Command Palette
Search for a command to run...
r-GAT:面向多关系图的 relational Graph Attention Network
r-GAT:面向多关系图的 relational Graph Attention Network
Meiqi Chen Yuan Zhang Xiaoyu Kou Yuntao Li Yan Zhang
图注意力网络(GAT)
摘要
Graph Attention Network(GAT)仅关注对简单无向和单一关系图数据的建模。这限制了其处理更通用且复杂的多关系图的能力,而多关系图中包含具有不同标签有向链接的实体(例如知识图谱)。因此,直接将 GAT 应用于多关系图会导致次优解。为解决这一问题,我们提出了 r-GAT,一种用于学习多通道实体表示的关系图注意力网络。具体而言,每个通道对应实体的一个潜在语义方面。这使得我们能够利用关系特征聚合当前方面的邻域信息。我们还提出了一种查询感知的注意力机制,用于后续任务中选择有用的方面。在链接预测和实体分类任务上的大量实验表明,我们的 r-GAT 能够有效建模多关系图。此外,我们通过案例研究展示了该方法的可解释性。
一句话总结
作者提出了 r-GAT,这是一种关系图注意力网络,通过学习多通道实体表示(每个通道捕捉不同的潜在语义方面),并结合特定关系的邻域聚合与查询感知注意力机制,为链接预测和实体分类任务选择有用的语义方面,从而将标准 GAT 扩展至多关系图。
核心贡献
- 本文提出了 r-GAT,这是一种关系图注意力网络,通过将每个通道映射到潜在语义方面,并利用关系特征聚合邻域信息,从而学习多通道实体表示。
- 该架构引入了查询感知注意力机制,为下游任务选择相关的语义方面,并通过避免为特定关系类型设置专用参数来防止参数冗余。
- 在链接预测和实体分类任务上的大量实验表明,与现有的基于 GNN 的方法相比,r-GAT 具有更高的有效性和参数效率,案例研究进一步验证了注意力权重的可解释性。
引言
