Command Palette
Search for a command to run...
面向基于电子健康记录(EHR)临床研究的开放自然语言处理(NLP)框架:基于国家COVID队列协作(N3C)的案例演示
面向基于电子健康记录(EHR)临床研究的开放自然语言处理(NLP)框架:基于国家COVID队列协作(N3C)的案例演示
使用 NLTK 进行自然语言处理
摘要
尽管临床自然语言处理(NLP)的方法学取得了近期进展,但ETL过程的异质性和人为因素的差异仍阻碍了临床NLP模型在临床和转化研究社区中的采用。在本研究中,我们提出了一种开放的NLP开发框架,旨在解决这些问题。该平台在一个通过国家COVID队列协作(N3C)参与的站点进行的COVID-19用例中评估了其可行性。作为我们对单站点与多站点NLP算法开发影响的评估的一部分,我们评估了仅使用单一站点的临床叙述开发的NLP规则集的性能,以及进一步利用源自三个站点(Mayo、UKen和UMN)的合成派生数据集进行优化的规则集的性能。单站点规则集在Mayo、明尼苏达和肯塔基测试数据集上的F分数分别为0.876、0.706和0.694,而多站点NLP规则集将性能提高至0.884、0.769和0.806。我们的用例测试结果证明了多站点联合开发、评估和实施框架的重要性。
一句话总结
针对临床自然语言处理(NLP)中的ETL异构性及人为因素差异,作者提出了一种开源开发框架,并在国家COVID队列协作计划(N3C)的COVID-19应用案例中进行了评估。该案例中,经过三家机构合成数据优化的多站点NLP规则集在Mayo、Minnesota和Kentucky测试集上的表现均优于单站点规则集,F分数分别达到0.884、0.769和0.806,而单站点规则集的对应分数分别为0.876、0.706和0.694。
