Command Palette
Search for a command to run...
问答系统
摘要
一句话总结
本文提出了一种功能丰富的系统,用于 SemEval-2016 Task 3 社区问答任务。该系统通过整合语义、词汇、元数据及用户相关特征,在子任务 C 上取得最佳结果,在子任务 A 和 B 上表现强劲。其性能主要得益于问题与评论的元数据、在 QatarLiving 数据上训练的语义向量,以及问题与评论或相关问题之间的相似度度量。
核心贡献
- 本研究提出了一种专为 SemEval-2016 Task 3 社区问答任务开发的系统,该系统整合了语义、词汇、元数据及用户相关特征。
- 该方法构建了一个特征集,融合了问题与评论的元数据、在 QatarLiving 数据上训练的语义向量,以及问题与评论或相关问题之间的相似度得分。
- 评估结果显示,该系统在子任务 C 上取得最高分,在子任务 A 和 B 上表现优异,其中元数据和基于 QatarLiving 训练的语义向量被证实为最具影响力的核心组件。
引言
社区问答平台依赖自动将问题匹配至相关答案或评论,以提升信息检索效率并降低人工审核成本。现有方法通常难以有效整合多样化的信号类型,或未能充分利用讨论线程中的结构上下文,从而限制了其排序与分类的准确性。本文作者利用涵盖语义向量、词汇线索、元数据及用户相关属性的综合特征集,构建了一个鲁棒的匹配系统。该特征丰富的架构在 SemEval-2016 Task 3 基准测试中取得了顶尖性能,证明精心设计的多模态信号在社区问答中依然高度有效,并为未来基于线程感知的模型及神经网络扩展奠定了坚实基础。
数据集
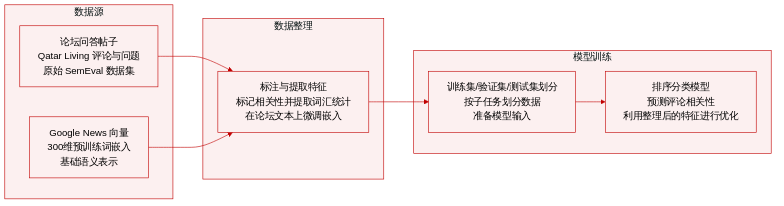
- 数据集构成与来源: 本文作者使用了由任务主办方提供、源自 Qatar Living Forum 的 SemEval-2016 Task 3 社区问答数据集。