图注意力网络在知识图谱补全和文本分类等应用中处理图结构数据方面表现出强大的性能。然而,大多数现有模型专为单关系图设计,在处理带有不同语义含义边的多关系图时面临困难。标准注意力机制忽略了特定关系的特征,迫使网络学习静态的通用表示,无法解耦不同的语义方面,也无法适应特定的下游查询。先前的多关系方法通常随着关系类型的增加而出现参数冗余问题,或者未能根据关系上下文动态调整邻居的重要性。为了克服这些局限性,作者提出了 r-GAT,这是一种关系图注意力网络,将实体和关系投影到独立的语义通道中。通过将关系特征直接集成到注意力机制中,该模型能够根据语义上下文动态加权邻居,并将实体表示解耦为独立组件。作者进一步在该框架中引入了查询感知注意力机制,为下游任务选择性地激活相关语义方面,从而提升模型性能、参数效率及可解释性。
数据集
- 数据集构成与来源: 作者使用源自 Freebase 和 WordNet 的两类多关系图数据集来评估其 r-GAT 模型。
- 子集详情:
- FB15k-237:源自 Freebase 的过滤后知识图谱子集。移除了反向关系以消除简单的预测捷径并增加任务难度。
- WN18RR:经过精心筛选的 WordNet 子集。应用了严格过滤以防止通过简单反转训练三元组导致的测试数据泄露。
- AIFB、MUTAG 和 BGS:三个专门用于实体分类任务的标准数据集。完整的统计数据和元数据记录在论文的参考表与附录中。
- 数据使用与处理: 这些数据集未合并为单一混合数据集。作者将其作为独立的基准划分,用于评估两项不同任务:使用 FB15k-237 和 WN18RR 进行链接预测,使用 AIFB、MUTAG 和 BGS 进行实体分类。标准预处理流程确保每个子集符合既定的多关系图评估规范。
- 额外处理说明: 主要处理步骤涉及关系过滤,以移除反向链接并防止数据泄露。未采用裁剪策略,清理后的图保持其原始结构格式。
方法
作者提出了 r-GAT,这是一种关系图注意力网络,旨在通过学习跨越多个语义方面的解耦实体表示来建模多关系图。该框架通过将实体和关系特征分解为 K 个独立通道来运作,其中每个通道捕捉实体的一个独特潜在语义方面。这种分解使模型能够执行关系感知邻域聚合,从而根据实体特征及其连接的关系特征来加权邻居实体的贡献。
