Command Palette
Search for a command to run...
一键部署数据降维教程
摘要
一句话总结
本教程与综述将谱降维方法统一为具有不同核函数的核主成分分析,概述了基于半定规划的转导核学习方法,并详细阐述了最大方差展开(Maximum Variance Unfolding)及其有监督变体、基于特征函数与核映射的样本外扩展,以及面向大数据的地标法适配。
核心贡献
- 谱降维方法被统一为具有不同核函数的核主成分分析,可通过特征函数学习与距离矩阵表示进行解释。
- 本教程建立了必要的半定规划背景知识,并详细阐述了用于转导任务的基于SDP的核学习方法,以及最大方差展开与半定嵌入框架。
- 详细阐述了利用最近邻图、逐类展开、Fisher准则及着色公式的有监督MVU变体,以及基于特征函数与核映射的样本外扩展,同时引入了包括动作保持嵌入、松弛MVU以及面向大数据的地标MVU在内的其他适配方法。
引言
谱降维技术对于从复杂的高维数据集中提取低维几何结构至关重要,但历史上它们一直作为具有固定核公式的独立算法发展。这种碎片化限制了方法的适应性,使得自动识别用于展开数据流形的最优核变得困难。作者通过证明所有谱方法均可重新表述为具有数据集特定核函数的核主成分分析,利用了这一统一的理论视角。基于此见解,他们引入了一个综合框架,应用半定规划来学习最优核,使最大方差展开能够沿流形的内在维度进行拉伸。本文系统性地综述了这一统一方法,详细阐述了有监督扩展、样本外泛化技术以及可扩展变体,最终为实践者提供了将流形学习适配到多样化现实应用的清晰路线图。
数据集
• 数据集构成与来源:提供的文本中未描述任何数据集构成或来源。摘录仅包含作者单位与出版元数据。 • 各子集的关键细节:未提及任何子集划分、规模、来源或过滤标准。 • 论文的数据使用方式:未明确训练集划分、混合比例或数据处理流程。 • 裁剪策略、元数据构建或其他处理细节:未概述任何裁剪方法、元数据生成步骤或其他处理技术。
方法
该方法的核心方法论围绕学习一个最优核矩阵展开,该矩阵能够实现对数据流形的最大方差展开,此过程通过半定规划(SDP)进行形式化。这一框架被称为最大方差展开(MVU)或半定嵌入(SDE),通过将各种谱降维技术视为具有不同核定义的核主成分分析(PCA)实例,实现了它们的统一。主要目标是找到一个核,在保持数据局部几何结构的同时最大化其嵌入的方差。
该框架从一个数据集 X:={xi∈Rd}i=1n 开始,旨在寻找一个低维嵌入 Y:={yi∈Rp}i=1n。与直接在输入空间操作的常规PCA不同,MVU在由核函数 k(⋅,⋅) 定义的再生核希尔伯特空间(RKHS)中进行此嵌入。嵌入定义为 yi=ϕ(xi),其中 ϕ(⋅) 为映射函数。关键见解在于,该嵌入完全由核矩阵 K∈Rn×n 决定,其中 Kij=ϕ(xi)⊤ϕ(xj),该矩阵是对称且半正定(PSD)的。
优化问题旨在寻找最优的此类核矩阵。这通过最大化嵌入的方差来实现,等价于最大化核矩阵的迹 tr(K)。然而,该最大化过程受到定义流形结构的关键约束限制。第一个约束强制局部等距,确保输入空间中相邻点之间的相对距离和角度在嵌入空间中得以保留。这形式化为 τij(Kii+Kjj−2Kij)=τij(Gii+Gjj−2Gij),其中 Gij=∥xi−xj∥22 是输入空间中的平方欧氏距离,τij 为指示函数,当 xj 是 xi 的邻居时(通常由 k-近邻图确定)取值为1,否则为0。
第二个约束确保嵌入的均值为零,从而消除平移自由度。这通过对核矩阵进行双重中心化来实现,等价于约束条件 ∑i=1n∑j=1nKij=0。最后也是最关键的约束是核矩阵必须为半正定,即 K⪰0,这是有效Mercer核的基本要求。因此,完整的SDP优化问题是在满足上述三个约束的条件下最大化 tr(K)。 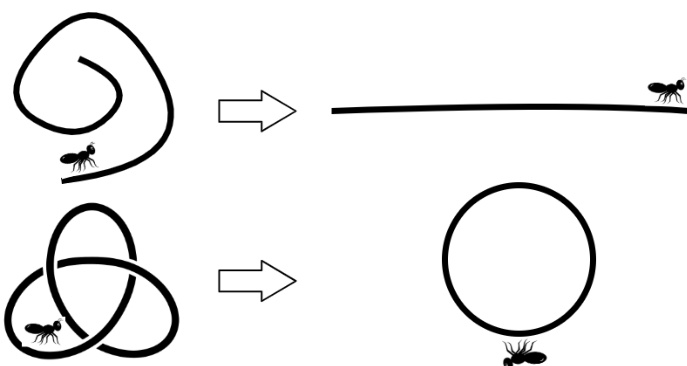
通过SDP学习得到最优核矩阵 K 后,最终嵌入由其特征向量与特征值计算得出。点 x 的嵌入是将其投影到 K 的特征向量上得到的。嵌入的第 k 维 yk(x) 计算为 yk(x)=δkvki,其中 vk 为第 k 个特征向量,δk 为 K 的对应特征值。最终嵌入的维度数 p 通过选择对应最大特征值的前 p 个特征向量来确定,通常借助碎石图(scree plot)来寻找相邻特征值之间的显著间隔。