Command Palette
Search for a command to run...
在 PyTorch 上使用 GPT-2 进行最小化训练
摘要
一句话总结
通过对公开数据集进行 GPT-2 复现实验,作者发现早期长序列会引发极端的梯度方差与稳定性-效率困境,随后提出序列长度预热(Sequence Length Warmup)方法以缓解该不稳定性,并在不损害泛化精度的前提下实现高效的 GPT 模型预训练。
核心贡献
- 基于 GPT-2 模型的复现经验分析确立了训练不稳定性与极端梯度方差之间的强相关性。该研究进一步指出,在训练早期阶段,长序列长度是导致该不稳定性的主要驱动因素。
- 引入序列长度预热方法,通过逐步调整序列长度来稳定梯度方差,并辅以一种轻量级调优策略,仅需占用全部训练预算的一小部分。
- 在 GPT-3 规模模型上的评估表明,该方法支持使用更激进的超参数进行稳定预训练,使数据需求降低十倍,实际训练时间缩短至原来的十七分之一。
引言
大规模自回归语言模型的预训练需要消耗大量计算资源,使得训练效率成为研究与实际部署的关键瓶颈。实践者通常通过增大批量大小和学习率来加速收敛,但该方法会引发稳定性与效率的困境:激进的设置会导致极端梯度方差及频繁的训练发散。现有的缓解策略(如梯度裁剪或标准预热调度)往往无法稳定十亿参数级模型,或为追求速度而牺牲鲁棒性。为弥补这一空白,作者分析了预训练动态过程,并将长序列长度确定为梯度方差突增的主要来源。随后,作者提出序列长度预热方法,这是一种类似课程学习的技术,在训练早期阶段逐步增加序列长度。该方法支持使用显著更大的批量大小和学习率进行稳定优化,在保持零样本精度的同时,大幅缩短实际训练时间并降低数据需求。作者还提供了一种轻量级超参数调优策略,可在不产生完整预训练成本的情况下快速适配该方法。
数据集
- 数据集构成与来源:提供的摘录中未明确说明数据集的构成或来源。
- 各子集关键细节:未包含子集规模、来源或过滤规则。
- 论文的数据使用方式:未描述训练集划分、混合比例及数据利用策略。
- 处理细节:提交的文本中未概述裁剪策略、元数据构建或预处理步骤。
方法
作者采用序列长度预热(SLW)策略来解决预训练期间的训练不稳定性,尤其针对对长输入序列敏感的 GPT-2 等模型。核心思想是初期使用短序列长度开始训练以确保稳定性,并随时间逐步增加序列长度,使模型最终能够利用更长的上下文信息进行学习。该方法需要两个关键组件:训练期间对可变序列长度的支持,以及用于确定每个训练步骤序列长度的 pacing 函数。
为高效支持可变序列长度,作者实现了一种基于截断的方法,避免了为所有可能序列长度预先索引数据所带来的开销。在此方法中,数据加载器最初将原始文本索引为完整序列长度的序列。在每个训练步骤中,pacing 函数确定目标序列长度,完整长度序列随之进行截断以构成 mini-batch。尽管该方法在每一步会导致部分数据被丢弃,但作者指出,被丢弃的数据索引可被记录并在后续步骤中重复使用,从而随时间推移减轻数据丢失问题。
pacing 函数被定义为分段线性函数,第 t 步的序列长度由下式给出:
