Command Palette
Search for a command to run...
超越最佳:在蛋白质结构预测中改进AlphaFold2
超越最佳:在蛋白质结构预测中改进AlphaFold2
Abbi Abdel-Rehim Oghenejokpeme Orhobor Hang Lou Hao Ni Ross D. King
一键部署 AlphaFold2
摘要
蛋白质结构预测(PSP)问题的目标是根据氨基酸序列预测蛋白质的三维结构。自Anfinsen获得诺贝尔奖的研究证明蛋白质构象由序列决定以来,该问题一直是科学的“圣杯”。迈向这一目标的一个近期且重要的步骤是AlphaFold2的开发,它目前是最佳的PSP方法。AlphaFold2可能是AI应用于科学领域中最具影响力的应用之一。AlphaFold2和RoseTTAFold(另一种令人印象深刻的PSP方法)均已发表并公开(代码和模型)。Stacking是一种集成机器学习(ML)形式,其中首先学习多个基线模型,然后利用基线模型的输出学习一个元模型,从而形成优于基线模型的性能。Stacking在许多应用中取得了成功。我们通过堆叠AlphaFold2和RoseTTAFold开发了ARStack PSP方法。ARStack显著优于AlphaFold2。我们使用两组非同源蛋白质以及一组在AlphaFold2和RoseTTAFold之后发表的蛋白质结构测试集,严格证明了这一点。随着更多高质量预测方法的发布,集成方法很可能越来越超越任何单一方法。
一句话总结
作者提出了 ARStack,这是一种蛋白质结构预测方法,采用堆叠集成学习整合 AlphaFold2 和 RoseTTAFold。在两个非同源蛋白质集合及基座模型发布后公开的结构测试集上,该方法显著优于 AlphaFold2。
核心贡献
- 本文提出 ARStack,一种堆叠集成方法,将 AlphaFold2 和 RoseTTAFold 作为基线预测器进行结合。通过训练神经网络元模型,学习基线预测结果与真实蛋白质构象之间的映射关系。
- 该集成架构在预测蛋白质三维结构方面显著优于独立的 AlphaFold2 模型。
- 评估采用两个非同源蛋白质集合以及基线模型发布后的结构测试集。该基准测试证实了堆叠方法对未见目标的泛化能力。
引言
从氨基酸序列预测蛋白质的三维结构仍是计算生物学的一项基础挑战,因为结构准确度直接决定了功能解析与药物发现的可行性。尽管 AlphaFold2 和 RoseTTAFold 等深度学习模型极大地推动了该领域的发展,但各自均存在互补的优势与偶发的误差,限制了单一模型的可靠性。为解决这一问题,作者利用堆叠集成机器学习将这两种顶级预测器结合为 ARStack,即一种能够综合两者独立输出的神经网络元模型。通过在包含基座模型发布后公开蛋白质的多样化测试集上进行训练,ARStack 始终优于单独的 AlphaFold2,表明集成策略能够可靠地将预测精度推向当前技术的前沿。
数据集
-
数据集构成与来源: 作者从 RCSB PDB 构建了三组蛋白质数据集,筛选条件为至少包含 50 个氨基酸且具有唯一 Uniprot 登录号的结构。利用 UniProtKB 家族注释将蛋白质划分为同源集合。数据集 1 和 2 由具有医学相关性的人类蛋白质组成,数据集 3 则包含结构预测器首次发布后公开的结构。
-
