Command Palette
Search for a command to run...
在多项选择任务上微调模型
摘要
一句话总结
作者提出了一种少样本学习策略,该策略通过高效的进化搜索识别出特定的网络层及其对应的不同学习率,并选择性地微调或冻结这些层,从而缓解知识迁移偏差。该方法在 CUB 和 mini-ImageNet 数据集上,于元学习、非元学习框架及传统预训练范式下均取得了最先进的性能。
核心贡献
- 本文提出了一种部分迁移框架,该框架选择性地冻结或微调预训练骨干网络中的特定层,并为每层分配独立的学习率,以精确控制知识保留并缓解来自基础类别的偏差。
- 一种高效的进化搜索算法实现了该自适应过程的自动化,它直接基于验证准确率同时确定最优的层配置及其对应的学习率,无需依赖代理模型。
- 在 CUB200-2011 和 mini-ImageNet 基准上的大量实验表明,该方法在元学习和非元学习架构上均带来一致的性能提升,并在传统预训练与微调范式中实现了稳定的准确率增益。
引言
少样本学习旨在解决仅使用极少量标注样本训练分类器的挑战,这一能力对于医疗诊断和稀有物种追踪等数据稀缺型应用至关重要。传统的迁移学习流程通常在大容量基础数据集上预训练模型,随后要么冻结整个骨干网络,要么针对新类别微调所有参数。这种僵化的方法面临困境,因为基础类别与新类别之间不存在重叠,导致模型要么保留带有偏差的先验知识,要么在极小的支持集上发生过拟合。为解决此问题,作者采用了一种部分迁移框架,通过选择性地冻结或微调特定网络层来应对挑战。研究引入了一种高效的进化搜索方法,自动识别最优层配置并为每层分配独立的学习率,从而有效平衡先验知识保留与新类别适应。该策略可与元学习和非元基线方法无缝集成,在标准少样本基准测试中持续带来性能提升。
数据集
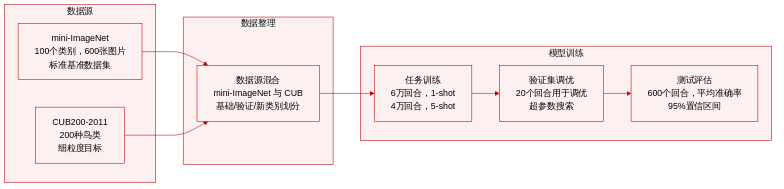