seqlent=seqlens+(seqlene−seqlens)×min(Tt,1)其中,seqlens 为起始序列长度,seqlene 为结束(完整)序列长度,T 为序列长度增加的总步数。作者还探索了其他 pacing 函数选项,包括先前工作中的离散两阶段函数、带有额外超参数的分段根函数,以及基于训练损失和验证损失的自适应函数。然而,这些替代方案要么导致训练不稳定,要么性能与线性函数相当且未带来显著优势。

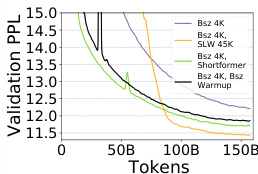
如图所示:图 3 展示了在不同 pacing 函数持续时间 T 下 GPT-2 117M 预训练期间的验证困惑度。子图 (a) 显示训练初期的步级验证困惑度,子图 (b) 展示训练末期的 token 级验证困惑度。结果表明,在合理范围内,模型性能对持续时间 T 的敏感度较低,这意味着选择 T 的计算成本相对较低。
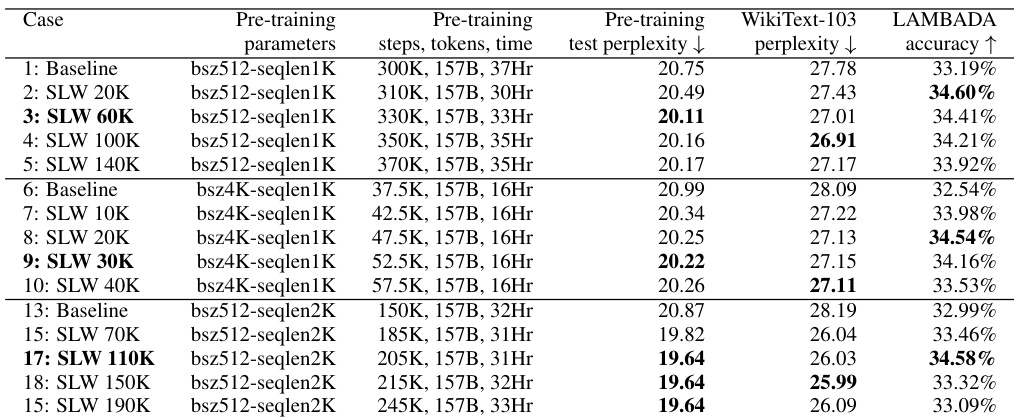
为减少大规模网格搜索的需求,作者提出了一种低成本调优策略。该策略从较小的起始序列长度 seqlens=8 开始,并将持续时间 T 设置为学习率预热步数的若干倍数。逐步增加起始长度,直至训练初期验证困惑度不再出现显著波动。随后执行二分搜索,以找到在初始训练阶段可避免显著验证困惑度波动的最大 T 值。该启发式方法仅依赖验证集,无需下游任务评估。该方法在 GPT-2 1.5B 和 GPT-3 125M 模型上得到验证,在 GPT-2 117M 案例中实现了与完整网格搜索相似的稳定性与效率收益。
实验
实验在变化的批量大小、学习率和序列长度下评估 GPT-2 与 GPT-3 模型,以验证训练稳定性与计算效率之间的内在权衡。分析表明,激进的超参数可加速收敛,但会由累积的梯度方差引发严重不稳定性,尤其在训练早期引入长序列时更为明显。提出的序列长度预热策略有效抑制了这些方差异常值,使得在显著更高的学习率下仍能进行稳定优化。因此,该方法通过提供更快速、资源利用更高效的预训练,同时在保持或提升下游任务精度的前提下,成功化解了稳定性与效率的困境。
作者分析了大语言模型预训练中训练稳定性与效率的权衡,重点探讨增大批量大小和学习率如何提升效率却导致训练不稳定性,尤其是在更大规模的模型中。他们提出了一种方法,通过逐步增加序列长度,使得在更高超参数设置下也能实现稳定训练,从而降低梯度方差并加速收敛,且不牺牲性能。结果表明,该方法在显著减少训练时间和数据需求的同时,维持或提升了精度。增大批量大小和学习率虽能提升训练效率,但会导致基线模型出现不稳定性及性能下降。所提方法通过逐步增加序列长度降低梯度方差,从而在更高超参数设置下实现稳定训练。与基线方法相比,该方法使用更少的数据和时间实现了更高的精度和更快的训练速度。
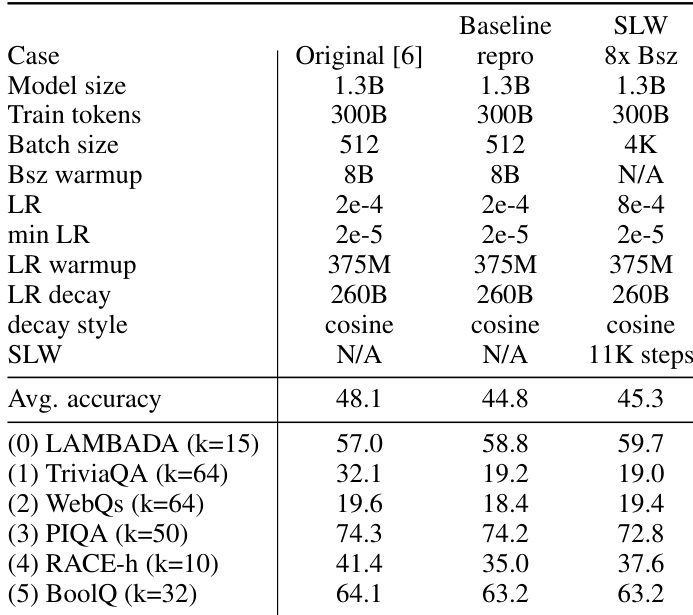
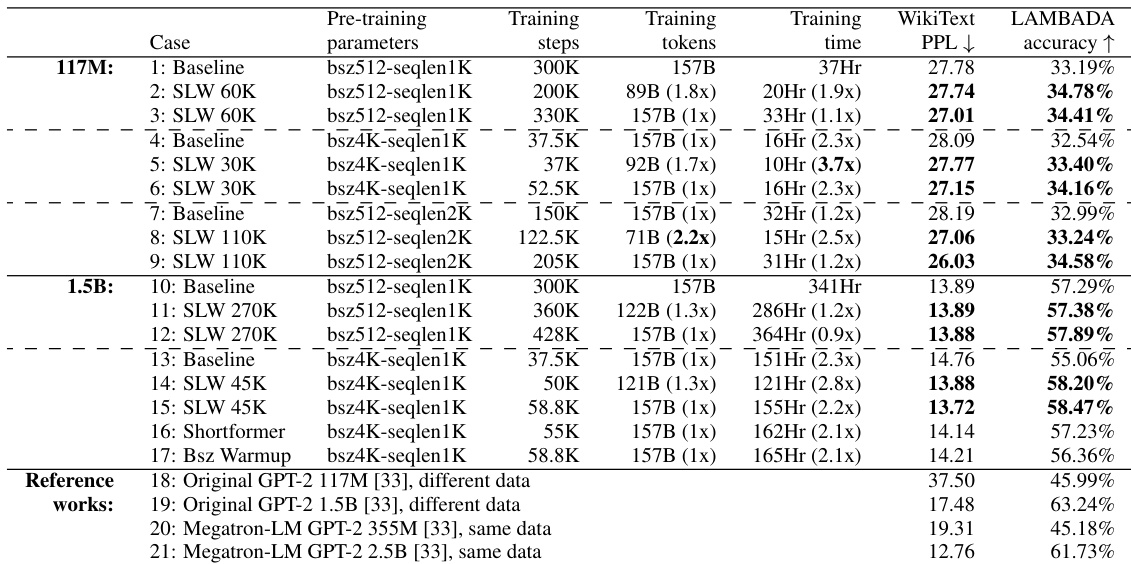
