Command Palette
Search for a command to run...
FedCV:面向多样化计算机视觉任务的联邦学习框架
FedCV:面向多样化计算机视觉任务的联邦学习框架
边缘检测-通用计算机视觉与深度学习方法
摘要
联邦学习(Federated Learning, FL)是一种分布式学习范式,能够从边缘设备上的去中心化数据中学习全局或个性化模型。然而,在计算机视觉领域,由于缺乏统一联邦学习框架下对多样化任务的探索,联邦学习的模型性能远远落后于集中式训练。目前,联邦学习在目标检测和图像分割等高级计算机视觉任务中的有效性尚未得到充分验证。为弥合这一差距并促进计算机视觉任务中联邦学习的发展,本文提出了一款名为 FedCV 的联邦学习库与基准测试框架,用于评估联邦学习在最具代表性的三项计算机视觉任务上的表现:图像分类、图像分割和目标检测。我们提供了非独立同分布(Non-I.I.D.)的基准数据集、模型以及多种参考联邦学习算法。我们的基准研究表明,存在多个值得未来深入探索的挑战:集中式训练的常用技巧可能无法直接应用于联邦学习;在不同任务中,非独立同分布的数据集实际上会在一定程度上降低模型精度;鉴于参数量巨大且客户端内存成本较高,提升联邦训练的系统效率具有挑战性。
一句话总结
作者提出了 FedCV,这是一个统一的联邦学习框架与基准测试库,提供了非独立同分布(non-I.I.D.)数据集、模型及参考算法,用于评估图像分类、分割和目标检测任务。研究证明,集中式训练技术无法直接应用于联邦学习,非独立同分布数据会降低各任务上的准确率,而庞大的参数量与单客户端内存限制则会阻碍系统效率。
核心贡献
- 本研究推出了 FedCV,一个用于评估图像分类、图像分割和目标检测分布式训练的联邦学习库与基准框架。该系统为在代表性计算机视觉任务上测试联邦算法提供了标准化环境。
- 该框架提供了非独立同分布(non-I.I.D.)基准数据集、标准化模型架构及多种参考联邦优化算法,以支持系统性评估。
- 全面的基准研究揭示了将联邦学习应用于计算机视觉时的关键挑战。分析表明,集中式训练技术在联邦环境中往往失效,非独立同分布数据会降低模型准确率,而庞大的参数量会造成显著的单机客户端内存瓶颈。
引言
联邦学习支持在去中心化边缘设备上进行隐私保护的模型训练,为受严格数据隐私法规、高传输成本或专有数据需求限制的计算机视觉应用提供了切实可行的解决方案。尽管潜力巨大,但以往的联邦学习研究大多忽视了高级视觉任务,转而聚焦于小规模图像分类,且多采用无法良好适配分布式边缘环境的集中式优化技术。这种狭隘的研究焦点导致非独立同分布数据、硬件异构性以及大型视觉模型的可扩展性等关键挑战未能得到充分解决。为弥补这一空白,作者引入了 FedCV,这是一个专为计算机视觉定制的统一联邦学习库与基准框架。该框架在单一分布式训练架构中支持图像分类、分割和目标检测,提供标准化的非独立同分布数据集、模块化的联邦优化算法及可扩展的 API,以加速公平评估与实际部署。
