Command Palette
Search for a command to run...
基于质量估计与纠正反馈的切罗基语-英语机器翻译演示系统
基于质量估计与纠正反馈的切罗基语-英语机器翻译演示系统
Shiyue Zhang Benjamin Frey Mohit Bansal
一键部署通义千问 Qwen2-7B-Instruct-GPTQ-Int4 Demo
摘要
我们介绍了ChrEnTranslate,这是一个用于英语与濒危语言切罗基语之间翻译的在线机器翻译演示系统。该系统支持统计和神经翻译模型,并提供质量估计以告知用户可靠性;设有分别面向专家和普通用户的两种用户反馈界面;提供示例输入以收集人工翻译数据,从而构建单语数据;支持词对齐可视化;并集成切罗基语-英语词典中的相关术语。定量评估表明,我们的基础翻译模型实现了最先进的翻译性能,且我们的质量估计与BLEU分数及人类判断均具有良好的相关性。通过对216条专家反馈的分析,我们发现神经机器翻译(NMT)优于统计机器翻译(SMT),因为NMT的复制现象更少;总体而言,当前模型能够翻译源句片段,但会犯重大错误。当我们将这216条经专家校正的平行文本重新加入训练集并重新训练模型时,观察到相等或略优的性能,这表明了人在回路学习(human-in-the-loop learning)的潜力。
一句话总结
ChrEnTranslate 是一个在线英-切罗基语机器翻译系统,支持统计模型与神经模型,并集成质量估计功能,以及独立面向专家与普通用户的反馈接口。定量评估表明,该系统达到了最先进的翻译性能,其质量估计结果与 BLEU 分数及人类判断高度相关。此外,通过在 216 条专家修正译文上进行重训练,系统展现出人在回路(human-in-the-loop)的学习潜力,并取得了持平或更优的效果。
核心贡献
- ChrEnTranslate 是一个在线英-切罗基语机器翻译演示平台,集成了统计与神经模型、质量估计功能、词对齐可视化界面,以及面向专家与普通用户的专用反馈接口。
- 该系统实现了一条人在回路(human-in-the-loop)流水线,通过收集专家修正结果来迭代重训练翻译模型。实验证明,将 216 条人工验证的平行文本纳入训练数据,可获得持平或更优的翻译准确率。
- 定量评估证实,核心翻译模型达到了最先进的性能水平,且质量估计模块与 BLEU 分数及人类判断之间呈现出中等至强相关性。
引言
机器翻译已发展成为全球通信的标准工具,但往往忽视切罗基语等低资源语言,而联合国教科文组织已将其列为濒危语言。这一技术缺口直接威胁到语言复兴工作,因为依赖长者主导的教学与沉浸式项目的社区仍无法获得数字翻译辅助工具。以往的翻译模型受限于极度匮乏的平行语料,且通常依赖昂贵的人工质量评级,这对于土著语言而言难以实际收集。为弥合这一差距,作者开发了 ChrEnTranslate,这是首个集成统计与神经机器翻译核心架构并内置质量估计功能的在线切罗基语-英语翻译平台。通过部署基于 BLEU 分数与不确定性驱动的质量指标,该系统会在输出结果低于可靠阈值时主动向用户发出警告。作者还设计了一套人在回路反馈框架,用于收集专家修正结果与用户评分,从而实现模型的持续优化,在保护语言遗产的同时,为其他低资源语言对提供可扩展的模板。
