Command Palette
Search for a command to run...
使用神经网络自动检测和分类类人猿叫声
使用神经网络自动检测和分类类人猿叫声
Zifan Jiang Adrian Soldati Isaac Schamberg Adriano R. Lameira Steven Moran
声音事件检测简介
摘要
我们提出了一种新方法,用于从野外研究期间收集的连续原始音频记录中自动检测和分类类人猿的叫声。我们的方法利用了深度预训练和序列神经网络,包括 wav2vec 2.0 和 LSTM,并在来自三个不同类人猿谱系(红毛猩猩、黑猩猩和倭黑猩猩)的三个数据集上进行了验证。这些录音由不同的研究人员收集,并包含不同的标注方案,我们的流水线以统一的方式对这些数据进行预处理和训练。我们在叫声检测和分类方面取得了高精度。我们的方法旨在推广到其他动物物种,更广泛地说,适用于其他声音事件检测任务。为了促进未来的研究,我们将我们的流水线和方法公开提供。
一句话总结
该流水线结合 wav2vec 2.0 与 LSTM 网络,通过统一处理异构标注方案,从连续野外录音中自动检测并分类类人猿叫声。该方法在猩猩、黑猩猩和倭黑猩猩数据集上均实现了高精度,并致力于推广至其他物种及更广泛的声事件检测任务。
核心贡献
- 统一的处理流水线结合 wav2vec 2.0 特征提取器与序列 LSTM 网络,直接从连续原始音频录音中自动检测并分类类人猿叫声。该架构将异构标注方案与多样化的野外录音标准化为一致的训练框架。
- 仅在人类语音上预训练的 wav2vec 2.0 模型无需额外微调即可作为类人猿叫声的有效音频特征表示层。该结果表明,在原始波形处理方面具备强大的跨物种声学泛化能力。
- 在三种不同类人猿谱系(猩猩、黑猩猩和倭黑猩猩)上的验证实现了超过 80% 的帧级分类准确率和加权 F1 分数。完整的处理流水线及训练模型已公开,以促进可复现研究并向其他物种扩展。
引言
灵长类动物学家依赖从连续野外录音中手动标注灵长类动物的发声,这一过程不仅耗时费力,还因茂密嘈杂的森林环境而更加复杂。自动化该工作流将显著加速行为学与声学研究的进展。现有的声事件检测与动物分类系统通常依赖预先分割的音频片段,难以处理连续原始录音,且无法有效应对重叠发声与环境噪声。目前尚无现有框架专门针对未处理野外数据中的类人猿叫声自动检测任务。作者结合预训练的 wav2vec 2.0 特征提取器与 LSTM 网络,直接从连续原始音频中检测并分类类人猿叫声。该流水线将异构野外录音处理为统一训练格式,在猩猩、黑猩猩和倭黑猩猩数据集上实现超过 80% 的准确率,并已公开发布以推动计算灵长类动物学的发展。