数据集
- 数据集构成与来源: 作者整理了一套联邦计算机视觉基准套件,包含四个主要数据集:源自智能手机用户的 Google Landmarks Dataset 23k(GLD-23K)、标准的 CIFAR-100 数据集、增强版 PASCAL VOC 2011 子集以及 COCO 数据集。
- 子集详情: GLD-23K 和 CIFAR-100 专用于图像分类。PASCAL VOC 子集包含 11,355 张图像,标注了 20 个前景物体类别和 1 个背景类别。COCO 提供了真实的日常场景,其检测与分割标签通过 Amazon Mechanical Turk 生成。
- 数据使用与划分: 团队采用潜在狄利克雷分配(LDA)将所有数据集划分为非独立同分布的客户端分布,以模拟真实的联邦学习环境。研究使用该数据训练并评估 FedAvg 和 FedOpt 等联邦优化算法,同时运行集中式微调基线以供对比。
- 处理与流水线: 作者未采用自定义裁剪或元数据提取,而是通过提供自动化下载脚本和集成数据加载器来标准化预处理流程。这些流水线负责解析标注并进行客户端侧分发,确保数据格式一致,并简化所有联邦客户端的配置过程。
方法
作者以 FedML.ai 框架为基础设计 FedCV,这是一个面向多样化计算机视觉任务的开源联邦学习系统。如框架架构图所示,该系统架构采用分层设计,以同时支持高层研究与底层分布式通信。在顶层,FedML-API 为用户提供高层抽象,用于定义包括图像分类、分割和目标检测在内的计算机视觉应用,并配合非独立同分布(non-IID)数据集与数据加载器。这些应用由一系列联邦学习算法提供支持,包括 FedAvg、FedOpt、FedNova、FedProx 等,这些算法通过分布式或独立配置实现。系统核心基于 FedML-core 构建,负责处理通信、模型训练和安全原语等底层功能。该层包含用于管理通信线程的 ComManager 组件,以及支持 MPI、MQTT 和感知张量的 RPC 等多种协议的抽象通信层,从而实现在不同数据中心之间的高效节点间通信。该框架还集成了安全与隐私原语(如安全聚合),以增强联邦学习过程的鲁棒性。 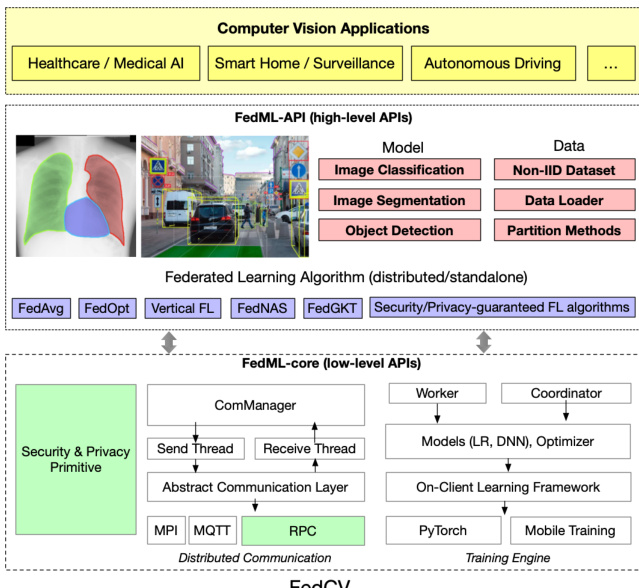