- 子集详情: 子任务 A 包含 6,398 个问题及 40,288 条评论,标注为 Good、PotentiallyUseful 或 Bad。子任务 B 包含 317 个原始问题与 3,169 个相关问题,标注为 PerfectMatch、Relevant 或 Irrelevant。子任务 C 将 317 个原始问题与 3,169 个相关问题同 31,690 条评论相结合。
- 数据使用与处理: 作者将数据集划分为训练集与测试集,覆盖全部三个子任务。系统以在 Google News 上预训练的 300 维向量初始化语义表示,并进一步在论坛的 20 万个问题与两百万条评论上微调嵌入向量。处理后的数据直接输入至排序与分类模型中。
- 元数据构建与特征工程: 作者通过追踪评论位置、作者身份、相对于问题的长度比例,以及线程内用户的发帖频率与顺序来提取线程元数据。词汇特征经由 GATE 流水线与手工规则处理,以捕获命名实体、词性统计、可读性指数、拼写与不当词汇标记,以及点互信息(Pointwise Mutual Information)得分。作者还爬取了补充用户资料,用于追踪注册日期、活动时间戳、发帖量及喷子行为指标,但指出这些属性对性能提升微乎其微。系统还包含了入站与出站引用的辅助链接追踪,但作者观察到不到 10% 的评论包含链接,且这些特征对最终结果的贡献极小。
方法
本文作者采用了 Zamanov 等人(2015)开发的框架,该框架最初专为 SemEval-2015 Task 3 社区问答答案选择任务设计。系统将该当前任务视为分类问题,并适配至排序场景,其目标是根据答案或评论与给定问题的相关性进行排序。从分类到排序的转换需要一种特征丰富的表示方法,以同时捕捉问题与候选响应之间的词汇与语义关系。
整体架构整合了多种类型的特征,包括元数据、词汇、基于距离、可读性及语义特征。元数据特征包含同一用户在线程中的发帖数量、问题作者 ID 及用户可信度指标等信息。词汇特征捕捉词级统计与模式,距离度量则评估问题与评论或答案之间的结构邻近度。可读性指标同时应用于问题与评论,以评估语言复杂度与清晰度。

如图所示,该框架的一个核心组件是语义特征提取模块,旨在量化问题与评论或答案之间的语义相似度。该目标通过两种主要方法实现:主题建模与基于词嵌入的表示。在主题建模方面,使用 Mallet 构建了一个包含 100 个主题模型,并计算问题与评论主题分布之间的余弦距离。此举捕捉了文本间高层级的主题对齐关系。