子集详情: 数据集 1 包含每个同源集合中随机选取的一个蛋白质。数据集 2 包含每个集合中随机选取的两个蛋白质。数据集 3 作为时间预留集,用于评估对新结构的泛化能力。完整的蛋白质清单见补充材料。
-
训练用途与处理: 作者使用这些数据集训练并评估 ARStack 模型。应用序列比对与靶向截断,以确保预测序列与实验序列完全匹配。随后通过 BioPython 利用奇异值分解将预测结构叠加至实验结构,并提取转换后的坐标用于下游任务。
-
目标构建与原子处理: 作者通过计算每个原子在 AlphaFold2 与 RoseTTAFold 坐标之间的向量来求解目标值。模型训练目标是预测每个向量上最接近实验坐标的位置,目标值定义为到达该最优点的距离与方向。由于 RoseTTAFold 仅输出骨架原子,该流程仅处理每个残基的三个原子,使目标列的维度扩展为输入描述符的三倍。
方法
作者采用了一个机器学习框架,该框架始于基于多序列比对(MSAs)构建特征描述符。该过程的核心是从 Uniref90 MSA 中提取位置信息,为蛋白质链中的每个氨基酸生成丰富的表示。对于每个位置,计算比对序列中 20 种标准氨基酸与空位字符的比例,形成 21 维向量。该向量捕捉了该位点的进化保守性与变异性。为融入局部上下文,每个位置的向量与其前后各 10 个位置的向量进行拼接,为中心位置生成包含 431 个单元的 descriptor。对于靠近链末端且缺乏侧翼残基的位置,使用零填充向量以保持维度一致。 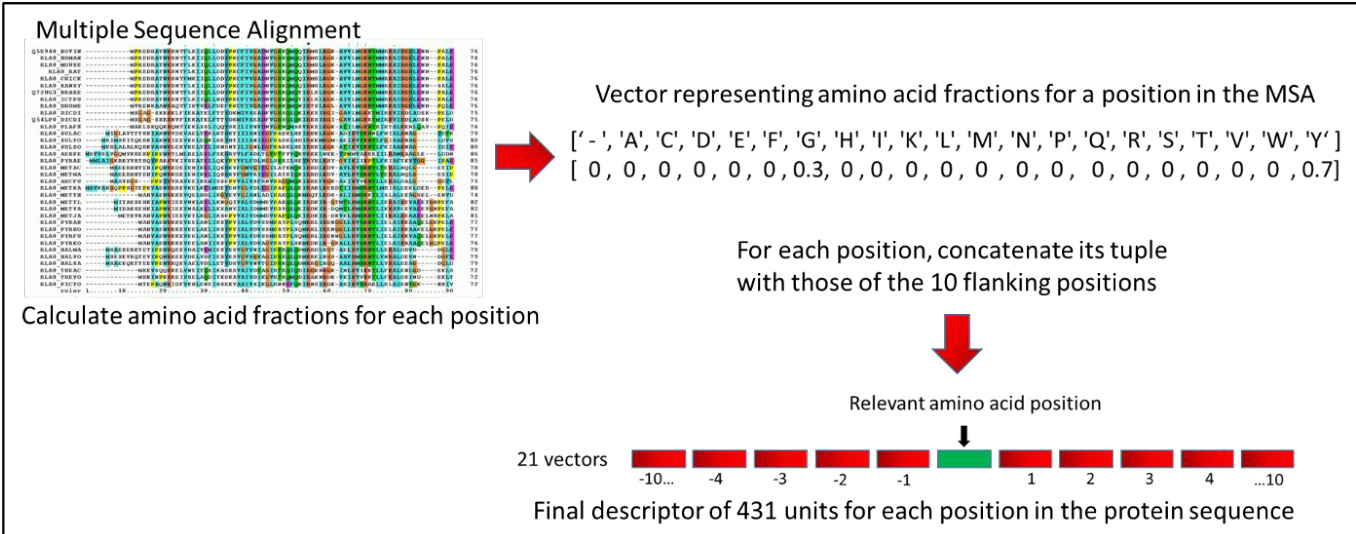
构建的描述符作为输入,送入使用 TensorFlow 和 Keras 实现的深度神经网络(DNN)架构。该网络包含四层:与描述符维度匹配的 431 神经元输入层;分别包含 200、200 和 100 神经元的三个隐藏层;以及用于预测目标值的单神经元输出层。隐藏层之间应用 0.2 的 dropout 率以缓解过拟合。前两个隐藏层使用线性整流单元(ReLU)激活函数,第三个隐藏层采用 softmax,表明这是一项分类任务。模型使用随机梯度下降进行训练,学习率为 0.01,并以均方误差作为损失函数进行优化。训练共进行三个 epoch,批次大小为 150 个样本。模型评估采用留一法交叉验证策略,依次留出每个蛋白质进行测试。 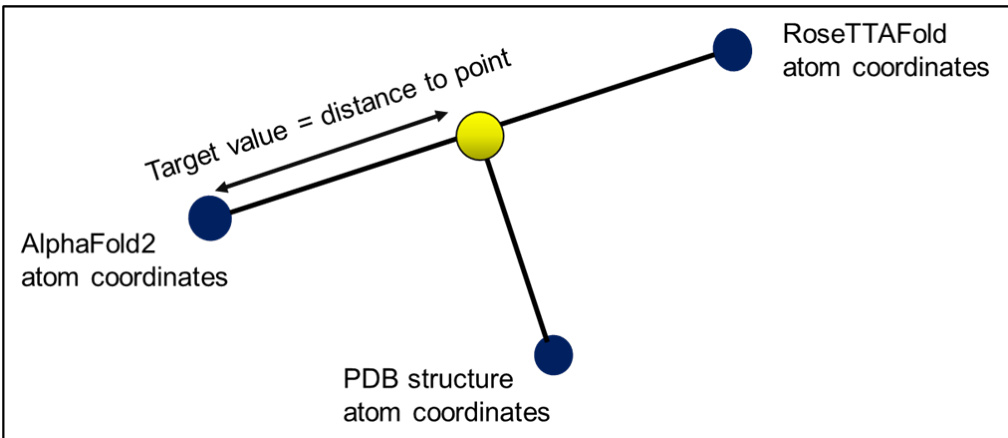
实验
评估将结合 AlphaFold2 与 RoseTTAFold 的堆叠集成方法与单独的 AlphaFold2 进行对比,利用三个独立数据集验证通用预测准确度、同源训练结构的影响以及针对训练数据泄露的鲁棒性。定性分析表明,堆叠方法始终优于单一模型,为具有挑战性的目标以及更小、更灵活的蛋白质提供了最可靠的性能提升。最终结果表明,整合互补型预测器能有效修正单一模型的局限性,确立了基于集成策略的未来蛋白质结构预测的重要发展方向。
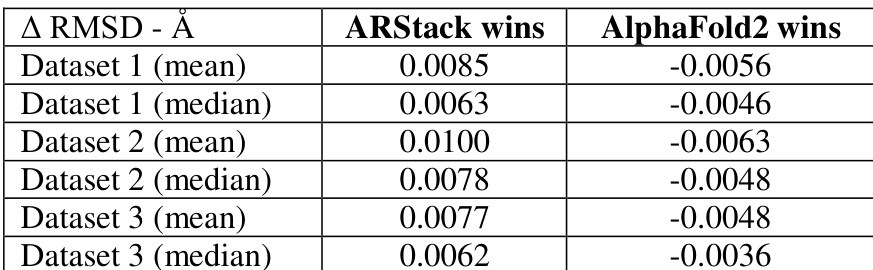
作者在三组数据集上对比了 ARStack 与 AlphaFold2 的性能,结果显示 ARStack 在 RMSD 改善方面始终取得更优结果。分析表明,ARStack 在多数情况下优于 AlphaFold2,且在 AlphaFold2 预测准确度较低的蛋白质(尤其是较小蛋白质)中增益更为显著。所有数据集的结果均具有统计学显著性,印证了堆叠方法的有效性。ARStack 在所有数据集上均实现比 AlphaFold2 更好的 RMSD 改善。对于 AlphaFold2 预测不准确的蛋白质,ARStack 提供了更明显的性能提升。ARStack 的优势在较小蛋白质中更为突出,在较低分子量区间表现出更高的胜率。