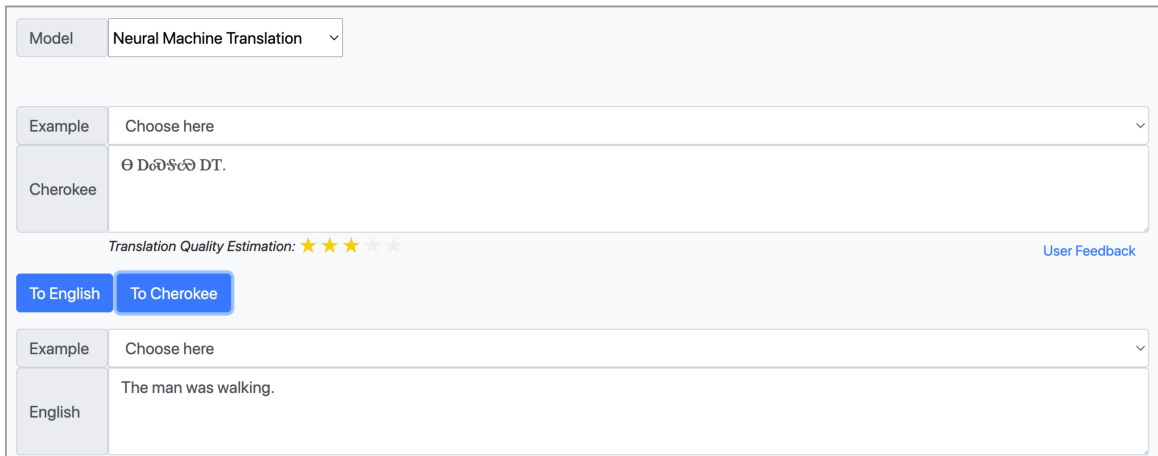
数据集
- 数据集构成与来源: 作者使用了 17,000 条平行文本,最初来源于 WMT 竞赛。该数据通常将机器翻译输出与人工质量评级配对。
- 子集详情: 语料库被划分为包含 16,000 个示例的训练集和包含 1,000 个示例的评估集。
- 数据使用与处理: 为训练有监督的质量估计模型,作者使用 BLEU 分数作为质量代理指标,以替换缺失的人工评级。这些分数通过 17 折交叉验证流程生成:在 16 折数据上训练翻译模型,为保留的 1 折生成译文与 BLEU 指标,循环此过程直至所有 17,000 个示例均获得评分,随后再执行最终的 16,000 至 1,000 划分。
- 特征提取与元数据构建: 作者提取了针对在线推理优化的轻量级 SMT 特定特征,以防止延迟激增。每个示例包含输出长度,以及失真度、语言模型、词汇重排、短语惩罚、翻译模型和词惩罚的原始评分组件,同时包含这些指标的长度归一化变体。为维持实时性能,系统明确排除了计算成本高昂的特征(如 dropout 估计器)。
方法
作者采用了一个双模型框架,同时支持统计机器翻译(SMT)与神经机器翻译(NMT)方法,使用户能够根据翻译场景选择最合适的模型。如图 1 所示,该系统整合了这两种范式,其中 SMT 在切罗基语与英语的域外翻译中表现尤为出色。SMT 实现基于使用 Moses 的短语翻译模型,其中 3-gram 语言模型通过 KenLM 训练,词对齐通过 GIZA++ 学习。模型权重在开发集上通过 MERT 进行优化。
针对域内翻译,系统采用 NMT,其在流畅度与性能方面展现出显著优势。作者采用了 Luong 等人(2015)提出的全局注意力模型,并指出在实验环境中 Transformer 架构的表现实际上较差。系统未采用多语言技术,因为此类技术仅在基于多语言圣经文本训练时才能显著提升性能,并可能引入偏向圣经文体语言的偏差。相反,NMT 模型仅使用提供的切罗基语-英语平行语料进行训练。为提升鲁棒性,最终的 NMT 系统采用了三个模型的集成方案。

质量估计(QE)功能已集成至系统中,用于评估翻译输出质量。针对 NMT,作者考虑了多项特征:输出长度、对数概率及长度归一化对数概率、概率及长度归一化概率,以及注意力熵,其定义如下:
−Lt1i=1∑Ltj=1∑Lsαijlogαij其中 Ls 为源文本长度,αij 表示目标 token i 与源 token j 之间的注意力权重。这些特征被输入至 XGBoost 回归器以预测 BLEU 分数,随后通过将预测的 BLEU 分数(0–100)除以 20,重新缩放至 0–5 星评分标准。这为系统内部提供了一个可视化的质量指示器。
研究还探索了无监督 QE 方法,这源于有监督方法需要大量人工评级数据的局限性。作者将不确定性估计作为质量的代理指标进行探究。尽管输出概率常被用作置信度衡量标准,但其通常在语言生成任务中校准效果不佳。取而代之的是,作者采用基于集成的不确定性估计方法,利用模型在多次前向传播中的输出概率来量化不确定性。该方法被证实简单且有效,并按句子长度进行归一化处理。归一化后的概率(0–1)通过乘以 5 重新缩放至 0–5 刻度。