核心贡献
- 本研究提出了一种开源NLP开发框架,利用临床通用数据模型标准化数据接口,以减轻不同电子健康记录系统之间在提取、转换和加载(ETL)方面的异构性问题。
- 该平台集成了透明的多站点工作流与众包界面,以协调语料标注并融合各站点专属知识,直接应对黄金标准构建中的人为因素差异。
- 国家COVID队列协作计划(N3C)的应用案例表明,多站点联邦NLP规则集的表现优于单站点基线,在Mayo、Minnesota和Kentucky测试数据集上的F分数分别从0.876、0.706和0.694提升至0.884、0.769和0.806。
数据集
- 作者使用了一个源自国家COVID队列协作计划(N3C)的去标识化合成临床语料库,该语料库基于OMOP通用数据模型构建,以支持临床自然语言处理工作流。
- 数据集按概念子集进行组织,重点关注呼吸困难、鼻塞、食欲减退、凝血酶原时间延长和淋巴细胞减少。每个类别均将临床术语与精心整理的同义词列表及结构化提取规则相匹配。
- 在模型开发阶段,作者利用该语料库训练和评估概念提及提取管道。数据通过一个规则集框架进行处理,该框架整合了正则表达式、同义词匹配和上下文标注,用于解析临床文本,且无需依赖固定的训练集划分或混合比例。
- 标注与元数据构建遵循公开记录指南,以标准化标注目标。作者通过将语义修饰符嵌入规则集来提高提取准确性,明确标注否定、不确定性及前置修饰语,从而在合成记录中准确捕捉临床上下文。
方法
