Command Palette
Search for a command to run...
使用 TensorFlow 进行食品分类
摘要
一句话总结
通过对21种食品使用同步的本体感觉、音频和视觉传感器进行交互式探索,作者开发了采用三元组损失公式训练的视觉嵌入网络,成功提升了材质与形状分类性能,以支持具备材质感知能力的机器人食品操作规划。
核心贡献
- 通过同步的机器人交互收集了包含21种独特食品的真实世界数据集,捕获视觉、本体感觉和音频信号,以解决基于仿真的食品属性模型在真实世界中迁移性有限的问题。
- 采用三元组损失公式训练的视觉嵌入网络在训练期间融合多模态感官数据以编码材质属性相似性,而在推理阶段仅需顶视图像。
- 利用这些学习到的嵌入向量的下游回归器和分类器在多种材质与形状分类任务中一致优于仅视觉和仅音频的基线模型,证明了其在具备材质感知能力的机器人操作规划中的有效性。
引言
作者针对机器人食品操作面临的挑战展开研究,其中准确建模食品多样且可形变的材质属性对于实现有效的物理交互至关重要。以往方法通常依赖计算成本高昂的仿真,这些仿真无法捕捉真实世界的形变、专用硬件或耗时的标注,而现有的仅视觉嵌入方法则忽略了宝贵的多模态线索。为克服这些局限,作者利用机器人平台自主收集了一个涵盖视觉、音频、本体感觉和力数据的多模态同步数据集,覆盖二十一种食品。随后,作者采用三元组损失公式训练视觉嵌入网络,在训练过程中整合这些交互式传感器信号。所得表征成功编码了复杂的材质属性,使下游分类器和回归器能够超越单模态基线,并为规划具备材质感知能力的机器人操作技能奠定基础。
数据集

-
数据集构成与来源: 作者使用两套 Franka Emika Panda 机器人装置收集多模态传感器数据,包括 RGB-D 图像、接触音频、力测量值和本体感觉反馈。其中一套装置执行自主食品切割,另一套负责切割后的操作。传感器阵列包含顶视 Azure Kinect 摄像头、侧视 Intel Realsense D435 单元、定制腕部安装的 FingerVision 鱼眼摄像头,以及与 ROS 同步的压电接触麦克风。
-
子集详情: 该数据集涵盖21种不同的食品类型,每种被处理成10个标准化切片,厚度、切割角度和方向各不相同。切割子集使用源自人体运动学演示的动态运动基元(Dynamic Movement Primitives)记录切片过程。交互子集包含每种切片类型的5次试验,机器人在此执行推、抓和放动作以记录材质形变。历史子集包含在独立环境中手动切割收集的切片。作者指出,当食品几何形状阻碍执行时,会排除某些角度的切割。
-
数据处理与使用: 作者按食品类型、切片类别和试验编号对数据进行分层组织。未明确指定具体的训练集与测试集划分或混合比例,而是利用完整数据集训练采用三元组损失公式优化的视觉嵌入网络。这些学习到的表征无需显式标签即可捕获食品材质属性,并在多项评估任务中优于单模态基线。该数据集还支持未来在动力学建模、烹饪监控和操作策略开发中的应用。
-
元数据与标注: 团队提供了顶视和侧视图像的食材分割掩码。初始标注使用 Deep Extreme Cut 在手动标注的轮廓上生成。为扩大覆盖范围,作者利用手动标注对 ADE20K 上预训练的 PSPNet 模型进行微调,生成额外的神经网络生成掩码。音频流与机器人状态进行时间对齐,每次试验均包含动作前后的 RGB-D 快照以及夹爪宽度记录。
方法
