Command Palette
Search for a command to run...
使用对比搜索在 Transformers 中生成人类水平的文本
摘要
一句话总结
通过对十六种语言表示各向同性的广泛评估发现,各向异性仅局限于特定的英文 GPT-2-small 和 GPT-2-medium 模型,这表明对比搜索解码无需 SimCTG 中提出的表示校准即可有效运行。
核心贡献
- 对 16 种语言中 38 个现成自回归语言模型的广泛评估表明,各向同性表示已成为标准配置,各向异性仅严格局限于英文 GPT-2-small 和 GPT-2-medium 变体。
- 在四项生成任务中对对比搜索解码进行的系统评估证实,该方法利用内在表示几何结构生成高质量文本,且无需额外训练。
- 全面的人工与自动评估表明,对比搜索显著优于现有解码策略,并在 16 种测试语言中的 12 种上达到了与人工标注员相当的性能。
引言
自回归语言模型构成了关键自然语言处理应用的核心基础,使得可靠的文本生成成为一项根本性挑战。传统解码方法在平衡流畅性与连贯性方面始终面临困难,经常产生重复序列或语义不一致的输出。尽管近期提出的对比搜索旨在解决此问题,但其依赖于模型表示天生具有各向异性的未经验证假设,这需要计算成本高昂的额外训练。本文作者系统性地测试了跨越 16 种语言的 38 个模型上的该假设,发现各向异性实际上非常罕见,大多数现代架构均表现出各向同性特征。借助这一发现,作者证明对比搜索可直接应用于现成模型而无需任何校准,显著优于先前的解码策略,并在多项任务与语言中实现了达到人类水平的生成质量。
数据集

