Command Palette
Search for a command to run...
如何训练一个问答机器学习模型(BERT)
摘要
一句话总结
本文综述提出了一种分类框架,根据方法所针对的决策情境、内在的学习曲线问题以及使用的资源类型,对用于学习曲线建模的监督机器学习方法进行分类,从而系统化了涵盖从二元性能阈值模型到完整曲线预测器的文献,适用于数据获取、早停和模型选择等应用场景。
核心贡献
- 本文提出了一种分类框架,根据决策情境、内在预测问题以及所用数据资源对学习曲线方法进行组织。该结构为评估参数化模型和元学习模型中的算法选择与早停策略提供了标准化参考。
- 系统的文献调研将现有外推方法映射至所提出的分类体系中,对解决二元性能比较和完整曲线预测的研究进行分类。这一整合为评估自动化机器学习系统中的模型选择技术建立了连贯的参考基准。
- 该分析通过指出当前方法极少相互基准测试或结合多种数据资源类型,揭示了关键的方法论空白。这些发现突出了开发底层二元预测方法和与自动化机器学习流水线紧密集成的多资源外推模型的机会。
引言
学习曲线追踪监督机器学习模型在资源预算(如训练样本量或计算时间)下的性能表现,使其成为优化数据获取、早停和模型选择的关键工具。尽管具有实用价值,但先前的研究产生了碎片化的技术景观,涵盖从基础收敛检查到复杂参数化外推模型的各种方法。这种缺乏标准化的情况通常导致错配:过于复杂的建模方法被应用于简单的二元决策问题,而宝贵的跨算法和跨数据集资源却未得到充分利用。为应对这些挑战,作者引入了一个统一框架,从三个维度对现有方法进行分类:决策场景、所解决的具体技术问题以及利用的数据资源。随后,他们进行了广泛的文献调研,将当前方法映射到该框架中,突出了关键的研究空白,并为自动化机器学习流水线提出了更高效、具备情境感知能力的建模策略。
数据集
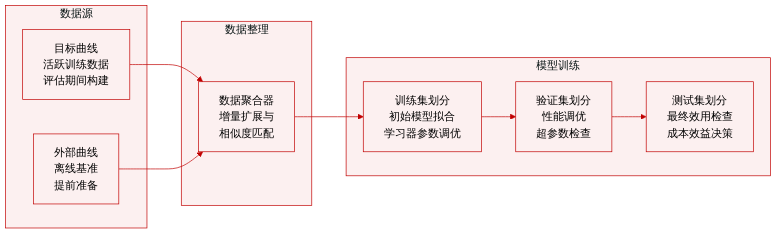
-
数据集构成与来源: 本文作者使用合成的现有资源集合进行曲线分析,而非单一专有数据集。这些来源包括目标数据集的经验曲线、外部基准的预计算曲线、数据集元特征以及学习器特定特征。
-
各子集的关键细节: 作者将这些资源分为四个概念组,而非固定子集。目标数据集曲线在主动训练期间生成。外部曲线通常可获取至较大样本量或收敛状态,并预先离线准备。元特征捕捉可测量的数据集质量以估计领域相似度,而学习器特征描述算法属性以预测性能轨迹。