所提出的框架由三个主要层级构成:数据摄入层、处理层和持久化层,旨在支持可扩展且可互操作的临床文本自然语言处理。整体架构见框架示意图,图中展示了数据从临床来源经过脱敏、处理到存储的流转过程。
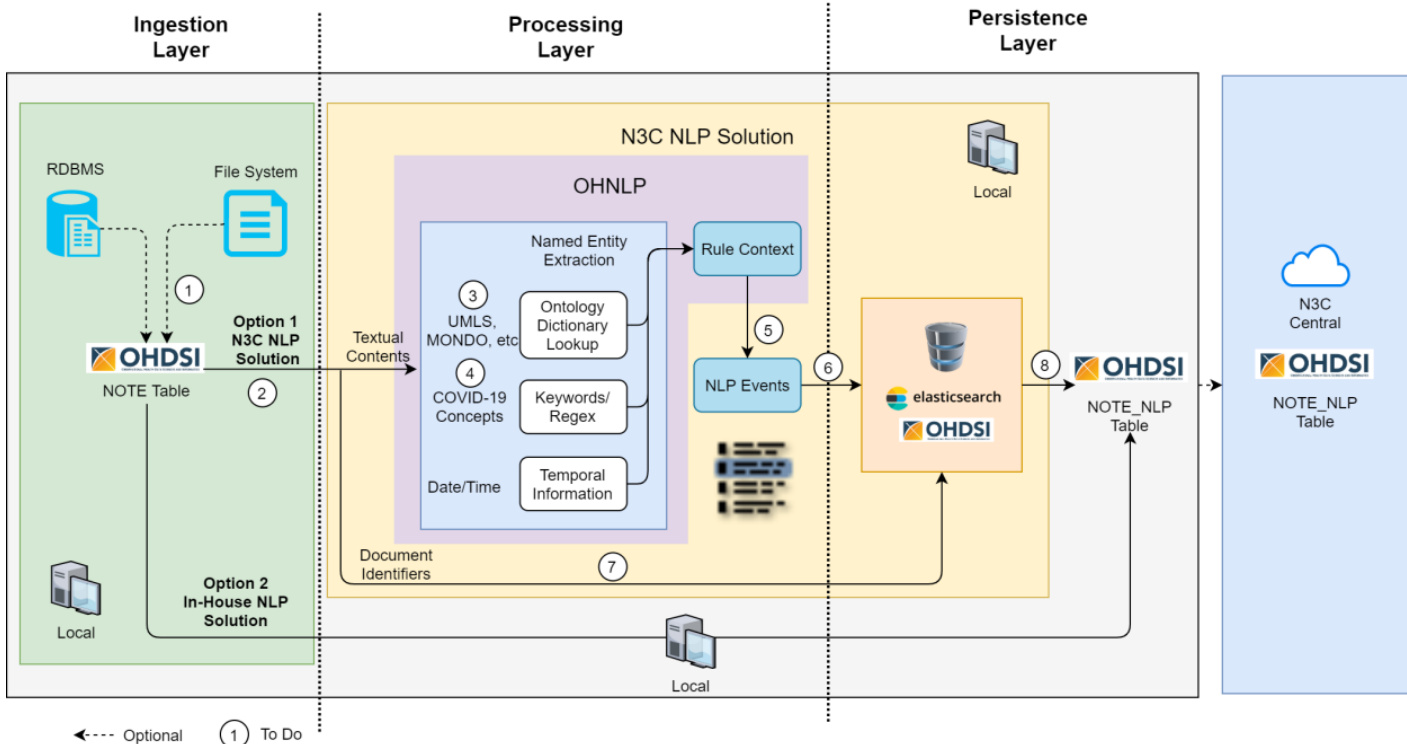
数据摄入层负责从多种来源获取临床文本,包括关系型数据库管理系统(RDBMS)和文件系统。该层级支持多种数据输入选项,默认采用OHDSI/OMOP通用数据模型(CDM)的NOTE表作为标准化输入格式。摄入流程采用模块化设计,允许通过配置更改来适配Elasticsearch、Google Cloud Storage、Amazon S3或纯文本文件等多种数据源,从而确保在不同机构基础设施下的灵活性。
处理层作为核心NLP引擎,对文本内容进行一系列转换以提取临床相关信息。该层级采用基于启发式规则和上下文分析的符号化方法,确保结果透明且可解释。核心组件包括命名实体识别、基于UMLS和MONDO的本体词典查询,以及用于关键词和模式检测的正则表达式应用。该框架支持集成多种NLP引擎(如MedTagger、Apache cTAKES和CLAMP),这些引擎可通过标准化API进行选择或替换。ConText算法的上下文规则被应用于修改提取出的疾病提及,为其补充时间与临床上下文信息。提取的信息随后被结构化为临床事件,并通过规则上下文模块进一步处理以融入领域专属知识。