数据集
-
数据集构成与来源: 作者汇编了一个多物种发声语料库,包含黑猩猩的喘鸣叫声、猩猩的长鸣以及倭黑猩猩的高频鸣叫。这些数据源自自然行为场景下的野外录音,涵盖进食、移动、休息以及社交或环境反应等情境。
-
子集详情: 黑猩猩音频片段捕捉了无时间重叠的独立喘鸣叫声,按顺序划分为引入、积累、高潮和消退阶段。猩猩录音包含复杂的多脉冲长鸣,各阶段持续时间差异显著,且发声片段与非发声片段比例均衡。倭黑猩猩条目以响亮的高频鸣叫为主,辅以较短且多样的发声,引入了轻微的类别不平衡。
-
处理与特征提取: 所有音频片段均转换为 .wav 格式并重采样至 16 kHz,随后被分割为 20 毫秒的帧,必要时填充零。作者使用 torchaudio 提取了三组不同的帧级特征集:原始波形、频谱图以及基于 wav2vec 2.0 基础模型推断的嵌入向量。
-
标签构建、划分与模型应用: 帧级标签通过将手动标注映射至特定发声阶段的正类索引来构建,所有未标记帧默认归为零索引,代表非发声。完整数据集经过打乱后划分为 80% 训练集、10% 验证集和 10% 测试集,并使用随机种子 0、42 和 3407 生成了三个独立划分。该流水线支持双重建模策略,在黑猩猩数据上实现多类阶段分类,在猩猩录音上实现二元发声检测系统。
方法
作者利用序列建模框架学习一个函数 f,将输入音频帧 I1:T 映射至对应的标签序列 L1:T。整体架构通过特征提取流水线处理原始音频波形,其中从波形中提取 wav2vec 2.0 特征,并作为序列建模组件的输入。如图所示,该框架从原始波形开始,将其转换为频谱特征并输入 wav2vec 2.0 模型以生成高层表示。这些表示随后由序列建模函数 fm 处理,生成捕捉帧间依赖关系的隐藏序列 H1:T。隐藏序列接着通过全连接线性层 fd 生成中间输出 D1:T,最后经由 Softmax 函数 fs 转换,得到目标类别上的概率分布 P1:T。
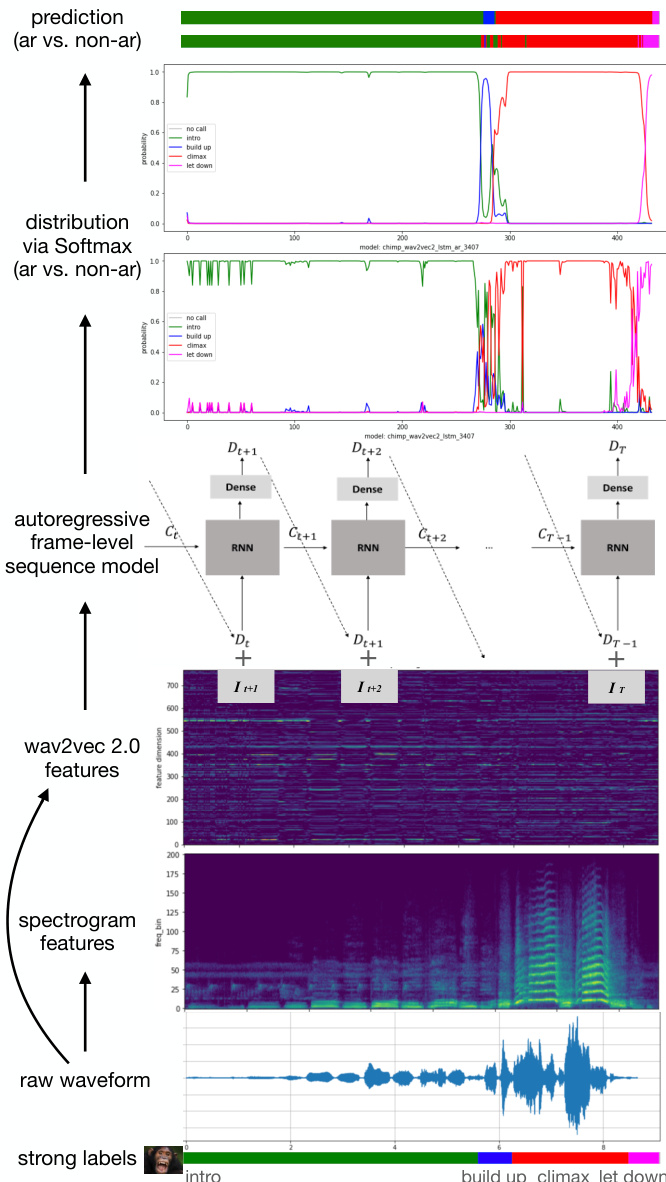
序列建模函数 fm 可采用多种形式。一种实现方式使用隐藏层大小为 1024 的双向 LSTM, resulting in 隐藏维度为 2048。另一种方式则采用包含 8 个注意力头和 6 层的 Transformer 编码器,隐藏维度为 1024。作者还引入了自回归机制,其中时间步 t 处全连接层的输出 Dt 与下一时间步的输入 It+1 进行拼接,使模型能够在预测中保持时间一致性。该自回归连接应用于基于 RNN 的序列模型中,可配置为单向运行,或通过在最终分类步骤前添加两个堆叠层并执行求和操作来保留双向性。