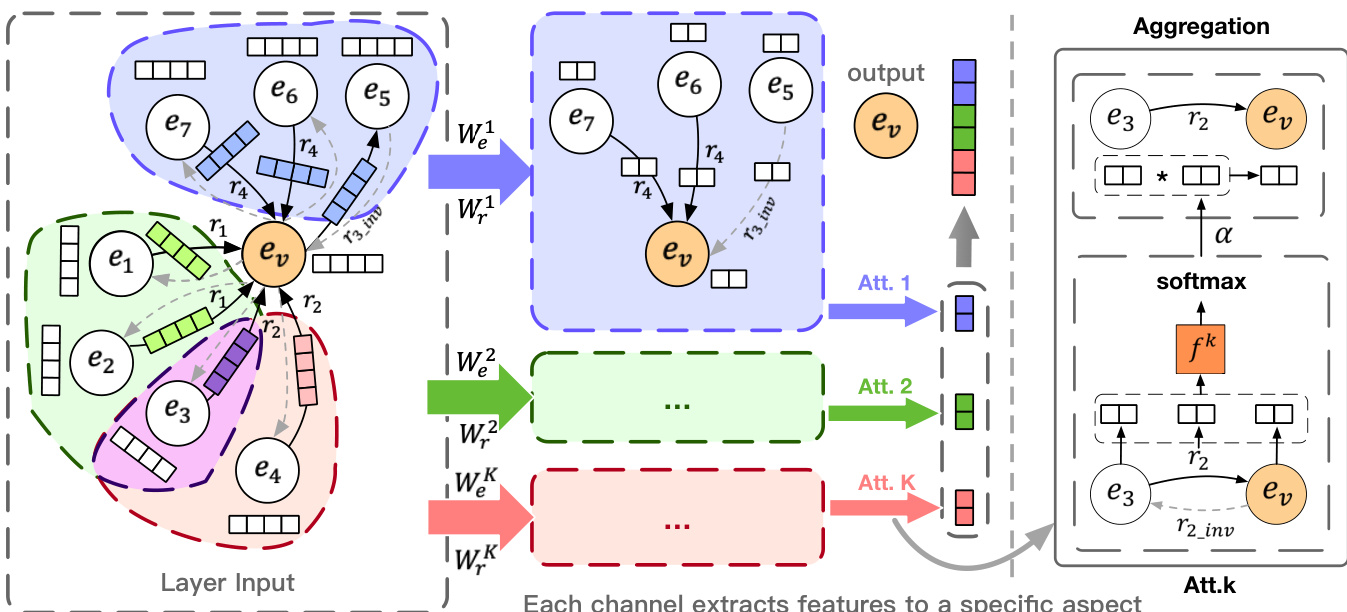
如下图所示,该架构通过一系列 K 个并行通道处理实体和关系特征。每个通道应用一个可学习的投影矩阵,将输入的实体和关系特征转换到共享子空间。对于边 (v,i,u),投影后的实体特征 evk=Wekev 和关系特征 rik=Wrkri 用于计算注意力分数,以衡量在第 k 个语义方面下邻居 u 对实体 v 的相关性。注意力机制定义为 attviuk=fk[evk∣∣rik∣∣euk],其中 fk 为前馈网络。注意力分数通过对与 v 连接的所有邻居和关系使用 softmax 函数进行归一化,得到 αviuk,该值量化了邻居 u 对 v 第 k 个方面的重要性。
随后,第 k 个通道中实体 v 的聚合表示计算为 evk(l)=σ1(∑u∈Nv∑i∈Rv,uαviuk[euk∗rik]),其中乘法 ∗ 将邻居的实体特征与关系特征进行结合。最终的解耦实体表示 ev(l) 通过拼接所有 K 个通道的输出获得,形成一个维度为 De(l) 的特征向量。该过程在多个层中重复执行,以捕获高阶邻域信息。
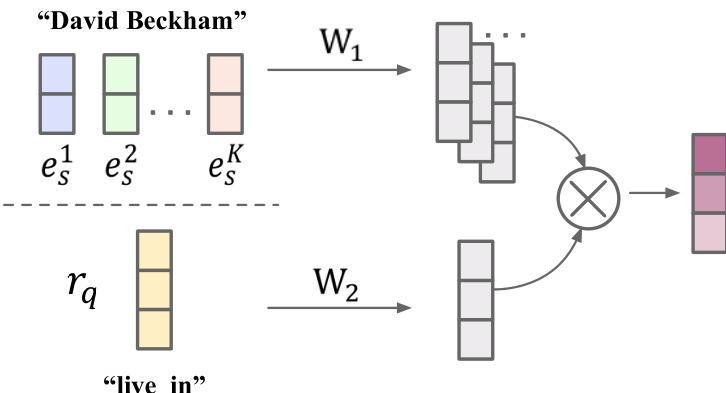
针对下游任务,模型引入了查询感知注意力机制,以将解耦表示适配至特定的查询关系。给定查询关系 q 和主体实体 s,s 的每个语义方面 k 对 q 的重要性计算为 βsqk=softmaxk(Dq(W1esk)T(W2rq))。该注意力权重用于生成查询感知的实体嵌入 Q(es,rq),将 s 的相关方面与查询关系相结合。该机制使模型在执行链接预测等任务时能够聚焦于语义相关的特征,从而缓解传统基于 GNN 方法中固有的查询无关问题。
实验
评估在多个基准数据集上采用标准的链接预测和实体分类协议,并将所提方法与一套全面的图神经网络及知识图谱嵌入基线方法进行比较。整体结果表明,该模型有效将实体特征解耦至多个语义通道,使其能够捕获复杂的关系上下文并超越现有方法。消融研究进一步验证了查询感知注意力机制与多通道架构对于动态、特定查询推理的必要性,因为单通道变体会退化为通用嵌入。最后,案例研究揭示了不同关系如何通过专用通道动态优先处理语义相关的实体事实,从而与人类常识预期保持一致,突显了模型的可解释性。