FedCV 的设计通过模块化组件和可扩展 API 强调灵活性与易用性。该系统支持多种计算机视觉应用,涵盖医疗健康、智能家居监控与自动驾驶,并通过专用模型与数据处理机制集成至框架中。FedCV 内的训练引擎基于 PyTorch,并支持客户端侧学习框架,允许自定义训练流程与模型架构。通信层针对分布式计算进行了优化,包含发送线程与接收线程等组件,以实现工作节点与协调器之间的高效数据交换。该模块化设计通过抽象底层通信与优化流程,促进了去中心化、垂直和拆分学习等多种联邦学习算法的实现。 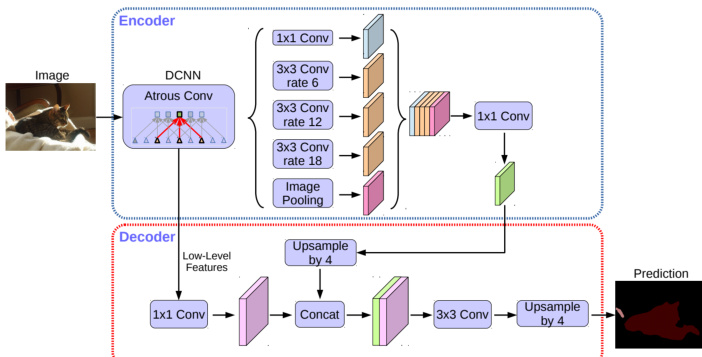
针对计算机视觉任务,作者引入了一种用于图像分割的特定模型架构,详见下图。该架构采用深度卷积神经网络(DCNN)作为编码器,通过具有不同速率(如 6、12 和 18)的一系列卷积层处理输入图像,以捕获多尺度特征。编码器输出随后传递至解码器,通过上采样与拼接操作重建分割图。解码器使用 1x1 卷积与 3x3 卷积细化特征,最终生成预测结果。该设计实现了高效特征提取与重建,适用于各类分割任务。 
整体框架旨在通过提供基准测试、参考实现与灵活 API 来弥补计算机视觉联邦学习的研究空白。这使得研究人员能够高效探索各类训练范式与网络拓扑结构。系统支持多 GPU 分布式训练,从而缩短计算时间并使大规模实验成为可能。通过集成这些组件,FedCV 为开发及评估多样化计算机视觉应用中的联邦学习算法提供了综合平台。 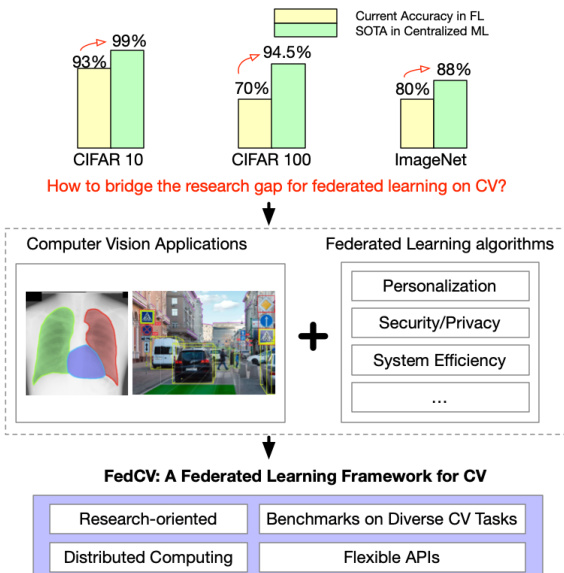
实验
在多种深度学习模型与联邦数据集上开展的图像分类、分割与目标检测任务实验,评估了数据异构性、训练策略及系统约束的影响。分类结果验证了微调可显著加速收敛并提升准确率,而分割实验表明从头训练通常能达到与微调相当的性能,且更适配内存受限的边缘设备。目标检测评估揭示,由于优化器不兼容与通信瓶颈,联邦框架在非独立同分布数据上难以达到集中式训练的结果。综合来看,这些发现强调了在实际联邦学习部署中模型复杂度、数据分布与系统效率之间的关键权衡。
作者展示了使用不同模型与数据集在图像分类任务上的实验结果,对比了集中式训练与联邦学习方法。结果表明,集中式训练整体表现优于联邦学习,性能表现因模型类型、数据划分与训练策略而异。实验凸显了非独立同分布数据的影响,以及微调与从头训练的效能差异。在 CIFAR-100 和 GLD-23k 数据集上,集中式训练在 EfficientNet 和 MobileNet V3 上均取得了高于联邦学习的准确率。相较于从头训练,微调提供了更优的性能,且该差距在非独立同分布数据条件下更为显著。学习率的选择与数据划分方式对联邦学习设置下的模型准确率有显著影响。
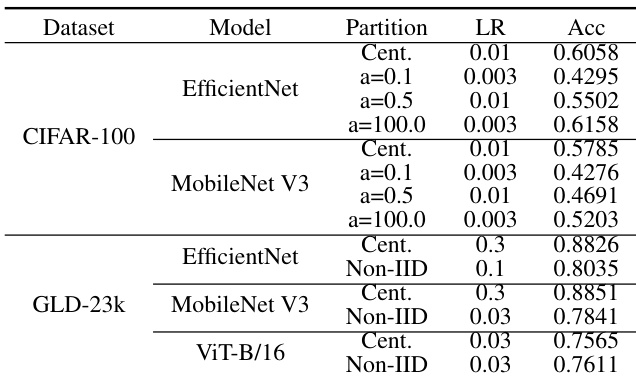