持久化层将生成的NLP结果存储于OHDSI/OMOP CDM的NOTE_NLP表中,确保输出标准化,便于与下游应用集成。该框架支持本地与集中式存储选项,并可将处理后的数据上传至N3C Central等中央存储库。该层级还支持使用Elasticsearch对提取的NLP事件进行索引与查询,以提升可访问性与性能。整个管道设计具备良好的扩展性,可通过基于Web的界面自定义规则集与词典,使领域专家能够实时迭代优化并测试其NLP算法。
实验
数据包含来自Mayo Clinic的313份临床笔记、来自UKen的20份笔记以及来自UMN的36份笔记。标注员首先使用Mayo笔记进行培训,以更好地理解标注指南。标注完成后计算标注员间一致性(IAA),并通过两位标注员之间的讨论解决相应分歧,最终生成黄金标准数据集。
NLP算法开发与评估。利用已标注语料库,本文采用基于正则表达式的匹配方法开发了单站点与多站点NLP算法,该方法在临床信息提取中已被广泛采用。具体而言,对于Mayo数据,从313份已标注笔记中随机选取101份作为开发集,105份作为验证集,剩余107份作为测试集。对于UKen数据,10份用于训练,10份用于测试。对于UMN数据,18份用于训练,18份用于测试。单站点算法基于Mayo的开发集与验证集进行开发,并在Mayo测试集及UKen和UMN的全部数据上进行测试。多站点算法则通过使用UKen和UMN的训练集对单站点算法进行进一步优化生成,并在所有站点的测试集上进行测试。
本文使用精确率、召回率和F分数评估了单站点与多站点算法在有无确定性(certainty)条件下的标注概念提及性能。跨度(span)可表示为概念提及的起始位置到结束位置。确定性是概念提及的属性,包括肯定、否定、假设和可能。在不含确定性的提及级评估中,当黄金标准提及跨度与NLP检测到的提及跨度存在重叠,且概念类型(即具体体征/症状,如发热、咳嗽)相同时,视为真阳性(TP)。若概念提及存在于
