson Éva Székely
语音表示和数据探索
摘要
最近的研究探索了在标准两阶段文本转语音(TTS)系统中,使用如 wav2vec2.0 等自监督学习(SSL)语音表示作为表征媒介,以替代传统使用的梅尔频谱图。然而,目前尚不清楚哪种 SSL 语音表示更适合 TTS,以及其在朗读和自发语音合成中的性能是否存在差异,后者被认为更具挑战性。本研究通过在朗读和自发语料库上的两阶段 TTS 任务中测试多种 SSL 模型(包括同一 SSL 的不同层),同时保持 TTS 模型架构和训练设置不变,来回答这些问题。听力测试结果表明,12 层 wav2vec2.0(经过自动语音识别微调)的第 9 层在朗读和自发语音合成中均优于其他 tested SSL 模型及梅尔频谱图。我们的工作揭示了 SSL 如何能够轻易提升现有 TTS 系统的性能,并比较了不同 SSL 在具有挑战性的生成式任务 TTS 中的表现。
一句话总结
在模型架构和训练设置保持不变的情况下,针对朗读语料库和自发语料库进行的听觉测试表明,使用自监督语音表示替代梅尔频谱图能够提升两阶段文本到语音合成效果。其中,经过ASR微调的wav2vec2.0第九层的表现优于所有其他测试过的SSL模型及梅尔频谱图。
核心贡献
- 本研究评估了多种语音自监督学习模型及其中间层,探讨其作为两阶段文本到语音系统(在朗读与自发语料库上训练)中梅尔频谱图的直接替代方案的效果。
- 对比分析表明,与最终层或传统声学特征相比,经过ASR微调架构的中间层能够生成更优的生成式表示,从而确立了层深度作为合成适用性的关键决定因素。
- 主观听觉测试与客观重合成指标证实,12层wav2vec2.0模型的第九层始终优于所有基线模型,且自监督特征在自发语音合成中带来了尤为显著的质量提升。
引言
现代两阶段文本到语音系统传统上依赖梅尔频谱图作为中间声学目标,但研究人员正越来越多地采用wav2vec2.0等自监督学习表示,以利用海量无标签音频数据集并提升合成质量。先前的研究在确定何种SSL架构或内部层能够优化语音生成方面仍存在关键空白,且现有方法仅针对剧本朗读语音,忽视了包含传统文本对齐模型难以捕捉的复杂发声现象的自发语音。作者系统评估了多种SSL模型及层配置在两阶段TTS流水线中针对朗读与自发语料库的表现。研究证明,经过ASR微调的wav2vec2.0第九层始终优于梅尔频谱图及其他SSL变体,揭示出SSL特征能为自发语音带来更大的质量增益,并表明中间重合成误差并不能可靠地预测最终音频质量。
数据集
- 数据集构成与来源: 该语料库将广泛使用的LJSpeech朗读语料库与Trinity Speech-Gesture Dataset(TSGD)自发语音语料库相结合。