-
本文如何使用数据: 作者利用这些资源对曲线进行建模,并解决定量数据获取问题,例如确定最优样本量、估计理论性能上限以及相对于标注成本最大化效用。部分经验曲线被增量构建,可根据计算预算进行扩展或丢弃。该框架评估的是可行学习器组合,而非单一固定模型。
-
处理细节与策略: 作者未应用特定的裁剪策略、混合比例或过滤规则。相反,他们依赖元学习和基于特征的相似度来引导推理,将历史曲线和可测量的数据集属性作为决策输入。本文明确指出,由于其综述性质,数据与代码不可用。
方法
学习曲线建模与决策框架围绕刻画学习器性能随预算变化的函数展开,预算可代表训练样本数量或迭代次数。性能通常通过损失函数(如错误率)衡量,被建模为随机过程 f(a,b)∼N(μa,b,σa,b2),其中 μa,b 为真实平均性能,σa,b2 为偶然不确定性。主要目标是构建模型 f^a(b) 以估计任意预算 b 下的 μa,b,从而实现超出观测数据的预测。该过程必然涉及应对两种不确定性:偶然不确定性(性能测量中的固有噪声)和认知不确定性(对模型均值估计的不确定性)。模型在不同预算间泛化的能力,以及在更先进情况下跨不同学习器泛化的能力,是其核心效用所在。
建模过程的核心是构建学习曲线模型,可根据其提供的估计类型分为三个复杂度等级。最简单形式为点估计,模型 f^a(b) 在给定预算下返回单一预测性能值。这通常通过将参数函数(如逆幂律 μa,b=α+βb−γ)拟合到一组经验观测值来实现。该方法虽然直接,但未能量化预测相关的 uncertainty。更复杂的方法是区间估计,它在点估计周围提供置信区间或四分位距,从而显式建模认知不确定性。这通常通过对经验分布的分位数拟合独立模型来完成。最全面的方法是分布估计,它建模任意预算下真实平均性能的完整概率分布。这通常借助贝叶斯方法(如高斯过程或贝叶斯神经网络)实现,从而在可能的学习曲线空间中提供概率信念。

该框架超越简单的点预测,支持多种决策情境。这些情境按三个正交维度组织:决策情境、所提出的技术问题以及使用的数据资源。决策情境包括数据获取、早停和早弃。早停指在学习曲线收敛时中止训练过程;数据获取指基于所有考虑学习器的预测性能来决定何时停止收集数据。早弃则是基于预测性能从学习器组合中剔除表现不佳的候选者。可回答的技术问题范围从简单的二元决策(例如:参考点处的性能是否低于阈值?)到关于学习曲线或效用函数完整形状的更复杂查询。可用的数据资源可包括目标学习器的学习曲线、其他学习器在相同或不同数据集上的学习曲线,以及描述数据集或算法的特征。