黄金标准标注中但未被NLP算法检测到,或跨度重叠但概念类型不匹配,则视为假阴性(FN)。若算法检测到某概念提及但黄金标准标注中不存在,则视为假阳性(FP)。在进行提及级跨度与确定性评估时,计算TP、FN和FP需考虑确定性匹配。随后计算精确率、召回率和F分数。本文进一步对多站点算法在无确定性条件下的提及级评估误差进行了人工分析。
P r e c i s i o n =TP+FNTP Recall=TP+FNTP F1=Precision+Recall2⋅Precision⋅Recall- 图表
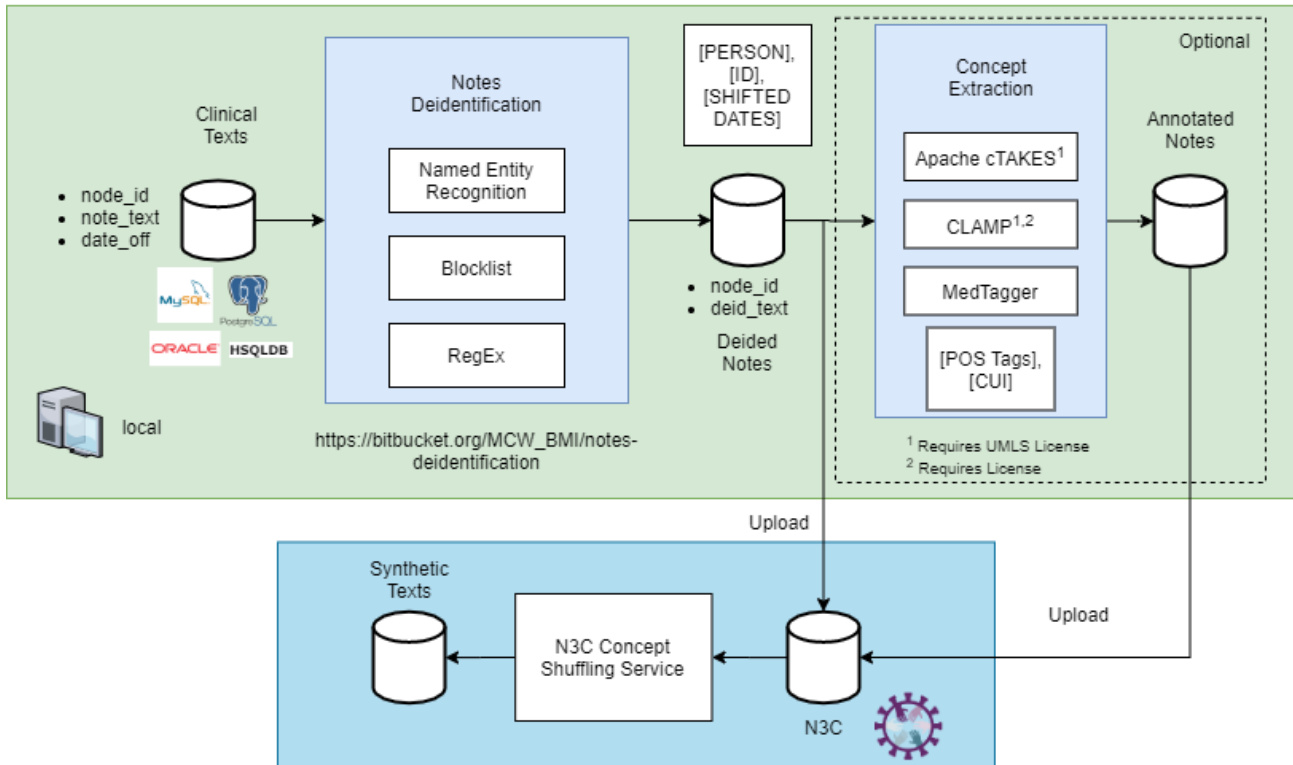
图. N3C脱敏与合成文本生成工作流
图. Web图形用户界面截图
- 表格
表. 标注语料库统计信息。(Mayo:Mayo Clinic,UKen:University of Kentucky,UMN:University of Minnesota)
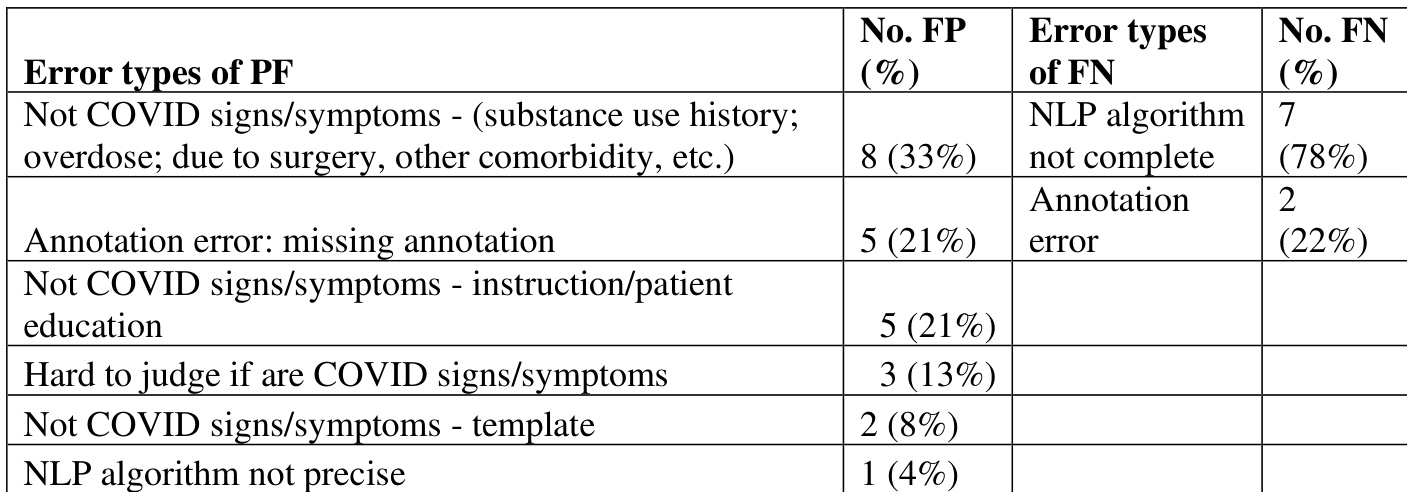
表. 单站点NLP算法性能(Mayo:Mayo Clinic,UKen:University of Kentucky,UMN:University of Minnesota)
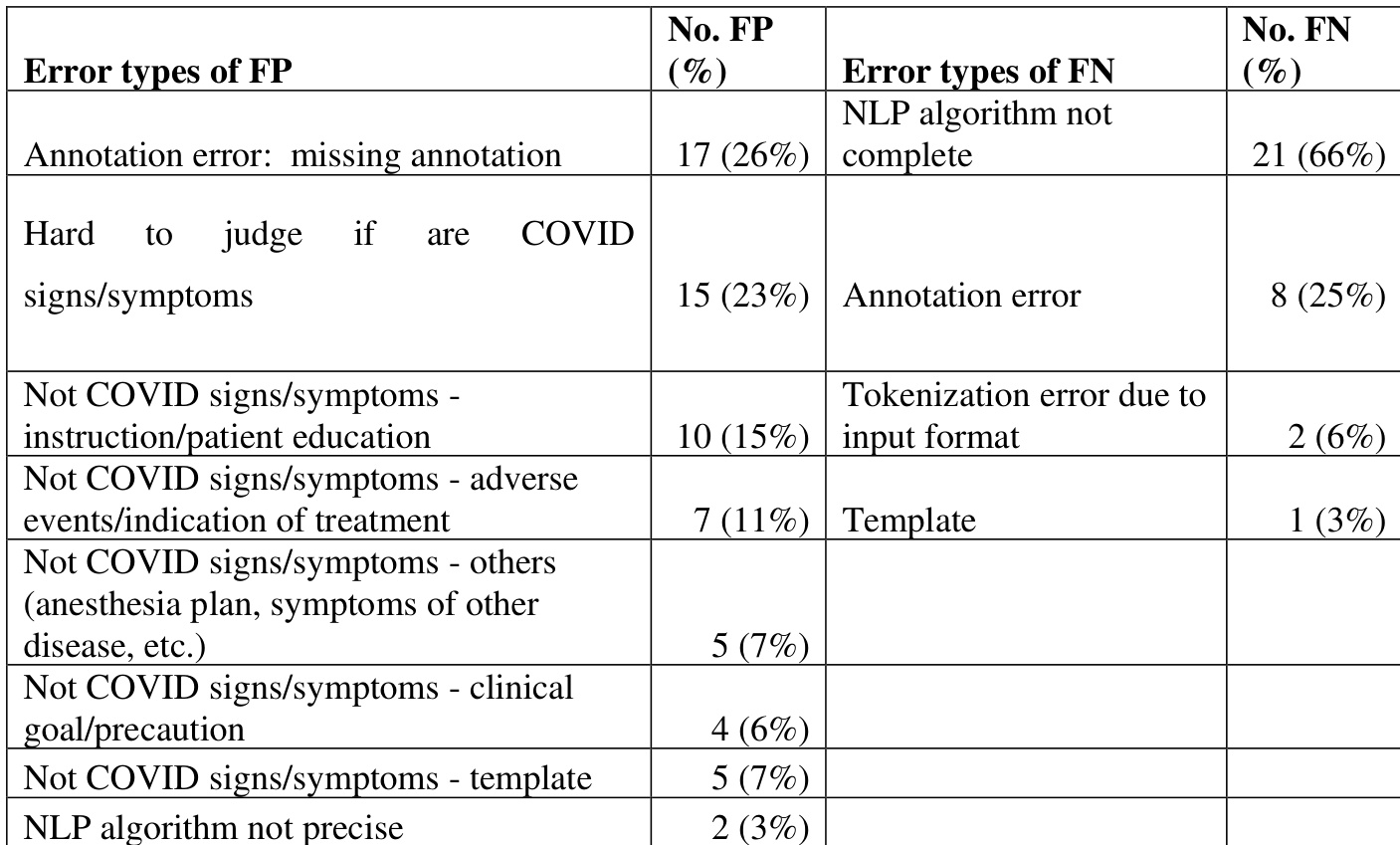
表. 多站点NLP算法性能(Mayo:Mayo Clinic,UKentucky:University of Kentucky,UMN:University of Minnesota)