数据集构成与来源:提供的文本中未披露数据集构成或来源。 各子集关键细节:未提供关于子集大小、来源或过滤规则的信息。 论文数据使用方式:未描述训练集划分、混合比例或数据用途。 处理细节:省略了任何裁剪策略、元数据构建或处理步骤。
方法
本文作者利用一个结合语言模型各向同性分析与新型解码策略的框架来提升生成质量。为评估各向同性,他们将文本序列 x 内 token 表示的自相似度定义为:
self-similarity(θ;x)=∣x∣×(∣x∣−1)1i=1∑∣x∣j=1,i=j∑∣x∣∥hxi∥⋅∥hxj∥hxi⊤hxj,其中 x={x1,…,x∣x∣} 为变长文本序列,hxi 与 hxj 为语言模型 θ 生成的 token xi 和 xj 的表示。该指标量化了不同 token 表示之间的相似程度;数值越低表明表示的区分度越高。随后,模型 θ 在语料库 D 上的各向同性定义为:
isotropy(θ)=1−∣D∣1x∈D∑self-similarity(θ;x).更高的各向同性值反映表示在嵌入空间中分布更为均匀,表明更严格地遵循各向同性结构。
实验
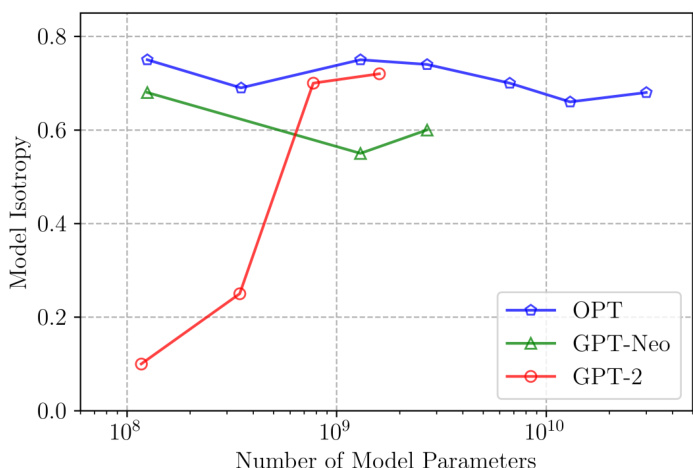
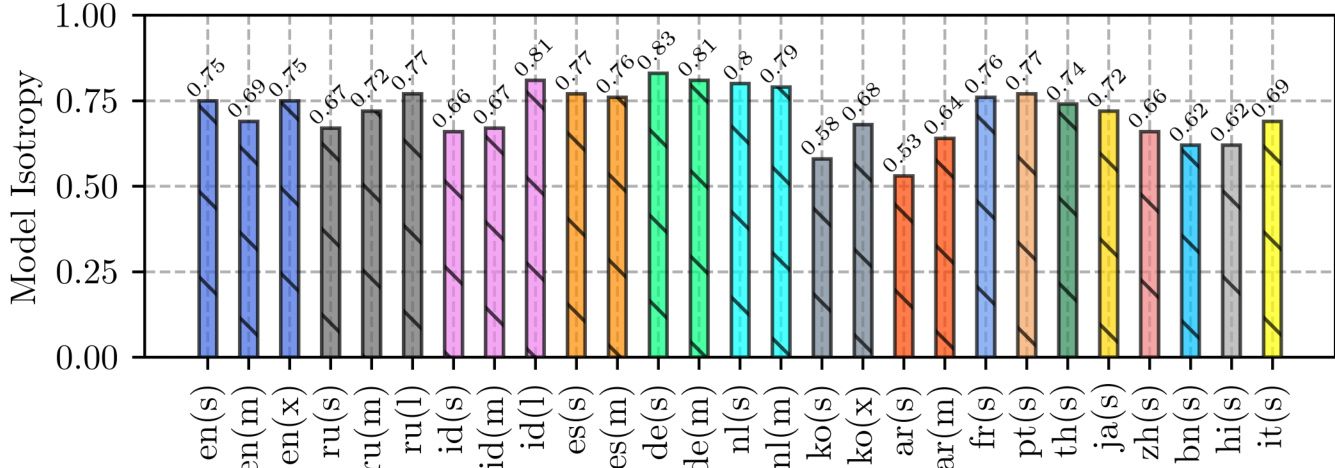
实验评估了不同规模与语言下现代自回归语言模型的各项同性,揭示大多数当代模型表现出各向同性表示空间,而较小变体仍保持各向异性。在开放式文本生成、文档摘要、代码生成和机器翻译方面的后续评估验证了对比搜索通过有效平衡语义连贯性与语言多样性,始终优于传统解码策略。进一步分析表明,各向同性表示空间对于对比搜索维持最优退化惩罚方差并避免退化为贪心解码至关重要。综合来看,这些发现确立了对比搜索作为一种稳健的解码方法,能够在多样化的多语言与专业任务中充分发挥预训练语言模型的内在能力。