- 数据集构成与来源: 作者使用两个成熟的基准数据集评估该方法。mini-ImageNet 来源于 ImageNet,包含 100 个类别,每类 600 张图像;CUB200-2011 是一个细粒度鸟类数据集,涵盖 200 个物种。
- 子集详情与划分: 作者将 mini-ImageNet 划分为 64 个基础类别、16 个验证类别和 20 个新类别。CUB200-2011 被划分为 100 个基础类别、50 个验证类别和 50 个新类别。该结构支持通用分类、细粒度识别及跨域适应实验。
- 数据使用与训练配置: 针对元学习,作者通过每任务采样五个类别来构建 episode(训练回合)。每个 episode 为支持集提供每类 k 张图像,为查询集提供每类 15 张图像。模型在基础数据集上训练,单样本任务共 60,000 个 episode,五样本任务共 40,000 个 episode。使用 20 个验证 episode 进行超参数搜索,并在 600 个新类别 episode 上评估最终性能。非元学习基线模型以 16 的批次大小训练特征提取器 400 个 epoch。
- 处理与增强策略: 处理流程采用标准数据增强方法,包括随机裁剪、水平翻转和颜色抖动。作者在网络于支持集上微调 100 次迭代后,在查询集上进行评估。所有评估运行均报告平均准确率及 95% 置信区间。
方法
作者提出了一种名为部分迁移(Partial Transfer, P-Transfer)的少样本分类框架,该框架能够在微调预训练骨干模型期间搜索最优迁移策略。整体流程包含三个独立阶段:基础类别预训练、针对最优微调配置的进化搜索,以及利用发现策略对新类别进行部分迁移。在第一阶段,特征提取器在基础类别数据集上从零开始训练,采用标准交叉熵损失函数,如图表中的训练阶段所示。