模型使用预测概率分布 P1:T 与真实标签 L1:T 之间的交叉熵损失进行训练,梯度通过网络反向传播以更新参数。为解决类别不平衡问题,类别权重被设定为训练数据中各类别频率的倒数。该训练策略使模型能够有效从不平衡数据集中学习,同时在所有目标类别上保持高分类准确率。
实验
实验基于 V100 GPU 使用 PyTorch 框架进行,训练轮数上限为 200,并根据验证集性能实施早停策略。在黑猩猩发声数据上的初步测试验证了 wav2vec 2.0 迁移学习的显著优势,表明在此有限数据集上 Transformer 相比 LSTM 并无优势,同时证实自回归连接能够提升输出一致性。该方法随后扩展至猩猩与倭黑猩猩录音,其中二元分类可有效分离发声以进行自动化分析。最终,从猩猩数据到倭黑猩猩数据的成功零样本迁移表明,尽管面临类别不平衡挑战,该方法在开发泛化类人猿声事件检测模型方面具有巨大潜力。
作者开展实验以评估不同模型与特征在类人猿发声检测中的表现,重点关注预训练音频表示与自回归建模带来的性能提升。该方法延伸至猩猩与倭黑猩猩数据,取得了具有竞争力的结果,并展示了跨物种零样本迁移的潜力。预训练音频特征在性能上显著优于原始波形与频谱图输入。与无自回归方法相比,自回归建模提升了输出一致性与整体性能。通过零样本迁移学习,该模型展现出对未见物种的良好泛化能力。
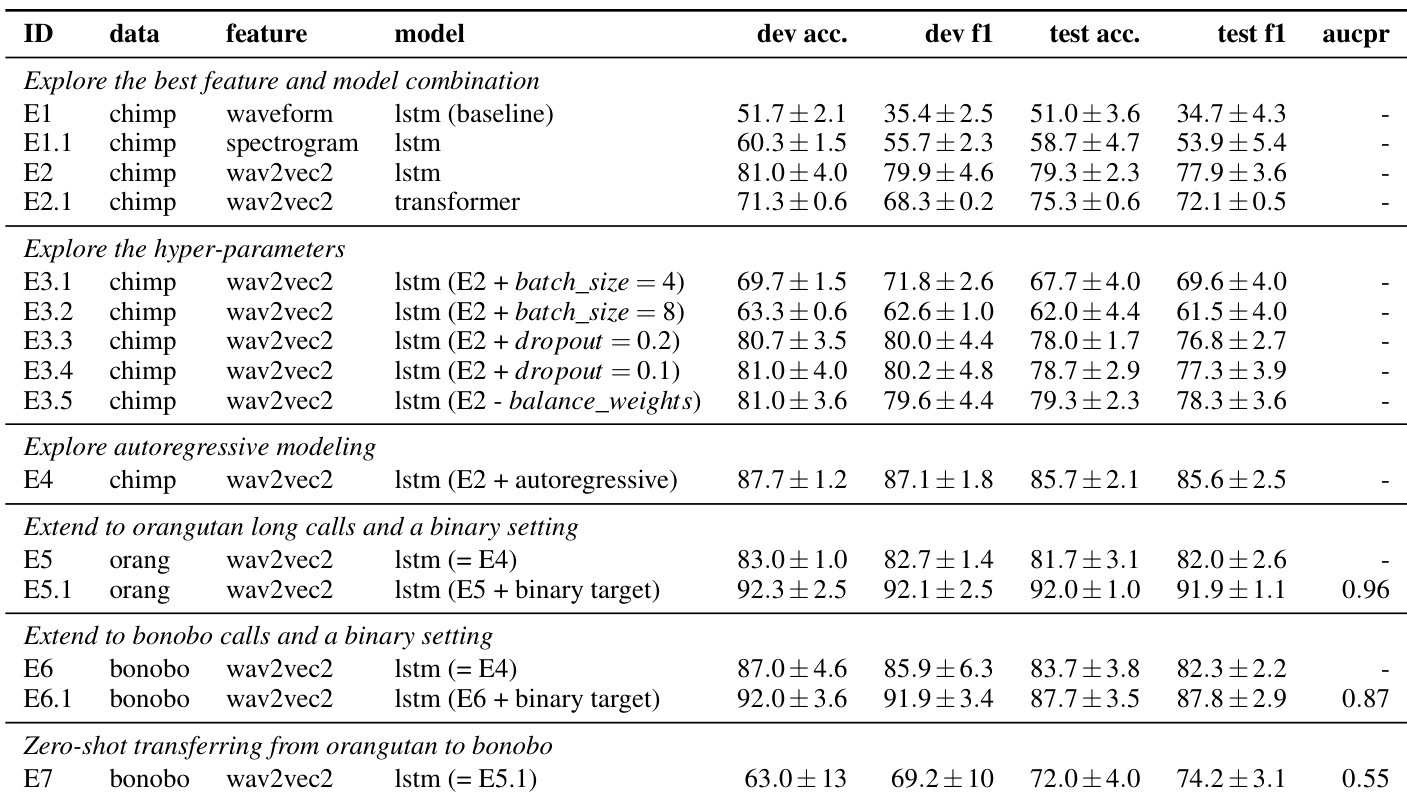
作者在黑猩猩、猩猩与倭黑猩猩数据集上开展实验,以评估模型检测发声类型的性能。结果显示模型在各物种间表现一致,表明可推广至通用声事件检测。实验涵盖多种模型架构与训练策略,模型在无自回归设置下输出稳定,并展现出跨物种迁移能力。该模型在包含不同数量音频片段与发声类型的三个类人猿数据集上进行测试,跨物种表现保持一致。无自回归模型输出稳定且波动极小,结果差距微小。在一个物种上训练的模型应用于另一物种时表现良好,暗示其在类人猿通用声事件检测方面具备潜力。

作者跨黑猩猩、猩猩与倭黑猩猩数据集评估了多种模型架构与特征表示在类人猿发声检测中的有效性。预训练音频表示与原始输入的对比表明,学习到的特征显著提升了检测精度,而自回归建模相比无自回归替代方案产生了更稳定的性能。跨物种测试进一步揭示,在单一物种上训练的模型能有效泛化至未见物种,凸显了该方法在类人猿广泛零样本声事件检测方面的巨大潜力。