Command Palette
Search for a command to run...
Pytorch 入门-训练 FasterRCNN/
摘要
一句话总结
Pkwrap 是一个 PyTorch 软件包,通过将成本函数暴露为 autograd 操作来集成 Kaldi 的 LF-MMI 训练框架,在保留 Kaldi 并行训练能力以及与 Kaldi 生成图谱进行解码功能的同时,支持灵活的声学模型架构设计。
核心贡献
- 本文介绍了 pkwrap,一个简单的包装器,将 Kaldi 的 LF-MMI 训练框架集成到 PyTorch 中,用于声学模型开发。
- 该框架将 LF-MMI 成本函数暴露为 autograd 函数,使研究人员能够在保持 Kaldi 优化目标的同时设计自定义模型架构。
- 其他 Kaldi 功能也被移植到 PyTorch,包括适用于无多 GPU 环境的并行训练例程,以及对 Kaldi 生成图谱的解码支持。
引言
作者针对依赖 TDNN 和 TDNN-F 架构的说话人识别系统日益增长的需求,致力于构建精简且可复现的工作流。以往的方法通常面临工具链碎片化、配方(recipe)组件硬编码以及大量样板代码等问题,导致模型训练和实验迭代复杂化。为突破这些瓶颈,作者引入了一款模块化软件包,标准化了特征提取和数据管理等核心功能,同时提供可扩展的 Trainer 类以简化训练循环。其开发路线图还优先考虑自动化上下文生成以及集成的 LDA 和 PLDA 后端,最终降低稳健说话人识别研究与部署的门槛。
数据集

- 组成与来源: 作者使用了四个语音数据集进行声学模型开发:MiniLibriSpeech、Switchboard、BABEL 和 LibriSpeech(100 小时)。
- 子集详情: MiniLibriSpeech 和 Switchboard 作为单语语料库,而 BABEL 提供多语言环境。LibriSpeech 子集明确限制为 100 小时音频。
- 训练用途与处理: MiniLibriSpeech、Switchboard 和 BABEL 依赖强制对齐(forced alignments)来指导训练,而 100 小时 LibriSpeech 设置采用无需先前对齐的平启动(flat start)方法。作者通过配置这些配方,以相同超参数验证 PyTorch LF-MMI 框架与等效 Kaldi 基线的对比效果。
- 额外处理说明: 所提供的实验设置未详述具体的音频裁剪策略或自定义元数据构建,仅提及上述对齐依赖关系。
方法
作者利用模块化框架,旨在将 Kaldi 的无图谱最大互信息(LF-MMI)训练能力集成至 PyTorch,使用户能够借助现代深度学习工具链的灵活性来训练声学模型。该集成的核心是一个名为 pkwrap 的 Python 软件包,它作为 Kaldi C++ 库的轻量级包装器,通过兼容 PyTorch 的接口暴露关键功能。该框架由两个主要部分组成:处理底层操作(如 Kaldi 与 PyTorch 之间的矩阵转换)的 C++ 后端,以及用户直接交互的 Python 接口。这种分离设计在保持易用性的同时实现了高效的数据处理。
训练过程的核心是 LF-MMI 成本函数,该函数通过 PyTorch 的 torch.autograd.Function 接口暴露为自定义 autograd 函数。此功能通过 KaldiChainObjfFunction 类实现,从而在 PyTorch 计算图中实现无缝梯度计算。该函数通过一个镜像 Kaldi ChainTrainingOptions 的选项类接收参数(例如交叉熵项的权重),使用户无需修改底层 C++ 代码即可配置训练行为。成本计算由 Kaldi 本身执行,数据转移开销极小,因为两个系统之间仅传递内存指针。
训练框架支持 LF-MMI 训练两种主要方法:一种使用预训练模型(如 HMM/GMM)的对齐结果,另一种使用完整双音素树(full-biphone tree)执行平启动训练。这两种方法均通过软件包的配方(recipes)得到支持,其中包含用于训练和解码的脚本。当前配方依赖 Kaldi 生成训练样本和序列,尽管这些步骤已通过子进程调用进行封装。用户可访问生成的文件(通常存储在 egs/ 目录中)以进行进一步分析或使用。
在模型架构方面,框架将时间延迟神经网络(TDNN)和因子化 TDNN 实现为标准 torch.nn.Module 类。TDNN 模型的上下文信息必须手动指定,这反映了当前设计对灵活性和控制权的重视。训练过程采用指数学习率衰减策略,与 Kaldi 的标准实践保持一致。
为解决 PyTorch 在分布式训练方面的限制,特别是在无多 GPU 配置的环境中,该框架通过暴露 Kaldi 的自然梯度计算来支持自然梯度随机梯度下降(NG-SGD)。这是通过一个自定义 PyTorch 函数实现的,该函数在前向传播期间执行线性变换,并在后向传播期间调用 Kaldi 的自然梯度逻辑。该实现借鉴了 Kaldi 对 NaturalGradientAffineTransform 和 NGState 的使用,确保与现有训练工作流的兼容性。 [[IMG:]]
实验
评估环节将基于 PyTorch 的 Pkwrap 框架与传统 Kaldi 工具包进行对比,测试范围涵盖标准英语、多语言以及平启动语音识别任务,以验证框架的互操作性和训练兼容性。这些实验评估了替代优化算法和架构配置在不同声学条件及语言建模设置下的表现。定性来看,Pkwrap 在所有数据集上均稳定达到或超越成熟的 Kaldi 基线,展现出可靠的收敛性与具有竞争力的识别准确率,尽管初始化与训练策略存在差异。总体而言,结果证实 Pkwrap 为现代语音识别流水线提供了一种稳健且原生支持 PyTorch 的替代方案,且未牺牲性能。
作者使用词错误率(WER)作为指标,对比了 Kaldi 和 Pkwrap 框架在语音识别任务上的性能。结果表明,Pkwrap 在多个数据集上的 WER 均低于 Kaldi,说明在特定配置下具有相当或更优的性能。在 Minilibrispeech 数据集上,Pkwrap 的词错误率低于 Kaldi。在 Switchboard 任务中,Pkwrap 的词错误率优于 Kaldi,尤其是在 SWBD 和 CH 子集上。Pkwrap 在多语言 BABEL 数据集和 Librispeech 100 小时子集上均展现出比 Kaldi 更优的性能。