该预训练模型为后续适应新类别奠定基础。第二阶段采用进化算法探索可能的微调配置空间,骨干网络的不同层可被冻结或使用不同学习率进行更新。进化过程作用于候选策略种群,在验证集上评估各策略性能,随后应用选择、交叉和变异操作,在连续代际中生成更优配置。 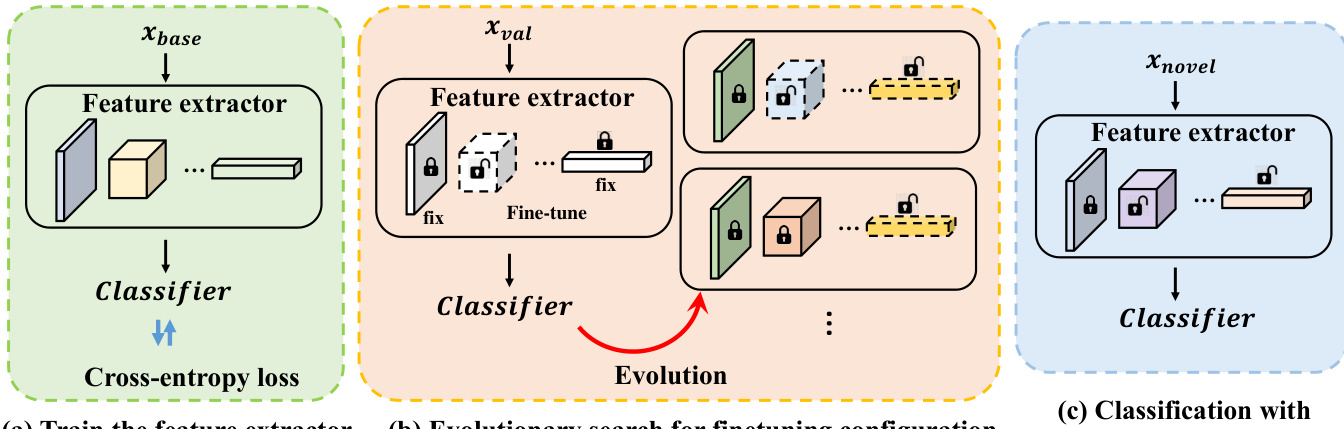
微调策略的搜索空间定义在层级别,涵盖冻结某一层(将其学习率设为零)的决策,以及为待微调层选择具体学习率值的过程。该空间被形式化为 mK,其中 m 表示离散学习率选项的数量(包含零),K 为网络总层数。例如,采用包含四个元素的候选学习率集合 {0,0.01,0.1,1.0} 及 Conv6 架构时,搜索空间包含 46 种潜在配置。进化算法高效遍历该空间以识别最优策略,随后在最终阶段应用该策略。在此阶段,预训练模型使用所学配置在类别支持集上进行部分微调,所得模型在查询集上进行评估。如图表微调阶段所示,这种部分迁移方法与冻结整个骨干网络或统一微调所有层的传统方法形成对比。 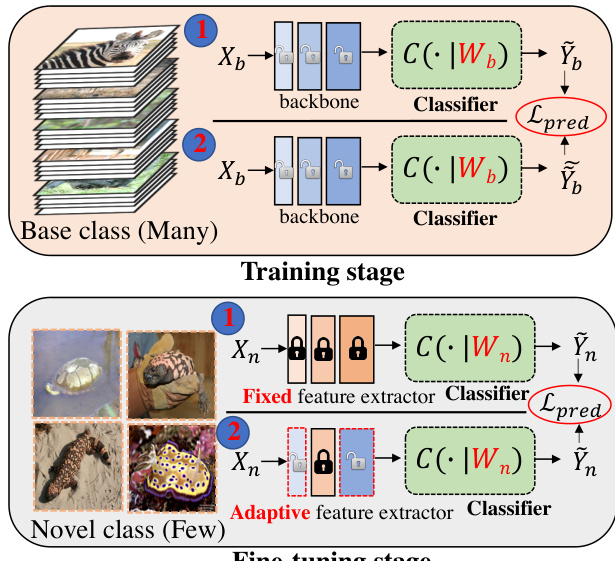
所提框架设计为兼容基于非元学习和元学习的少样本分类方法。针对非元方法(如 baseline++),进化搜索作用于特征提取器 fθ(x) 以寻找微调的最优学习率配置,同时分类器保持不变。这实现了整个模型的端到端优化。针对元学习方法(如 ProtoNet),搜索过程被整合至元训练阶段,在此阶段学习微调策略以优化模型从少量支持集适应新任务的能力。该框架具有足够的通用性,可融入各类分类流程,其与 baseline++ 及元学习方法的集成细节已在图表中详细展示。 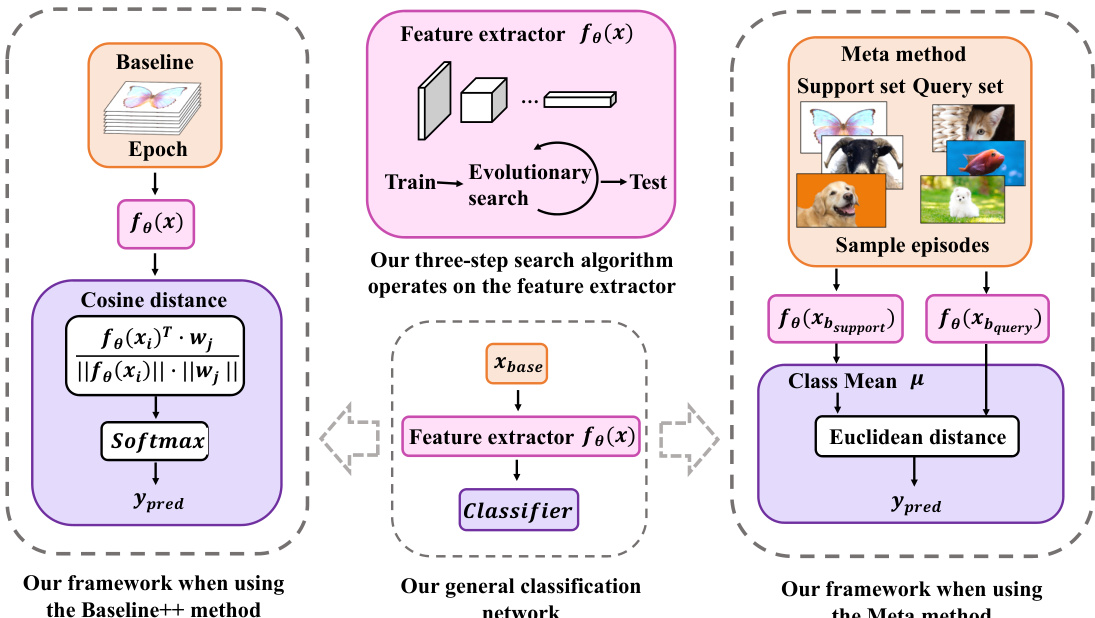
实验