作者在 FB15k-237 和 WN18RR 两个数据集上,将 r-GAT 模型与多种前沿方法在链接预测任务上进行了对比。结果表明,r-GAT 在两个数据集上均取得了具有竞争力的性能,在 FB15k-237 上提升尤为显著,表明其在处理复杂关系上下文方面的有效性。该模型在 Hits@10 和 MRR 等指标上优于其他基于 GNN 和 KGE 的方法,说明解耦特征表示与查询感知注意力机制对提升性能具有积极作用。r-GAT 在 FB15k-237 上的多项指标均达到最优,证明了其处理复杂关系数据的能力。该模型在两个数据集上均超越了强基线方法,在 Hits@10 和 MRR 上取得显著提升,凸显了解耦特征学习的优势。模型在关系结构更丰富的 FB15k-237 上表现尤为突出,表明其具备捕获细粒度上下文信息的能力。
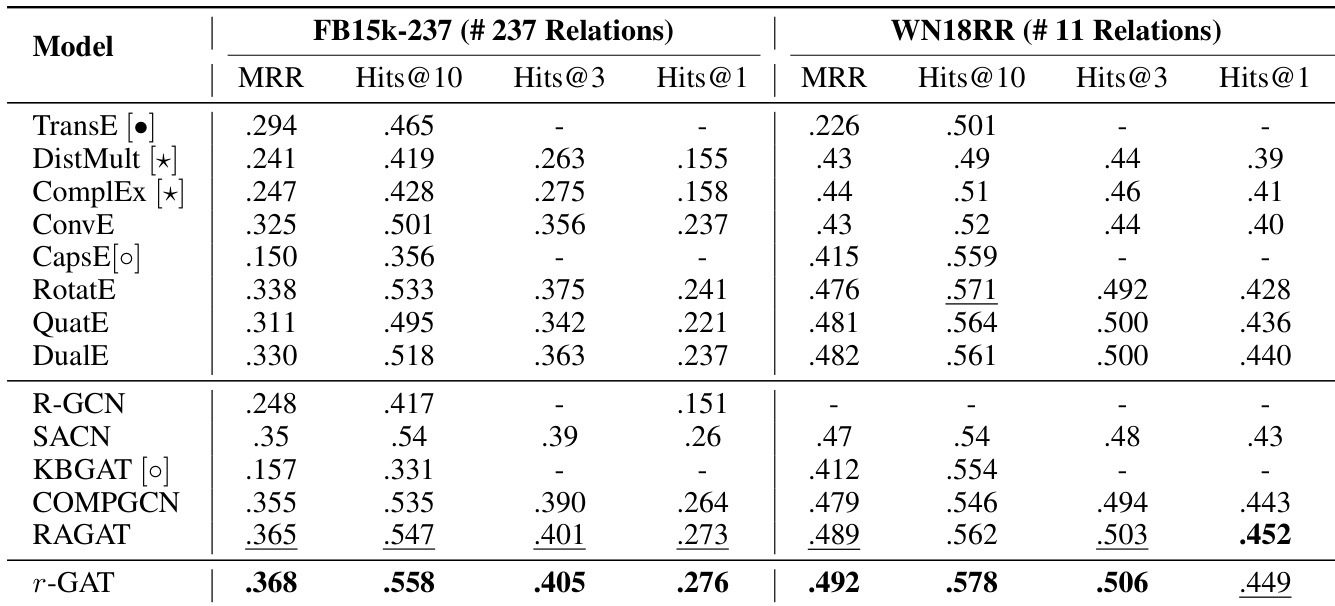
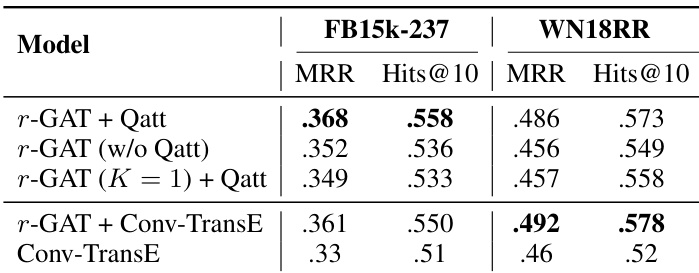
作者在链接预测任务上评估了所提出的 r-GAT 模型,并将其与多种基线及消融变体进行比较。结果表明,包含查询感知注意力的完整模型性能最佳,而移除该组件或使用单通道会显著降低结果。当与 Conv-TransE 结合时,该模型的表现也优于单独的 Conv-TransE,尤其是在涉及高连接度实体的挑战性案例中。与消融版本相比,带有查询感知注意力的完整 r-GAT 模型在两个数据集上均取得最佳性能。移除查询感知注意力机制会导致性能明显下降,凸显了其重要性。将 r-GAT 与 Conv-TransE 结合使用,其结果优于单独使用 Conv-TransE,尤其针对高连接度实体效果显著。
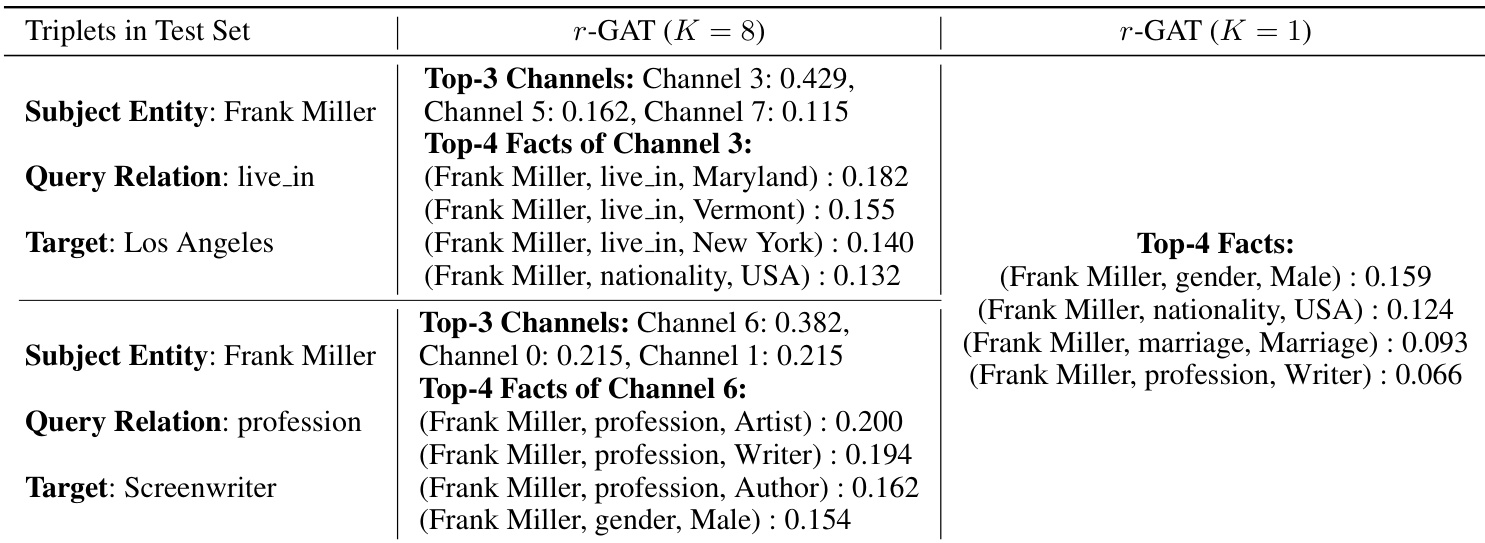
作者通过链接预测案例展示了 r-GAT 模型的可解释性。表格显示,不同的查询关系会在多个解耦通道中产生不同的注意力模式,突显了模型根据查询动态调整关注点以匹配相关事实的能力。相比之下,单通道版本的模型会产生静态且区分度较低的注意力,无法捕捉特定于查询的相关性。不同的查询关系会激活不同的解耦通道集,使模型能够聚焦于语义相关的事实。该模型的注意力机制允许根据查询关系对已知事实进行动态加权,从而增强了可解释性。单通道变体缺乏查询感知能力,产生均匀的注意力分布,降低了其区分相关信息的能力。