- 子集详情: LJSpeech子集提供标准朗读录音。TSGD子集包含25段即兴独白,平均每段10.6分钟,由一名男演员以口语化风格录制。
- 处理与裁剪策略: 为准备TTS音频,作者将录音按自然呼吸事件划分为语音片段。随后采用重叠拼接方法将这些片段组合,形成连续的语流结构。
- 训练用途: 处理后的数据用于训练朗读与自发TTS模型。引入呼吸感知分割与重叠拼接技术,旨在保留自然韵律并确保生成过程中的声学过渡平滑。
方法
作者采用基于神经声学模型与声码器的两阶段语音合成框架,整体系统结构如下图所示。第一阶段采用基于并行Transformer的文本到语音(TTS)模型FastPitch 1.1,该模型改编自先前研究,并通过单调对齐机制增强,以从输入文本生成梅尔频谱图。该阶段使用与参考工作相同的超参数进行训练,批次大小(batch size)为96,持续训练直至验证损失收敛,在LJSpeech语料库上通常需要约200个epoch。针对TSGD等较小规模的自发语音数据集,作者从预训练的LJSpeech模型初始化训练,并额外微调200个epoch,从而显著提升合成质量。
第二阶段为声码器(具体为HiFi-GAN),负责将声学模型生成的梅尔频谱图转换为波形。该阶段的训练设置与参考工作类似,训练批次由0.5秒的随机音频片段组成。批次大小根据表示的维度与采样率在160至192之间调整,以确保各模型在单次迭代中的数据吞吐量保持一致。对于LJSpeech,基于SSL的声码器在22 kHz采样率下训练18万次迭代;针对自发语料库的声码器则从随机初始化开始,在16 kHz采样率下训练10万次迭代。该系统还结合了梅尔频谱图L1损失与波形GAN损失,以指导高保真波形的生成。
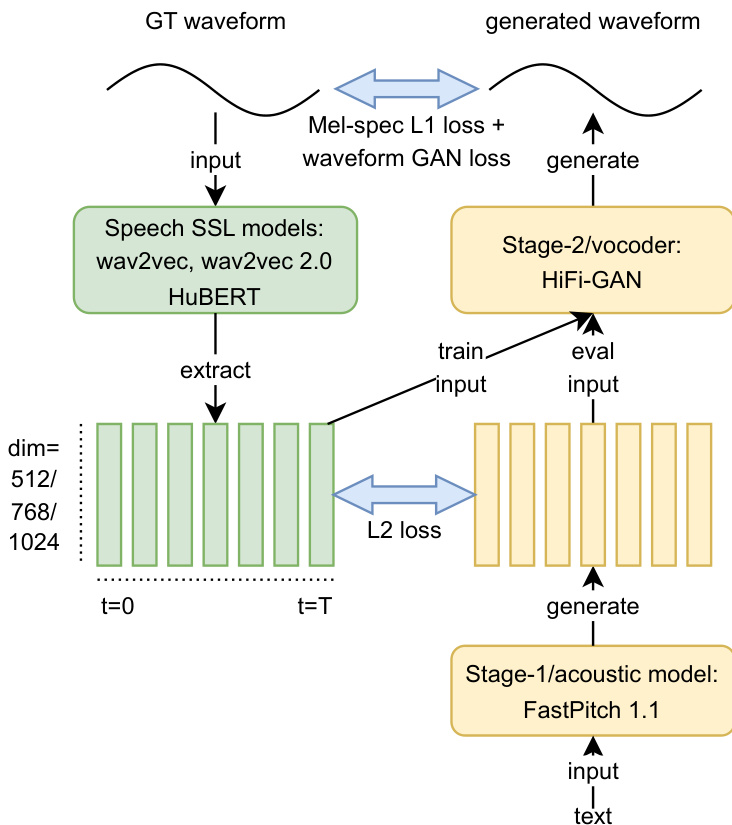
输入语音波形首先通过语音自监督学习(SSL)模型(如wav2vec、wav2vec 2.0或HuBERT)进行处理,以提取潜在表示。随后,这些表示被输入至第二阶段声码器以生成波形。该框架还包含一个反馈回路,将生成的波形与真实波形进行对比,并通过最小化生成波形与目标波形提取特征之间的L2损失来训练模型。此举实现了整个系统的端到端优化,其中SSL模型充当声码器的特征提取器。
实验
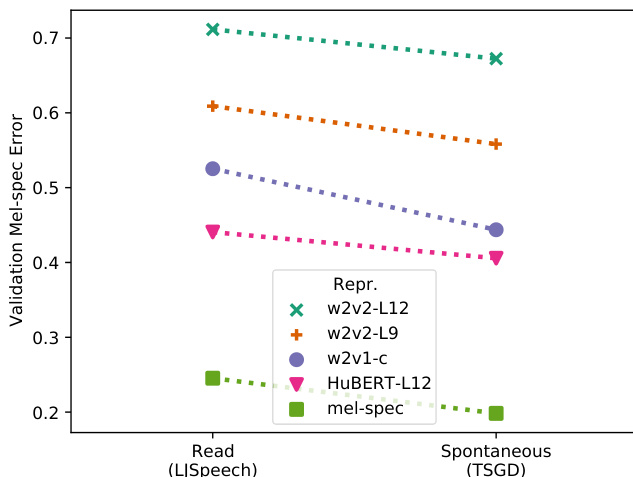