实验在多种架构下将所提出的进化搜索微调策略与固定及人工设计的基线方法进行对比验证,同时评估了跨域少样本设置下的归一化技术与迁移策略。对所学策略的可视化分析表明,更深的网络与更大的域间差异均一致需要微调更多层,证实了灵活自适应能力随模型复杂度和分布偏移程度而扩展。此外,消融研究证实,部分迁移通过过滤无关的基础类别信息,性能优于完整的权重继承,最终证明无需辅助训练技术,搜索驱动的微调策略始终能超越当前最先进方法。
作者对比了少样本学习中的不同微调策略,评估了固定、人工设计及进化搜索部分迁移方法的有效性。结果表明,搜索方法在各类模型和样本设置下均持续优于固定与人工策略,在 1-shot 和 5-shot 场景中均观察到性能提升。搜索型微调策略在所有配置下的准确率均高于固定和人工设计方法。性能提升在不同模型和少样本设置中保持一致,体现了良好的鲁棒性。结果证实,在少样本学习中,通过进化搜索实现的部分迁移比完整或人工选择的微调更为有效。
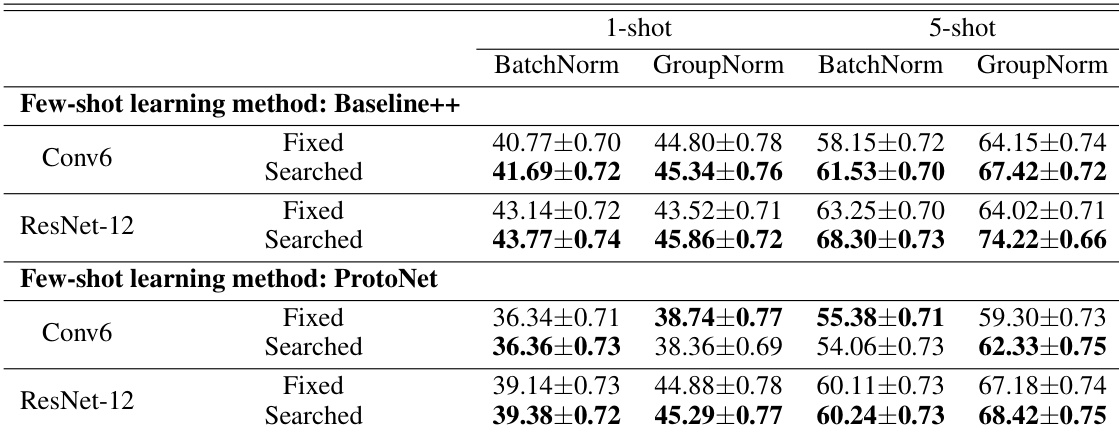
作者对比了少样本学习中的不同微调策略,涵盖固定、人工设计及进化搜索方法。结果表明,搜索方法在不同数据集和样本设置下均优于固定与人工策略,准确率提升保持一致。研究指出,相较于完整或手工设计的微调,基于进化搜索选择性地微调层能够促进更好的知识迁移。该方法在无需额外训练技术的情况下展现出稳健的性能,凸显了部分迁移的有效性。搜索型微调策略在两个数据集及各类样本设置下的准确率均高于固定和人工方法。进化方法持续优于基线策略,表明其在少样本学习中实现了更优的知识迁移。结果表明,相较于完整或固定微调,部分微调能够提升性能,尤其在跨域场景中表现更为显著。
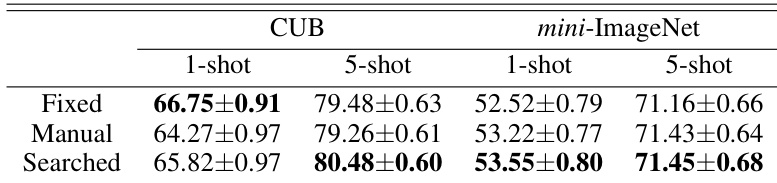