作者评估了多种语言与模型规模下语言模型的各项同性,发现除较小模型外,大多数模型均表现出高各向同性。结果表明,各向同性是大型语言模型的常见属性,且对对比搜索的有效性至关重要,因为各向同性更高的模型在解码过程中表现出更大的退化惩罚方差。大多数被评估的语言模型呈现高各向同性,仅较小模型显示低各向同性。各向同性对比搜索至关重要,因为各向同性越高的模型在退化惩罚上表现出更大的方差。研究结果表明,语言模型内在的各向同性降低了对 SimCTG 等额外训练方法的需求。
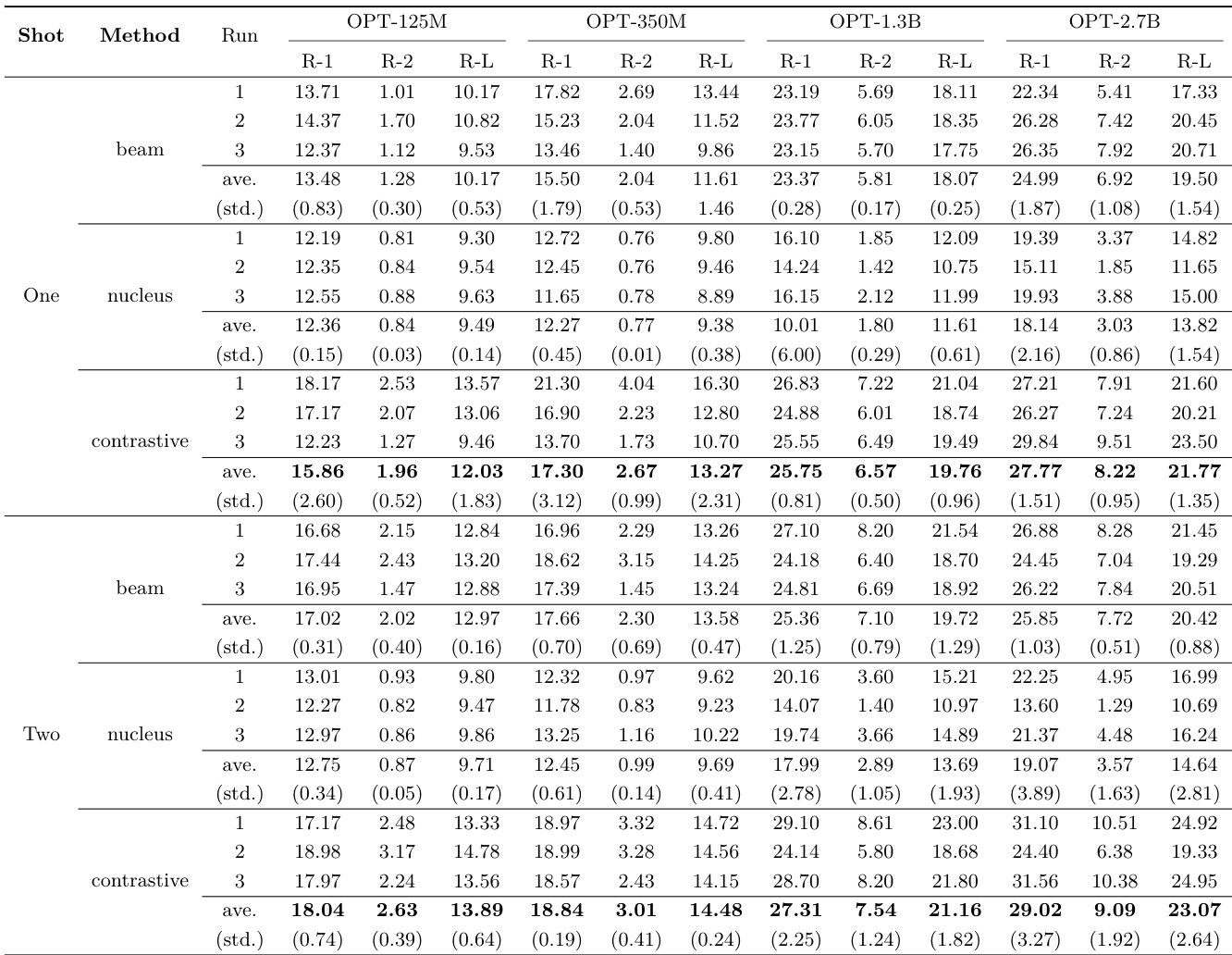
作者使用不同规模的 OPT 模型评估了不同解码方法在文档摘要任务上的性能。结果显示,对比搜索在所有模型规模与评估指标上均持续优于其他方法,尤其在连贯性与整体质量方面表现突出。实验还强调了模型规模的重要性,较大模型取得了显著更好的结果。与束搜索和核采样相比,对比搜索在所有评估指标上均取得最佳结果。在所有解码方法中,较大模型规模始终比小模型规模表现更佳。对比搜索展现出强大的连贯性,并在不同模型规模与设置下维持高质量输出。
作者在开放式文本生成任务中将对比搜索与多种解码方法进行评估,对比了自动评估与人工评估结果。实验表明,对比搜索在连贯性与整体质量方面优于其他方法,结果显示其比替代方法更好地维持了语义一致性。该发现在不同语言模型与评估指标间保持一致,凸显了对比搜索的稳健性。根据人工评估,对比搜索在连贯性与整体质量上优于其他解码方法。与基线方法相比,对比搜索在维持与前缀文本的语义一致性方面获得更高分数。结果证明了对比搜索在不同解码策略与评估指标下的有效性。