作者利用多模态无监督学习框架训练用于食品识别任务的嵌入网络。整体方法(如框架图所示)从原始传感器数据中提取多种特征模态开始。这包括源自切割和交互动作的音频特征,使用 Librosa 将其转换为梅尔频率倒谱系数(MFCC),随后通过 PCA 降维形成 Acut 和 Aplay。本体感觉特征 P 由机器人位姿和力数据构建,具体捕获末端执行器的最终 z 轴位置 zf、下推过程中的位移 Δz 以及抓取时的最终夹爪宽度 wg。这些模态连同食品类别标签 F 和切片类型标签 S 共同作为三元组构建的度量依据。
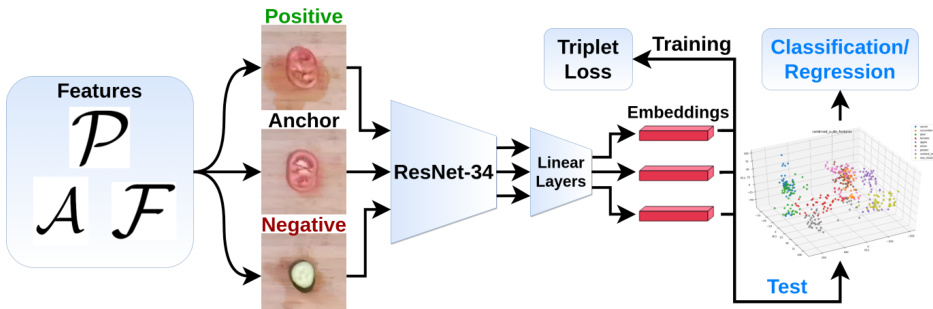
嵌入网络架构基于在 ImageNet 上预训练的 ResNet34 骨干网络构建,移除其最后的完全连接层以支持嵌入提取。该网络通过一系列带有 ReLU 激活函数的线性层处理输入特征(如顶视图像、音频和本体感觉数据),以降低维度并生成紧凑的嵌入向量。训练过程采用三元组损失,其中每个训练样本充当锚点,正样本基于 L2 距离从 PCA 特征空间中的 n 个最近邻中选择,其余样本作为负样本。三元组在训练期间动态构建,以确保网络学习将相似实例映射到嵌入空间中更近的位置。学习到的嵌入向量随后被输入到独立的多层感知机中,用于下游的监督任务(包括分类和回归)。在融合多模态时,来自各个网络的嵌入向量会在输入分类器或回归器之前进行拼接。
实验
评估使用基于交互式感官数据训练的 learned 多模态嵌入向量,对五项预测任务进行测试,并与留一法分类的仅视觉和仅音频基线进行对比以检验泛化能力。结果表明,尽管监督式视觉模型在类别识别方面表现优异,但所提出的嵌入向量无需显式标签即可成功编码相对物理与纹理属性,从而实现对未见食品类别的更强泛化能力。音频与本体感觉特征在区分材质特性方面尤为有效,而一项辅助研究证实,自主播放音频能够捕获烹饪等结构变化。总体而言,实验验证了交互式多模态学习能够有效捕获多样化的材质属性,以支持可适应的机器人食品处理。
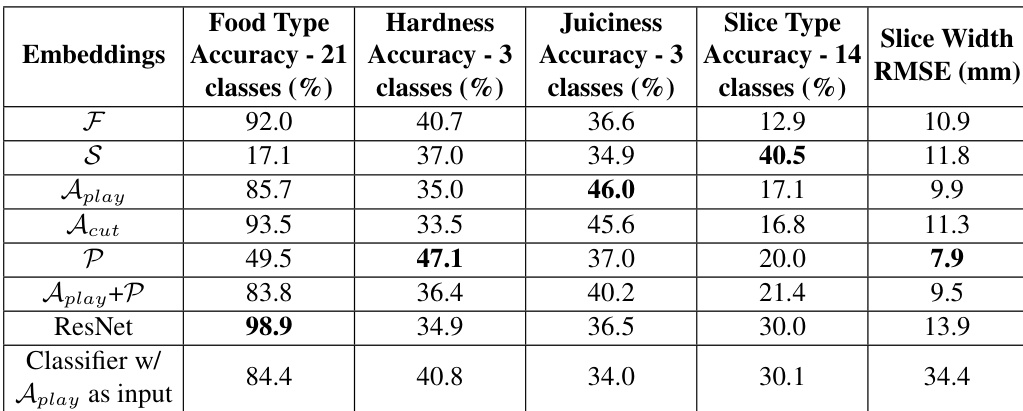
作者评估了在不同模态上训练的多个嵌入网络,用于五项任务中的食品属性预测。结果显示,特定嵌入向量在部分任务中表现优于其他模型,表明学习到的表征捕获了相关的材质属性;而仅视觉基线由于在大规模图像数据上预训练,仅在食品类型分类任务中表现良好。使用音频和本体感觉特征训练的嵌入向量在硬度和多汁度预测等任务上优于视觉基线,表明其捕获了相关的物理属性。视觉基线在食品类型分类中表现出色,但在其他任务中表现不佳,凸显了其在非分类任务中对未见数据泛化能力的局限。使用切片类型标签训练的嵌入向量在切片类型预测任务中表现优异,表明针对特定任务的训练能够提升该任务的性能。
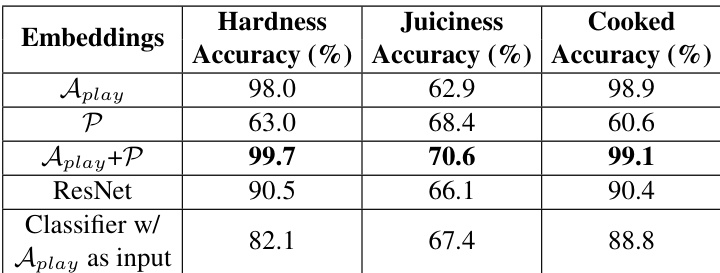
作者评估了在不同模态上训练的多种嵌入网络,以预测食品属性并分类烹饪与未烹饪状态。结果表明,结合音频和本体感觉数据的嵌入向量在硬度和多汁度任务中表现最佳,而仅音频嵌入向量对烹饪与未烹饪分类有效。不同嵌入向量在不同任务中的性能存在差异,表明各自编码了适用于特定应用的具体材质属性。结合音频和本体感觉特征的嵌入向量在硬度和多汁度预测任务中取得最高准确率。仅音频嵌入向量在烹饪与未烹饪分类中表现良好,表明其具备捕获烹饪引起的材质变化的能力。不同类型的嵌入向量在不同任务中展现出不同的性能,暗示它们编码了与特定预测目标相关的不同材质属性。
评估针对多种食品属性预测与分类任务,检验了在不同模态(包括视觉、音频、本体感觉和特定任务标签)上训练的多个嵌入网络。这些实验验证了每种表征均捕获了独特的材质特征,因为音频与本体感觉组合在估算物理特性方面表现卓越,仅音频特征能够可靠检测烹饪状态,而视觉模型主要仍有效于食品类型分类。最终,结果证明嵌入向量的有效性高度依赖于具体任务,凸显了将模态选择与特定预测目标对齐的重要性,而非依赖通用的视觉基线。