作者分析了 ARStack 与 AlphaFold2 在不同分子量范围内的性能,发现 ARStack 在较小蛋白质中表现更为稳定且优于 AlphaFold2。结果表明,ARStack 在较低分子量类别中的成功率更高,且观察到具有统计学显著性的提升。在分子量低于 20k 的蛋白质中,ARStack 的胜率高于 AlphaFold2。ARStack 的性能优势在较小蛋白质中更为明显,且提升具有统计学显著性。ARStack 在所有分子量类别中均稳定优于 AlphaFold2,其中最小蛋白质的相对收益最大。

作者跨多个数据集对比了 ARStack 与 AlphaFold2 的性能,发现 ARStack 在结构预测准确度方面始终优于 AlphaFold2。该提升在较小蛋白质以及 AlphaFold2 预测准确度较低时尤为显著,ARStack 在这类情况下提供了更大的修正幅度。ARStack 在所有数据集上均稳定优于 AlphaFold2,且提升在较小蛋白质及 AlphaFold2 预测不准时更为明显。ARStack 的收益在 AlphaFold2 预测较差(表现为初始 RMSD 值较大)的案例中最为显著。蛋白质尺寸与灵活性同 ARStack 的有效性相关,较小且更灵活的蛋白质从堆叠方法中获得的改善更大。

作者分析了 ARStack 与 AlphaFold2 在不同蛋白质分子量范围内的性能,显示 ARStack 始终优于 AlphaFold2,且在较小蛋白质中优势更强。结果表明,堆叠带来的改善在 10kDa 以下的蛋白质中更为显著,ARStack 在此类案例中的胜率显著更高。统计分析证实了这些发现的显著性,尤其针对较小蛋白质。ARStack 在所有分子量范围内均优于 AlphaFold2,且在较小蛋白质中优势更明显。ARStack 的改善对 10kDa 以下的蛋白质最为显著,其胜率大幅领先。统计分析进一步证实了 ARStack 优越性能的统计学意义,尤其在较小蛋白质中。

作者在三组数据集上对比了结合 AlphaFold2 与 RoseTTAFold 的堆叠方法 ARStack 与 AlphaFold2。结果显示,ARStack 在多数情况下优于 AlphaFold2,其中两个数据集的改善具有统计学显著性,第三个数据集呈现显著性趋势。性能提升在较小蛋白质以及 AlphaFold2 预测准确度较低时更为明显。ARStack 在所有三个数据集上均优于 AlphaFold2,其中两个数据集的改善达到统计学显著水平。ARStack 的性能增益在较小蛋白质及 AlphaFold2 预测不准时更为突出。与 AlphaFold2 相比,ARStack 的胜率百分比更高,且该差异在数据集 1 中最为显著。

实验在三组数据集上对堆叠方法 ARStack 与 AlphaFold2 进行了评估,通过跨不同分子量范围与基线准确度的对比分析验证了该方法的有效性。结果表明,ARStack 持续改善结构预测性能,其中在更小、更灵活的蛋白质以及原始模型表现较差的案例中收益最为显著。这些发现证实,堆叠策略能有效修正结构误差,并为多样化的蛋白质目标提供稳健且具统计学显著性的性能提升。