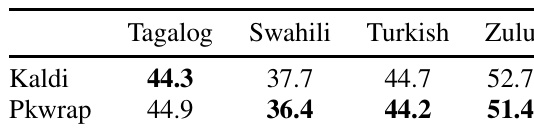
作者使用 BABEL 数据集对比了 Kaldi 和 Pkwrap 框架在多语言语音识别任务上的性能。结果表明,Pkwrap 在所有四种目标语言上的词错误率均低于 Kaldi,表明在多语言建模设置中表现更佳。Pkwrap 在 BABEL 全部四种目标语言上的词错误率均优于 Kaldi。在 Tagalog、Swahili、Turkish 和 Zulu 语言上,Pkwrap 的词错误率均低于 Kaldi。结果证实 Pkwrap 在多语言语音识别任务中持续优于 Kaldi。
作者使用 TDNN 模型对比了 Kaldi 和 Pkwrap 框架在不同数据集语音识别任务上的性能。结果表明,Pkwrap 在 Switchboard 和 Callhome 子集上的词错误率低于 Kaldi,在 3-gram 和 4-gram 语言模型下均观察到性能提升,特别是在未使用 i-vectors 和 LDA 时。Pkwrap 在 Switchboard 数据集的 SWBD 和 CH 子集上均优于 Kaldi,词错误率更低。与 3-gram 模型相比,在 4-gram 语言模型下 Pkwrap 与 Kaldi 的性能差距更为明显。与 Kaldi 基线不同,Pkwrap 即使不使用 i-vectors 或 LDA 预处理,在 Switchboard 上也能取得具有竞争力的结果。

作者使用 TDNN 模型对比了 Kaldi 和 Pkwrap 框架在 Librispeech 数据集上的性能。结果表明,Pkwrap 在所有评估子集上的词错误率均低于 Kaldi,表明在平启动建模设置中表现更佳。Pkwrap 在 Librispeech 数据集的所有评估子集上均优于 Kaldi。在 dev-clean 和 test-clean 子集上,Pkwrap 的词错误率均低于 Kaldi。在 dev-other 和 test-other 子集上,Pkwrap 也展现出对 Kaldi 的持续性能提升。

作者展示了 Kaldi 和 Pkwrap 框架在多个数据集(包括 Minilibrispeech、Switchboard 和 BABEL)上声学模型性能的对比结果。结果表明,Pkwrap 在多种设置下达到了与 Kaldi 相当或更优的性能,特别是在多语言和平面启动建模场景中。在 BABEL 数据集的多语言语音识别中,Pkwrap 展现出与 Kaldi 相当的性能。在 Switchboard 评估集上,Pkwrap 的词错误率相比 Kaldi 实现了相对提升。该框架在 Librispeech 100 小时子集的平启动训练中展现出有效性,采用了不同的优化策略和模型架构。
评估设置将 Pkwrap 框架与 Kaldi 基线进行对比,测试范围涵盖多种语音识别任务,包括单语、多语言及平启动建模场景。这些实验在 Librispeech、Switchboard 和 BABEL 等多样化数据集上验证了框架性能,同时测试了不同的 TDNN 配置、语言模型阶数及预处理流程。定性来看,无论具体数据集或架构设置如何,Pkwrap 均稳定实现更优的识别准确率,在多语言环境和简化预处理流程中优势尤为显著。总体而言,研究结果证实 Pkwrap 可作为传统语音识别基线的稳健且极具竞争力的替代方案。