作者展示了在联邦学习设置下使用 YOLOv5 模型进行目标检测任务的实验结果。结果表明,模型性能随结构复杂度变化,更深更宽的模型可实现更高准确率,但需要更多训练时间。集中式训练与联邦训练之间的性能差距显著,表明将集中式训练技术迁移至联邦环境面临挑战。更深更宽的 YOLOv5 模型准确率更高,但训练时间更长。在目标检测任务中,联邦训练性能显著低于集中式训练。模型结构的选择对联邦设置下的准确率与训练效率均有显著影响。
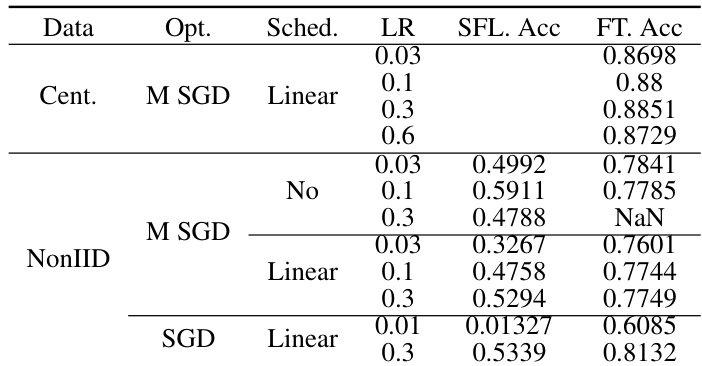
作者展示了联邦学习设置下图像分类、图像分割与目标检测任务的实验结果。结果表明,集中式训练整体优于联邦训练,尤其针对非独立同分布数据,且相较于从头训练,微调可显著提升性能。优化器、学习率及模型架构的选择同样影响性能,动量 SGD 与学习率调度器在不同场景下呈现混合效果。集中式训练实现了高于联邦训练的准确率,尤其在非独立同分布数据条件下。与从头训练相比,微调带来了更快的收敛速度与更优的最终准确率。学习率与优化器的选择影响模型性能,动量 SGD 与学习率调度器在不同设置下表现出各异的效能。
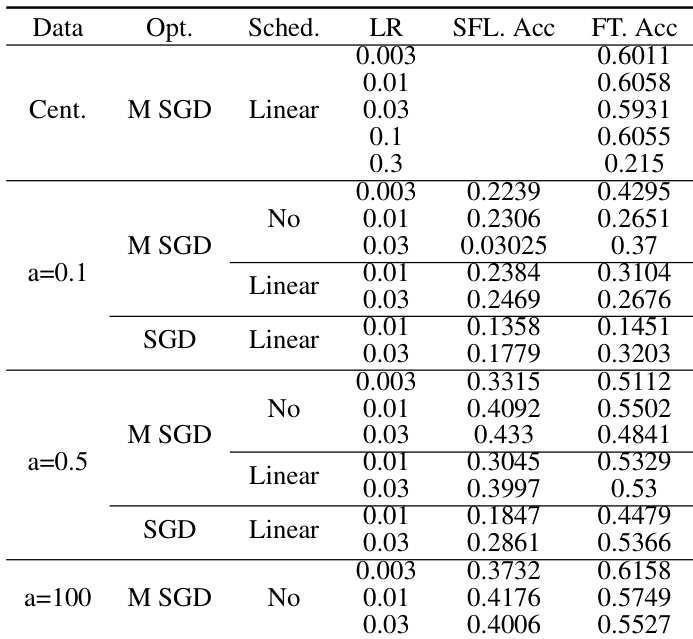
作者展示了图像分类任务的实验结果,对比了不同模型与非独立同分布数据设置下集中式训练与联邦学习方法。结果表明,集中式训练整体优于联邦学习,性能差异随数据异构程度与微调的使用而变化。研究还分析了动量 SGD 与学习率调度器等优化技术的影响,揭示其效能取决于数据分布与模型架构。集中式训练实现了高于联邦学习的准确率,且在数据异构性较高时差距更为明显。相较于从头训练,微调提升了性能,尤其在数据异构性较低的场景中。动量 SGD 与学习率调度器的效能因数据分布与模型类型而异。
作者展示了图像分类、分割与检测任务的实验结果,重点聚焦于联邦设置下训练不同深度学习模型的效率。下表总结了系统性能指标,显示 ViT 等大型模型相比小型模型需要显著更多的通信轮次与时间,表明联邦学习中存在更高的通信开销。与 MobileNet-V3 和 EfficientNet 等小型模型相比,ViT 等大型模型需要大幅更多的通信轮次与总训练时间。大型模型的通信成本显著更高,其中 ViT 的通信成本远高于其他模型。总训练时间随模型规模增加而上升,ViT 的训练时间明显长于 MobileNet-V3 与 EfficientNet。
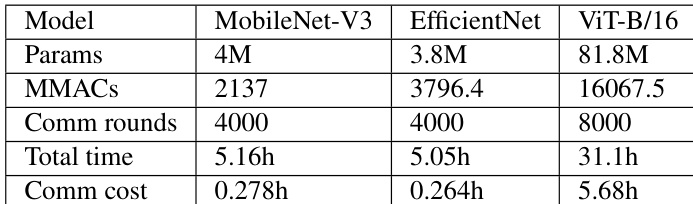
实验在多种模型架构与数据集上,针对非独立同分布数据下的图像分类、分割与目标检测任务,评估了集中式与联邦学习的对比。结果一致表明,集中式训练实现了更优的准确率,且随着数据异构性增加,性能差距进一步拉大。微调被证明比从头训练更有效,尤其在联邦环境中,而大型模型架构则会产生显著更高的通信开销与训练延迟。最终,这些发现强调联邦学习性能对数据分布、模型复杂度及优化策略高度敏感,凸显了在分布式环境中复现集中式训练效率所固有的挑战。