作者对比了 GPT-2 模型在不同超参数下的多种训练配置,包括基线方法与所提出的序列长度预热方案。结果显示,与基线配置相比,该方法在 WikiText-103 和 LAMBADA 数据集上取得了更低的预训练困惑度和更高的零样本精度,同时所需的训练步数与时间也更少。所提出的序列长度预热方法相比基线方法实现了更低的预训练困惑度与更高的零样本精度。该方法在维持或提升模型性能的同时缩短了训练时间。该方法支持在更大批量大小和学习率下进行稳定训练,提升了训练效率。
作者分析了 GPT-2 预训练在不同模型规模、批量大小和学习率下的训练不稳定性,采用损失比率来衡量不稳定性程度。结果表明,较大的批量大小和学习率会加剧不稳定性,导致损失突增更为频繁和严重,进而对收敛和下游性能产生负面影响。分析还揭示了训练不稳定性与梯度方差异常值之间的强相关性,尤其体现在 Adam 方差状态的最大元素上。较大的批量大小和学习率会增加训练不稳定性,导致损失突增更频繁且幅度更大。训练不稳定性与梯度方差异常值高度相关,尤其是 Adam 方差状态的最大元素。所提方法支持在更大批量大小和学习率下进行稳定训练,在不牺牲收敛性或性能的前提下提升了效率。

作者分析了 GPT-2 预训练中训练稳定性与效率的权衡,表明较大的批量大小和学习率虽能提升效率,但会加剧训练不稳定性(通过损失突增和梯度方差来衡量)。他们提出了一种方法,使得在更高效率设置下也能实现稳定训练,相比基线方法取得了更好的收敛效果与下游性能。结果证明,该方法在减少训练时间并加速收敛的同时,维持或提升了精度。较大的批量大小和学习率提升了训练效率,但会增加不稳定性并削弱下游性能。所提方法在更高效率设置下实现稳定训练,改善了收敛性并保持了精度。与基线方法相比,该方法缩短了训练时间,并在零样本和少样本任务上提升了性能。
作者分析了不同配置下 GPT-2 模型的训练稳定性与效率,观察到较大的批量大小和学习率会导致训练损失突增更频繁且更易出现不稳定性,在更大规模的模型中尤为明显。他们发现训练不稳定性与梯度方差异常值存在强相关性,并提出一种方法,使得在更大批量大小和学习率下也能实现稳定训练,从而同时提升效率与收敛性。结果表明,该方法成功化解了稳定性与效率的权衡问题,允许在不牺牲模型性能的前提下进行更快训练。较大的批量大小和学习率会导致训练不稳定性增加,表现为损失突增更频繁且最大损失比率更高,在更大模型中尤为突出。训练不稳定性与梯度方差异常值高度相关,尤其是 Adam 方差状态的最大元素。所提方法支持在更大批量大小和学习率下进行稳定训练,在维持或提升模型性能的同时改善了训练效率与收敛性。
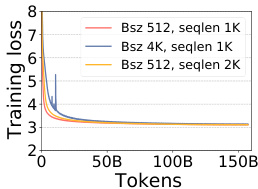
实验评估了 GPT-2 预训练配置,以验证批量大小和学习率调整如何影响计算效率与优化稳定性之间的权衡。后续分析证实,激进的超参数扩展始终会通过损失突增和梯度方差异常值引发训练不稳定性,最终阻碍收敛与下游任务性能。随后验证了所提出的序列长度预热方法作为一种有效解决方案,通过逐步扩展上下文来抑制梯度方差并稳定优化过程。最终,研究结果表明该方法成功调和了效率与稳定性,在多样化基准测试中维持或提升了模型精度,同时实现了更快收敛与更低资源需求。