作者对比了使用对比搜索进行文本生成时,SimCTG 与现成语言模型的性能。结果显示,两种模型均取得相似的数据多样性与 MAUVE 分数,现成模型的生成长度略高。连贯性指标表明现成模型表现更佳,尽管两种模型均呈现较低的连贯性数值。SimCTG 与现成模型均取得可比的多样性与 MAUVE 分数。现成模型生成的文本比 SimCTG 略长。与 SimCTG 相比,现成模型展现出更好的连贯性。

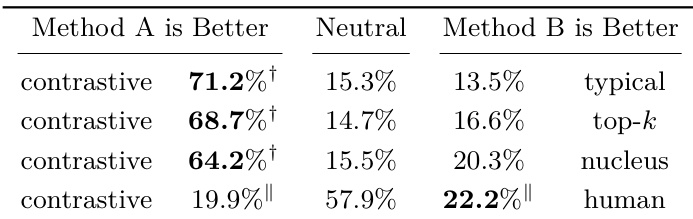
作者开展了跨多种语言的人工评估,将对比搜索与核采样进行对比,结果显示对比搜索在大多数情况下显著优于核采样。结果表明,对比搜索维持了语义连贯性并生成更高质量的文本,在多种语言中的表现可与人工撰写文本相媲美。评估结果在不同语言对间保持一致,支持了对比搜索在多语言环境下的稳健性。经人工评估验证,对比搜索在大多数语言中显著优于核采样。对比搜索在多种语言中达到与人工撰写文本相当的性能,表明其具备高质量生成能力。结果在不同语言间保持一致,证明了对比搜索在多语言设置下的泛化能力。
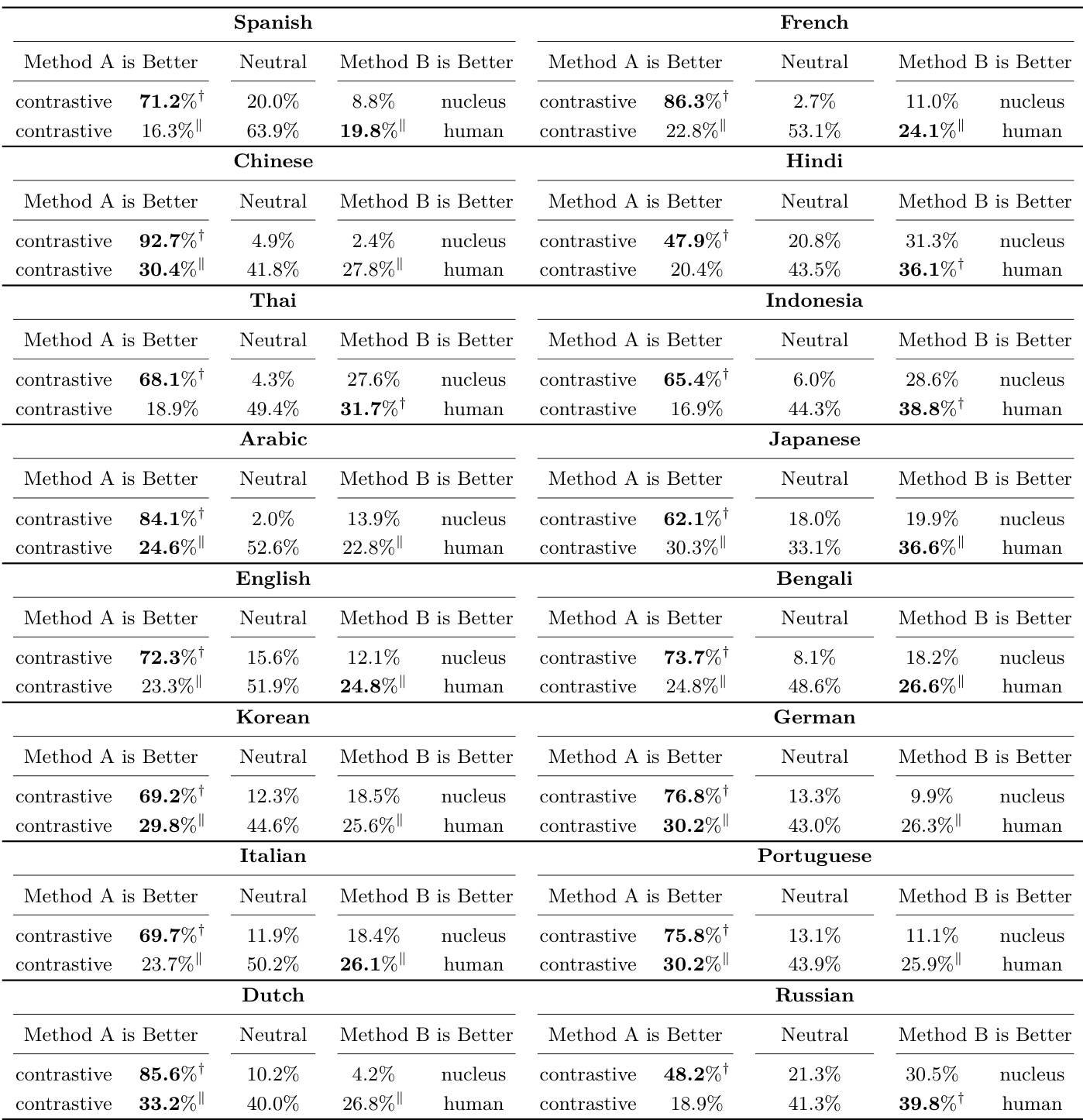
实验评估了不同规模、语言及生成任务下的语言模型,以考察内在各向同性的作用以及对比搜索相对于标准解码策略的有效性。结果一致表明,较大模型天然呈现高各向同性,这通过改善惩罚方差并降低对专门训练方法的需求来增强对比搜索。在摘要、开放式生成及多语言设置中,对比搜索在连贯性、语义一致性及整体文本质量方面持续优于基线方法,经常达到人工撰写标准。这些发现共同确立了对比搜索作为一种稳健的解码策略,能够利用模型固有属性生成高质量且连贯的输出,而无需额外微调。