最通用的模型是能够预测任意学习器在任意预算下性能的模型,记为 C(⋅,⋅)。这些模型高度灵活,可用于上述任何决策任务。它们通常通过同时泛化学习器和预算来构建。例如,冻结-解冻贝叶斯优化和 FABOLAS 使用高斯过程对不同超参数配置下的学习曲线进行建模,而其他方法使用神经网络或矩阵分解来建模性能景观。这些模型还可扩展以纳入效用,创建权衡性能与数据获取或计算时间等成本的效用曲线 U。如下方图片所示,效用曲线通过结合学习曲线模型的预测性能与成本函数推导得出,最优决策通常在该曲线的峰值处作出。

另一个关键概念是容量曲线,它在固定数据集大小下绘制学习器性能随模型复杂度(如参数数量)变化的函数。该曲线有助于分析数据的固有噪声水平,并识别增加模型容量不再提升性能的临界点,这与样本级学习曲线中的饱和点类似。下图对此进行了说明,显示性能最初随模型容量增加而下降,达到最低点(即固有噪声),随后可能因过拟合而上升。

实验
该评估在基准数据集上使用样本级和迭代级方法计算经验学习曲线,以比较随机森林、神经网络和支持向量机等算法。这些实验验证了不同训练数据规模和优化迭代次数如何影响模型误差,表明经验曲线能够可靠地反映不同学习器的相对性能排名。尽管该方法未产生理论泛化结论,但它提供了实用的、特定于数据集的见解,有效指导算法选择与模型比较。
该表根据所解决的问题、学习曲线类型、使用的数据资源以及估计类型对学习曲线方法进行了分类。它根据方法侧重于预测性能、排名学习器还是估计效用对方法进行分类,并指出其使用观测数据还是迭代数据,以及产生的估计类型。该表按所解决的问题类型(如性能预测和学习器排名)对学习曲线方法进行组织。方法根据数据使用情况(包括观测和迭代方法)以及是否使用数据集或算法特定资源进行分类。该表区分了不同的估计类型(如点估计、区间估计和分布估计),并说明它们在不同学习曲线任务中的适用性。
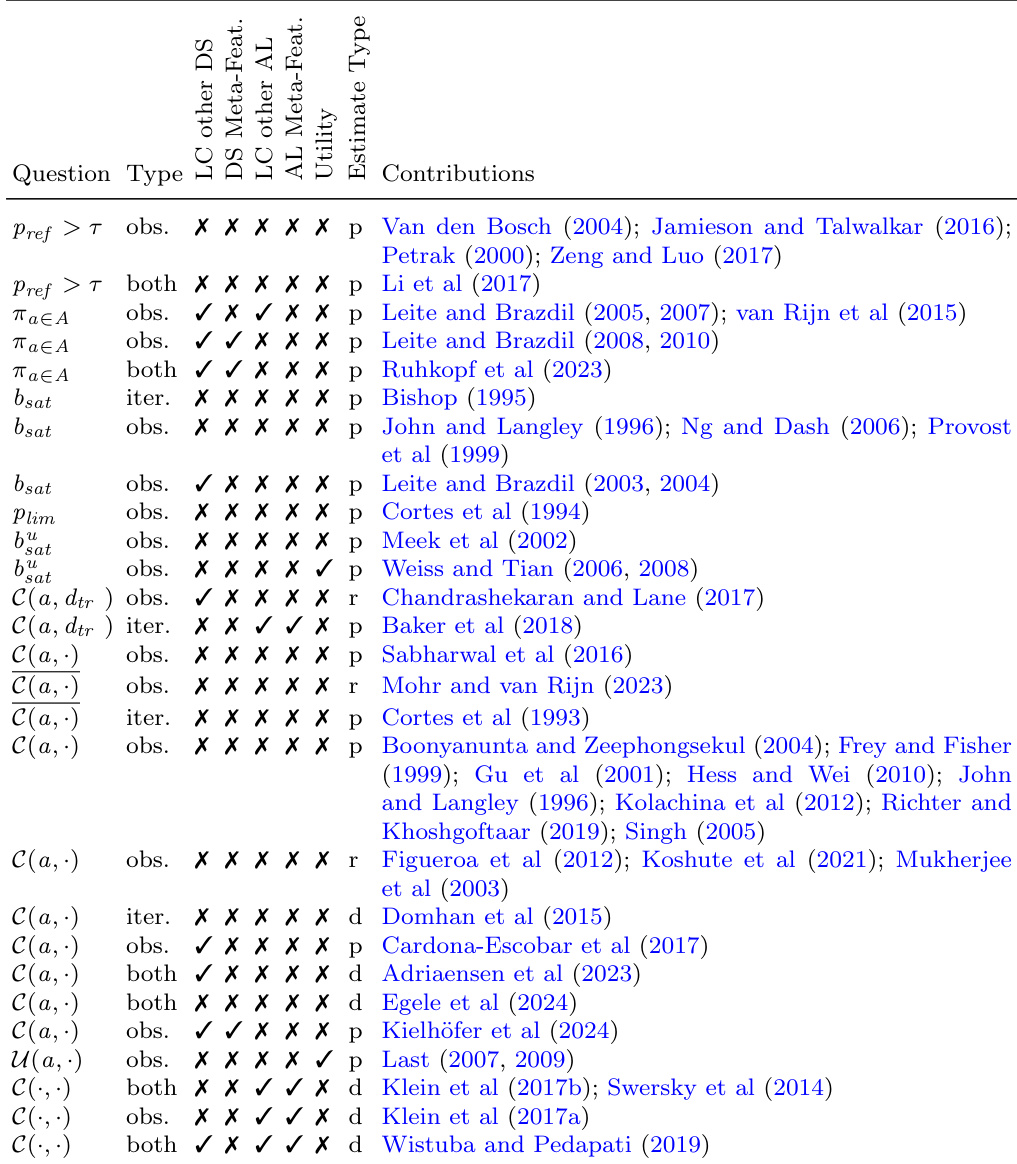
该内容呈现了学习曲线方法论的结构化分类,按核心目标组织方法,包括性能预测、学习器排名和效用估计。该框架根据数据需求区分方法,区分观测与迭代采样以及数据集和算法特定资源。它进一步按输出格式对技术进行分类,涵盖点估计、区间估计和分布估计。最终,该分类体系为将学习曲线选择与特定研究目标及可用数据约束对齐提供了清晰的定性指南。