为评估质量估计系统,作者收集了 200 句翻译文本的人工评级,其中切罗基语-英语 SMT、英语-切罗基语 SMT、切罗基语-英语 NMT 和英语-切罗基语 NMT 各 50 句。这些评级由 Benjamin Frey 教授提供,采用与 FLoRes 类似的直接评估设置,分数范围为 0 至 100。
实验
评估流程使用预留的开发集来检验统计与神经翻译模型及质量估计工具,并通过专家反馈与人类判断的相关性验证其实际可靠性。定性分析表明,尽管神经模型因减少直接复制源文本而更受青睐,但两个系统主要翻译孤立片段,且常因数据集偏差产生重大错误或古旧表达。尽管如此,将专家修正后的译文重新整合至训练流水线中,仍能获得持平或更优的性能,这证实了人在回路学习在推进濒危语言翻译方面的可行性。
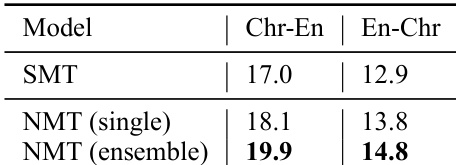
作者采用统计与神经方法对切罗基语-英语翻译模型进行评估,结果显示神经模型取得了更高的性能,且与人类判断的吻合度更好。该研究包含针对翻译质量的专家反馈,并考察了将修正译文纳入训练数据的影响。结果表明,神经模型因较少复制源文本且能改善片段翻译而更受推荐,尽管仍存在显著错误。在翻译质量及与人类判断的一致性方面,神经模型均优于统计模型。专家反馈指出,模型通常能正确翻译片段,但会犯重大错误,尤其在使用古旧英语词汇时。将专家修正译文纳入训练会导致持平或略有提升的性能。
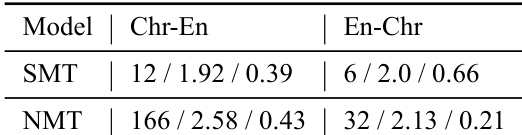
作者对比了切罗基语-英语翻译的统计与神经模型,并在开发集上评估其性能。结果表明,神经模型的翻译质量高于统计模型,且集成 NMT 模型的表现优于单一模型。通过专家反馈进一步分析翻译质量,发现模型通常能正确翻译片段但会犯重大错误,而纳入专家修正结果可提升性能。神经翻译模型在翻译质量上优于统计模型。集成神经模型的表现高于单一模型。专家反馈指出,模型通常能正确翻译片段但会犯重大错误。
作者展示了一个包含统计与神经模型的切罗基语-英语翻译系统,并对其质量估计与翻译性能进行评估。结果表明,有监督质量估计在 SMT 上表现更佳,而无监督方法在 NMT 上与人工评级的相关性更高,且 NMT 的 BLEU 分数与人工评级均优于 SMT。有监督质量估计在 SMT 上表现更佳,而无监督方法在 NMT 上与人工评级表现出更强的相关性。与 SMT 模型相比,NMT 模型取得了更高的 BLEU 分数与人工评级。无监督质量估计方法在 NMT 上与人类判断呈现中等至强相关性,但在 SMT 上相关性较弱。
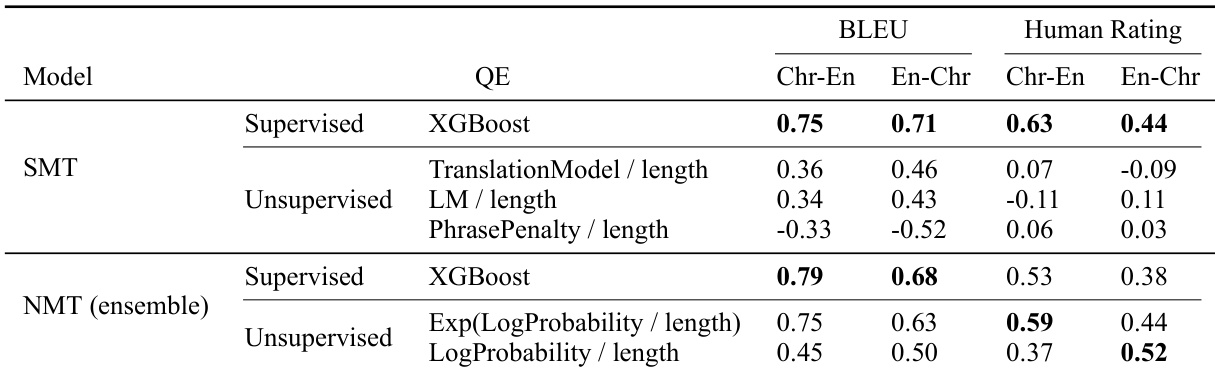
本次评估对比了切罗基语-英语的统计与神经翻译系统,并通过专家反馈与质量估计分析进行验证。定性结果表明,与统计方法相比,神经方法 consistently 提供更优的翻译质量及更强的人类判断吻合度,且集成配置带来了额外增益。尽管模型能有效处理碎片化短语,但常在复杂或古旧术语上遇到困难,而将专家修正结果整合至训练数据中可维持或略微提升整体性能。此外,质量估计策略因架构而异,有监督方法被证明对统计模型更为有效,而无监督技术则与神经系统的人工评级表现出更紧密的相关性。