作者在多个数据集上开展了链接预测与实体分类实验,将所提出的 r-GAT 模型与多种基于 GNN 和 KGE 的基线方法进行了对比。结果表明,r-GAT 在 FB15k-237 上取得了最先进的性能,并在所有数据集的实体分类任务上超越了所有先前方法,证明了实体特征解耦与查询感知注意力的有效性。在链接预测任务中,r-GAT 在 FB15k-237 上达到最优水平,在 WN18RR 上表现具有竞争力。在所有数据集的实体分类任务中,r-GAT 均优于所有基线方法。消融研究进一步确认了查询感知注意力与多通道解耦对性能提升的关键作用。

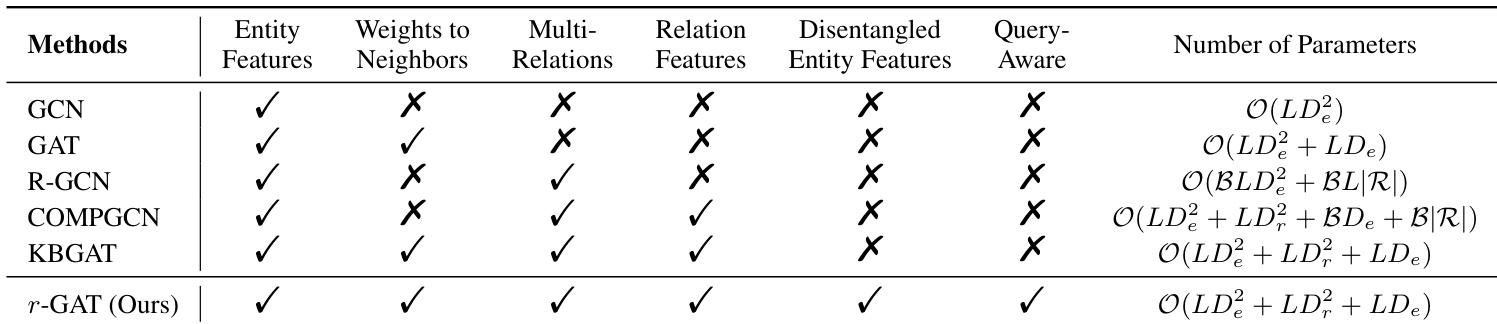
作者将所提出的 r-GAT 模型与多种基线方法进行了对比,强调 r-GAT 融合了多项特性,包括实体特征、邻居权重、多关系、解耦实体特征以及查询感知机制。表格显示,在所列方法中,r-GAT 是唯一同时利用所有这些组件的方法,这为其在链接预测和实体分类任务中的优异表现提供了支撑。r-GAT 是表格中列出的唯一采用所有特性(包括解耦实体特征与查询感知机制)的方法。r-GAT 引入查询感知机制,使其能够通过聚焦相关解耦通道来适配不同的查询关系。在链接预测和实体分类任务中,r-GAT 均超越了所有基线模型,证明了其全面特征整合策略的有效性。
r-GAT 模型在 FB15k-237 和 WN18RR 数据集上接受了链接预测与实体分类任务的评估,并与多种图神经网络及知识图谱嵌入基线方法进行了基准测试。对比实验证明了其在复杂关系数据上具有更优越的预测精度,而消融研究则确认移除查询感知注意力或多通道解耦会显著降低性能。可解释性案例分析进一步验证了该架构能够动态地将注意力路由至特定于查询的事实,这与单通道替代方案的静态行为形成鲜明对比。综合来看,这些发现表明,将解耦特征与自适应注意力机制相结合,能够显著提升模型的有效性与可解释性。