表. Mayo站点多站点算法无确定性提及级评估误差分析
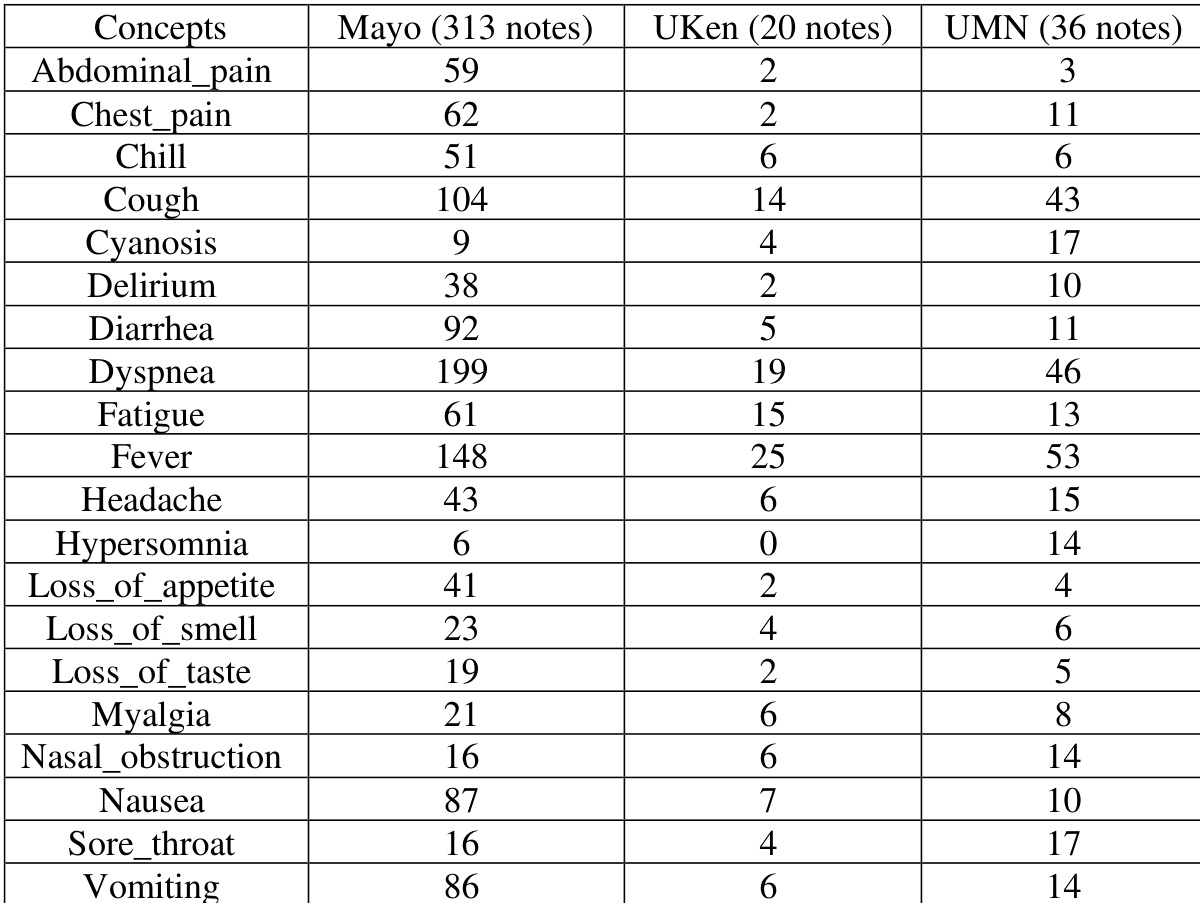
表. UMN站点多站点算法无确定性提及级评估误差分析
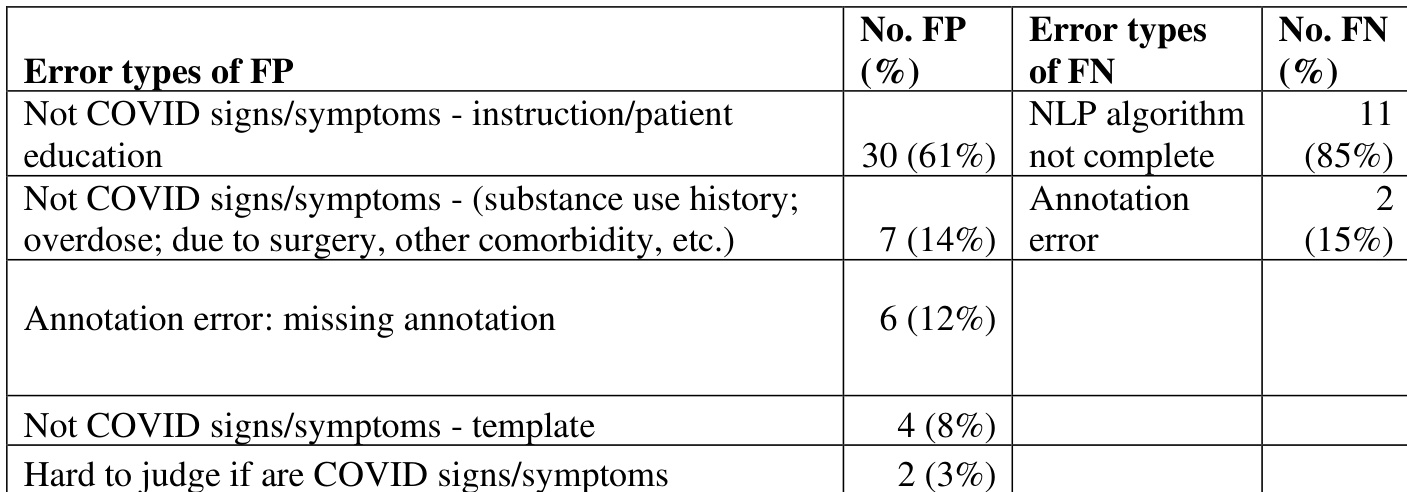
表. UKen站点多站点算法无确定性提及级评估误差分析

作者评估了单站点与多站点NLP算法在从三家机构临床笔记中提取COVID-19体征与症状方面的性能。结果表明,多站点算法的性能优于单站点算法,且在所有数据集中呈现一致趋势。当算法应用于非主要训练站点时,两者的性能均出现下降。多站点NLP算法在所有测试数据集上的表现均优于单站点算法。对于两种算法,性能均从主要训练站点向其他站点递减。在跨度(Span)评估中,多站点算法的召回率高于单站点算法,但精确率较低。

作者对多站点NLP算法的性能进行了误差分析,重点关注假阳性与假阴性。分析显示,绝大多数假阳性源于非COVID相关提及(如物质使用史和患者教育),而假阴性主要归因于NLP算法不完整及标注错误。假阳性主要由非COVID相关提及(如物质使用史和患者教育)引起。假阴性主要源于不完整的NLP算法与标注错误。误差分析表明,大量假阳性和假阴性与上下文误读及系统局限性有关。
作者对用于提取COVID-19体征与症状的多站点NLP算法进行了误差分析,聚焦于假阳性与假阴性。分析表明,多数假阳性源于标注错误与非COVID相关内容,而假阴性主要归因于标注不完整及分词问题。假阳性主要由标注错误及患者教育和治疗说明等非COVID相关内容引起。假阴性则主要源于脱敏过程导致的标注不完整与分词错误。误差分析强调,标注与算法的双重局限性对NLP系统的性能差距产生了显著影响。