作者将提出的部分迁移方法与采用完整迁移的基线方法进行对比,结果显示部分迁移方法取得了更高的准确率。结果表明,从预训练模型中选择性迁移知识能够在少样本学习场景中带来更好的性能。部分迁移方法在准确率上优于基线方法。相较于完整迁移,选择性知识转移提升了整体性能。该方法在无需额外训练技术的情况下实现了更高的准确率。

作者通过对比 Conv6、ResNet-12 和 ResNet-K 等不同架构,分析了网络复杂度对少样本学习的影响。研究观察到,更深的网络通常需要微调更多层,且网络复杂度会影响部分迁移方法适应新类别的有效性。更深网络需要微调更多层才能实现有效的少样本学习。网络复杂度影响部分迁移方法适应新类别的性能。网络架构的选择决定了少样本场景下需要微调的层数。

作者对比了所提出的微调策略进化搜索方法与固定及人工设计方法在少样本学习任务中的表现。结果表明,搜索方法在不同模型和数据集上均持续取得高于固定与人工策略的准确率,在 1-shot 和 5-shot 设置下均观察到性能提升。研究指出,针对特定层进行自适应微调,而非完整或固定层调整,能够带来更优性能,尤其在域差异显著时效果更佳。所提出的进化搜索方法在多种少样本学习方法和数据集上均优于固定与人工微调策略。搜索型微调策略能够适配任务复杂度,更深网络与更大域差异需要微调更多层。该方法在不依赖 DropBlock 或标签平滑等额外训练技术的情况下,持续超越基线性能。
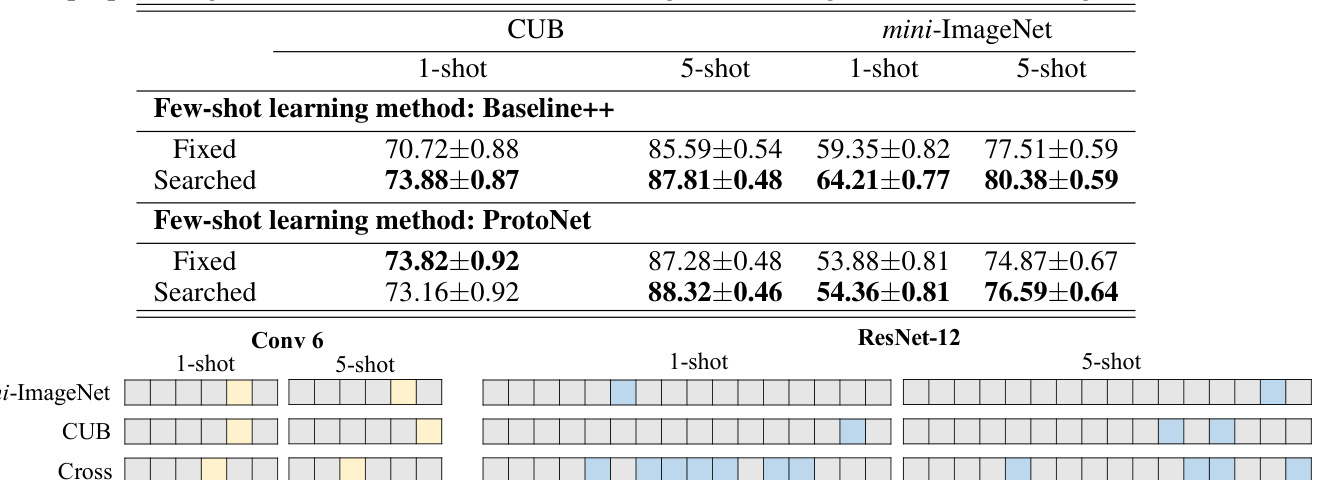
实验通过对比固定、人工设计及进化搜索部分迁移方法,在多种模型、数据集和样本设置下评估了少样本学习中的各类微调策略。结果表明,通过进化搜索自适应选择层持续获得更高准确率,优于完整或手工设计的方法,验证了定向知识迁移的有效性。进一步分析显示,网络架构对自适应过程影响显著,更深模型需要更广泛的层微调以应对复杂任务和域偏移。总体而言,研究证实进化引导的部分迁移为传统微调提供了一种稳健且高效的替代方案,且无需依赖辅助训练技术。