此外,系统采用基于 word2vec 的语义向量来表示词与短语的含义。作者对多种向量训练配置进行了实验,最终选择在 QatarLiving 论坛未标注数据上训练的向量。这些向量针对论坛的语言特征进行了优化,涵盖了常见拼写错误与非正式表达。为增强鲁棒性,分词(token)过程包含了数字、表情符号、URL 及图片的特殊标识符。对于每个问题-评论对,系统计算问题与评论的质心向量,并将其分量作为分类器的输入特征。
评论或答案的可信度通过一个独立模块进行进一步评估,该模块在推文数据集上训练。该模块采用基于 Apache Spark 实现的线性支持向量机(SVM),结合随机梯度下降与 L2 正则化。用于可信度预测的特征包括文本长度、特殊标点符号的存在与否、表情符号、人称代词(第一与第三人称)、用户提及及 URL。预测出的可信度标签及其关联概率被作为附加特征整合至最终分类流程中。
实验
评估环节采用 SVM 分类器,在三个社区问答子任务上检验了多特征系统的表现,并设计了针对性实验以验证特征重要性并优化语义表示。基于排除法的测试表明,元数据特征、跨文本相似度度量以及领域适配的语义向量是最关键的组件,而用户统计信息与基础文本属性贡献甚微。额外的向量优化实验证实,直接在论坛数据上训练嵌入向量,并结合领域特定符号与统一词汇包含策略,能显著提升预测对齐效果。总体而言,研究结果表明,整合聚焦的语义与元数据特征能有效捕捉社区交互动态,尽管在相关问题子任务上的有限测试显示出相对较弱的性能。
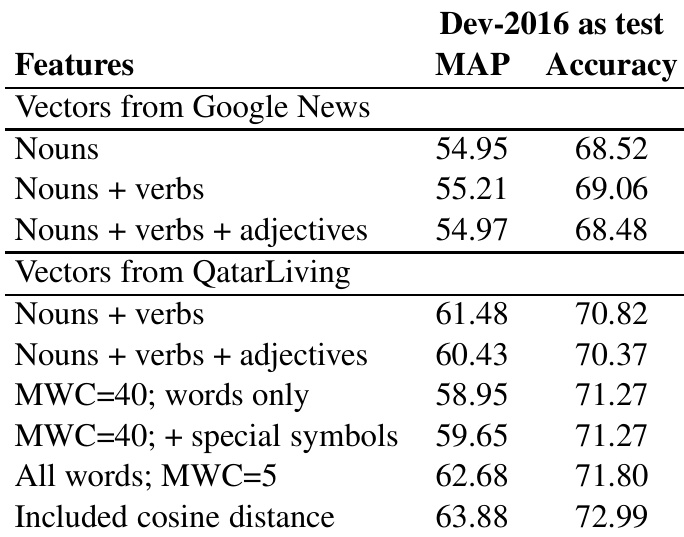
作者对比了用于特征提取的不同语义向量方法,并使用 MAP 与准确率指标评估其对性能的影响。结果显示,在 QatarLiving 数据上训练的向量表现优于 Google News 向量,其中包含特殊符号及使用全部词汇的配置取得了更佳效果。在 QatarLiving 数据上训练的向量性能高于 Google News 向量。将特殊符号作为词汇纳入可提升语义向量性能。在向量质心中使用所有词性的全部词汇,比仅使用特定词性所得结果更优。