作者评估了单站点与多站点NLP算法在从三家机构临床笔记中提取COVID-19体征与症状方面的性能。结果表明,多站点算法性能优于单站点算法,所有站点的F分数均呈现一致提升,尽管站点间性能存在差异,且Mayo数据集上的表现普遍较高。多站点NLP算法在所有评估指标与站点上均优于单站点算法。两种NLP算法的性能均从Mayo站点向其他两个站点递减。与单站点算法相比,多站点算法的F分数有所提升,尤其在UMN和UKen数据集上表现更为明显。
作者开展了一项研究,以评估NLP算法在跨多站点临床笔记中提取COVID-19体征与症状的性能。结果表明,与单站点算法相比,多站点NLP算法提升了整体性能,所有站点的F分数均更高,尽管性能从Mayo站点向其他站点有所下降。标注数据显示各机构间症状提及频率存在显著差异,Mayo在大多数症状上的计数较高。多站点NLP算法在所有站点上的表现均优于单站点算法。NLP算法的性能从Mayo站点向其他站点递减,表明存在站点特异性差异。标注数据揭示了各机构间症状流行率的显著差异,Mayo在大多数症状上的计数较高。
作者评估了单站点与多站点自然语言处理算法在跨三家机构提取COVID-19临床体征与症状方面的性能,通过对比试验验证了跨站点泛化能力,并通过后续误差分析明确了失效模式。实验一致表明,多站点方法优于单站点基线,尽管两种模型在应用于非训练站点时均出现性能下降。误差分析显示,错误分类主要源于上下文误读、非COVID相关临床文档及标注不一致,而非算法固有缺陷。这些发现凸显了多机构训练数据的价值,同时强调了文档变异性与标注质量对系统可靠性的显著影响。