本研究在两阶段文本到语音流水线中,将四种语音自监督学习模型及特定内部层与标准梅尔频谱图进行对比评估。重合成测试验证了波形重建能力,对比听觉评估则衡量了朗读与自发语音的主观合成质量。结果一致表明,wav2vec2.0第九层显著优于其他所有表示方法,且自发语音合成对该特征集的偏好更为强烈。最终研究指出,重建精度与合成质量并无直接关联,凸显出自监督表示作为传统频谱图的高效替代方案,尤其适用于难度较高的自发语音生成任务。
作者对比了多种用于两阶段TTS流水线的语音自监督学习(SSL)表示,评估了重合成质量与主观TTS性能。结果表明,wav2vec2.0的特定层在朗读与自发语音合成中均优于其他SSL模型及梅尔频谱图,且性能差距在自发语音中更为明显。w2v2-L9在朗读与自发语音TTS任务中均超越所有其他测试过的SSL表示与梅尔频谱图。SSL表示的重合成性能无法预测其整体TTS表现。与朗读TTS相比,w2v2-L9相较于梅尔频谱图的优势在自发TTS中显著更大。
作者对比了多种用于两阶段TTS流水线的语音SSL表示,重点涵盖朗读与自发语音。听觉测试结果指出,特定SSL表示w2v2-L9在两种语音类型中均稳定优于其他SSL模型与标准梅尔频谱图,印证了其作为TTS中间表示的有效性。w2v2-L9在朗读与自发TTS中均优于其他SSL模型及梅尔频谱图。相较于朗读TTS,自发TTS对w2v2-L9的偏好程度更高。重合成性能无法预测整体TTS表现。
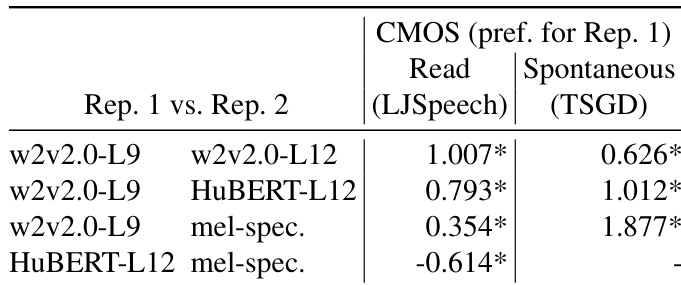
作者对比了多种作为两阶段TTS流水线表示的语音自监督学习(SSL)模型,同时使用朗读与自发语音语料库。结果表明,wav2vec2.0第九层在两种设置下均优于其他SSL模型与传统梅尔频谱图,尽管其重合成性能并非最优。研究强调重合成质量不一定能预测TTS表现,并指出SSL模型(尤其是wav2vec2.0-L9)在自发语音合成中具有广阔前景。wav2vec2.0第九层在朗读与自发语音TTS中均超越所有其他测试SSL及梅尔频谱图。重合成性能与TTS表现无直接关联,表明SSL表示的不同维度对合成具有不同的重要性。wav2vec2.0-L9在自发TTS中获得的偏好度高于朗读TTS,印证了其在自然语音合成中的适用性。
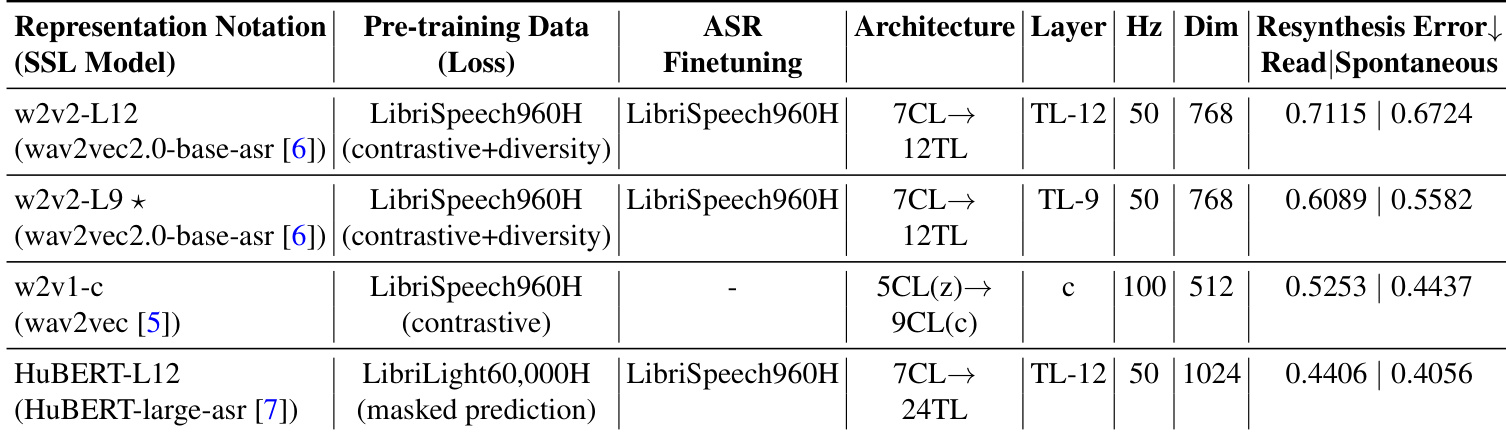
该评估在两阶段TTS流水线中对比了多种语音自监督学习表示,通过音频重合成与主观听觉测试验证了其在朗读与自发语音中的有效性。结果证明,wav2vec2.0第九层持续产出优于其他SSL模型与梅尔频谱图的合成质量,且其在自发语音中的性能优势尤为突出。关键的是,研究发现重合成保真度无法预测整体TTS质量,表明不同的表示特征共同驱动了自然语音生成。这些定性结论确立了wav2vec2.0第九层作为构建稳健TTS系统的高效中间表示方案。