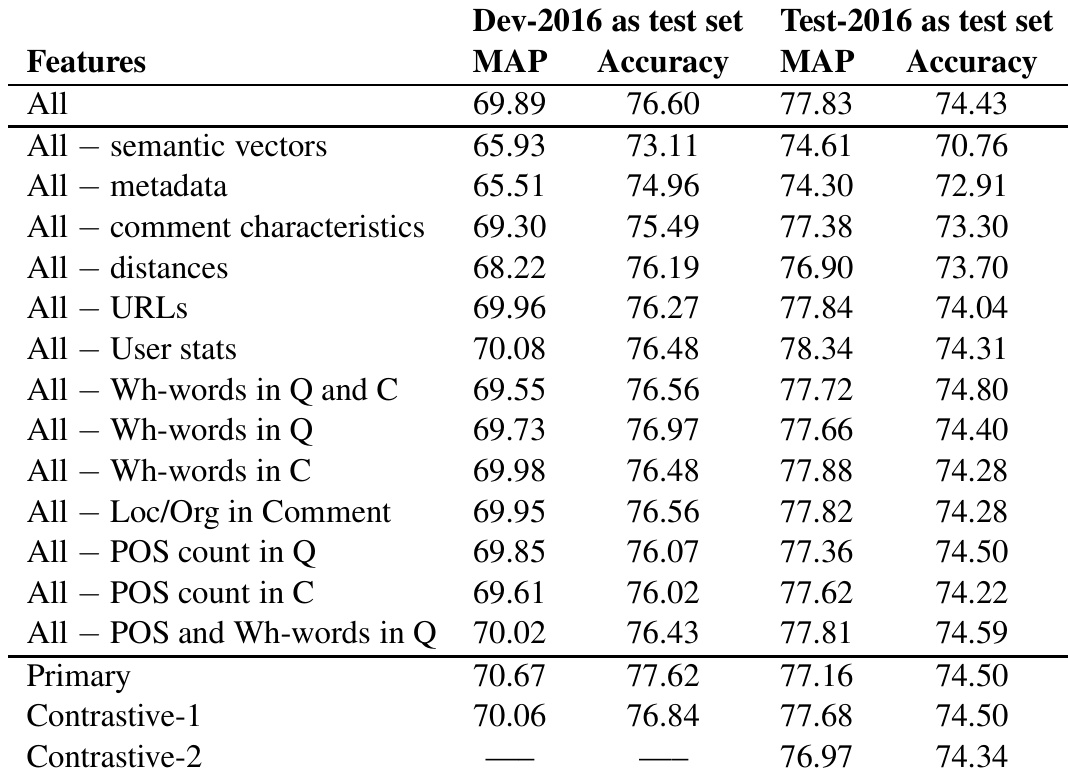
作者开展实验以评估不同特征组对社区问答任务性能的影响。结果表明,移除语义向量或元数据会显著降低性能,而排除其他特征类型的影响相对较小。表现最佳的模型整合了所有特征,其中主提交模型在两个测试集上均取得了强劲结果。与使用全部特征相比,移除语义向量或元数据会导致性能大幅下滑。排除评论特征、URL 或词性统计等其他特征组对结果的影响较小。包含所有特征的主模型在两个测试集上均实现了最高性能。
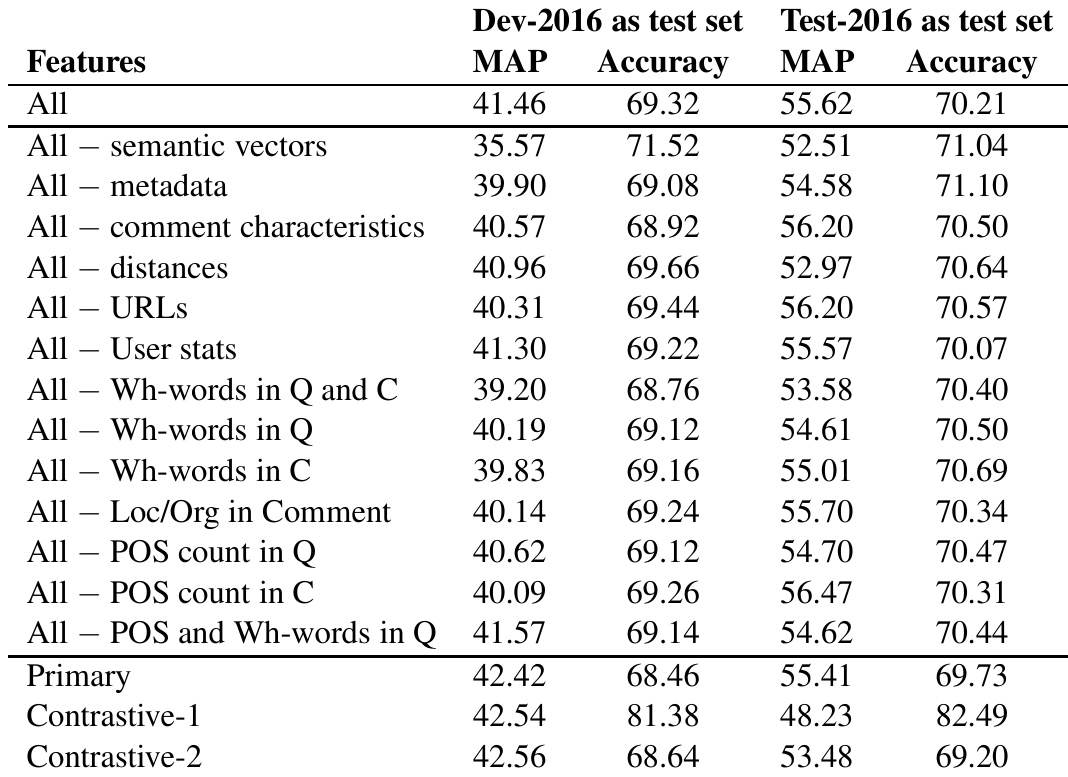
作者通过一系列排除特定特征集的实验,评估了不同特征组对社区问答任务模型性能的影响。结果表明,语义向量与元数据特征对性能贡献显著,而用户相关特征及部分语言统计指标影响甚微。表现最佳的模型整合了全面特征集,在开发集与测试集上的准确率与 MAP 得分均有显著提升。语义向量与元数据特征对模型性能最具影响力。排除用户相关特征及部分语言统计指标对结果影响极小。整合全部特征的模型在开发集与测试集上均取得了最高准确率与 MAP 得分。
作者评估了不同特征组对社区问答任务模型性能的影响。结果表明,将语义向量与元数据及距离度量结合可提升性能,而移除语义向量则会导致指标下降。当包含所有特征时,整体性能达到最优。与单独使用语义向量相比,结合元数据与距离度量能进一步提升性能。从特征集中移除语义向量会导致 MAP 与准确率指标双双下降。包含全部特征组时性能最佳,印证了各特征组合的重要性。
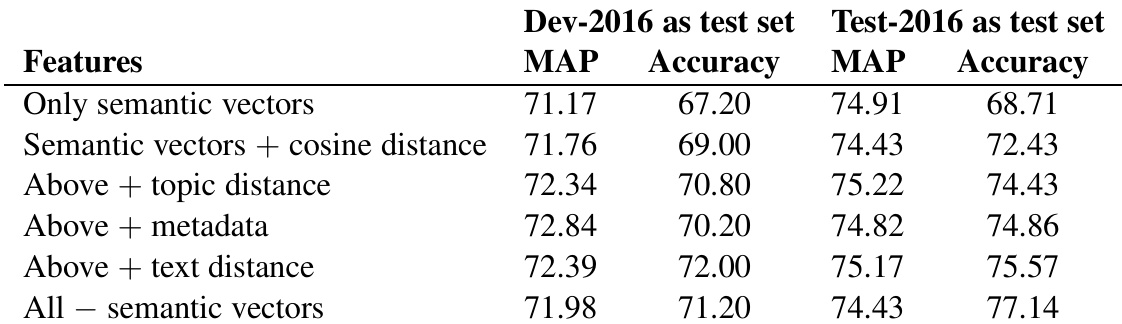
作者通过一系列消融实验与对比实验,评估了各特征组对社区问答任务的贡献。测试验证了领域适配的语义向量与元数据是最关键的组件,移除它们会导致性能大幅下滑,而用户相关属性与语言统计指标影响微乎其微。最终,语义向量、元数据与距离度量的全面整合始终能产生最强结果,证明融合多样化特征类型对于实现模型最优性能至关重要。