Command Palette
Search for a command to run...
信用卡欺诈检测预测模型
摘要
一句话总结
本文提出了一种无监督信用卡欺诈检测方法,该方法通过为常规客户消费模式拟合ARIMA模型来识别异常偏差,在不平衡数据集上展现了优于K-Means、Box-Plot、局部异常因子(Local Outlier Factor)和隔离森林(Isolation Forest)的检测能力。
核心贡献
- 本文提出了一种无监督时间序列框架用于信用卡欺诈检测,该框架完全依赖单个客户的消费行为,无需标注的真实标签数据。
- 该方法结合ARIMA模型与滚动窗口机制,以捕捉常规交易模式,并将统计偏差标记为异常。
- 在信用卡数据集上的评估表明,所提方法优于四种成熟的异常检测基线模型,即K-Means、Box-Plot、局部异常因子和隔离森林。
引言
信用卡的快速普及推动了金融欺诈的激增,使得自动化检测系统成为保护消费者和金融机构的必要手段。尽管先前研究高度依赖监督机器学习算法,但这些方法在面对严重不平衡的数据集、稀缺的标注数据以及无法适应不断变化的客户消费模式时存在局限。为弥补这些不足,作者利用无监督异常检测框架,通过ARIMA时间序列模型对每位客户的每日交易次数进行建模。通过应用滚动窗口技术,该方法无需真实标签即可识别偏离个人消费行为的情况,为持续欺诈监控提供了更具适应性的解决方案。
数据集
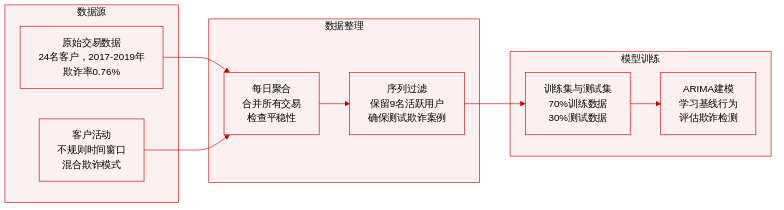
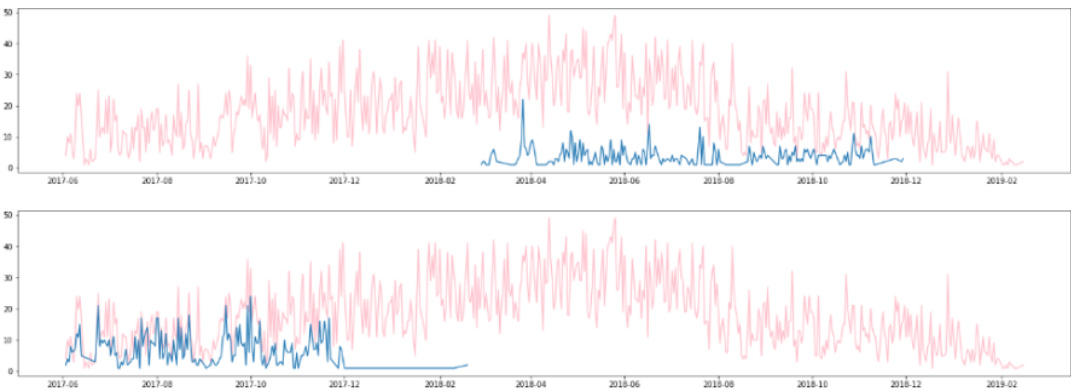
- 数据集构成与来源: 作者使用了由NetGuardians SA提供的专有信用卡交易数据集,涵盖某未具名金融机构24位客户在2017年6月至2019年2月期间的交易记录。每条记录包含时间戳、交易金额以及二值欺诈标签。
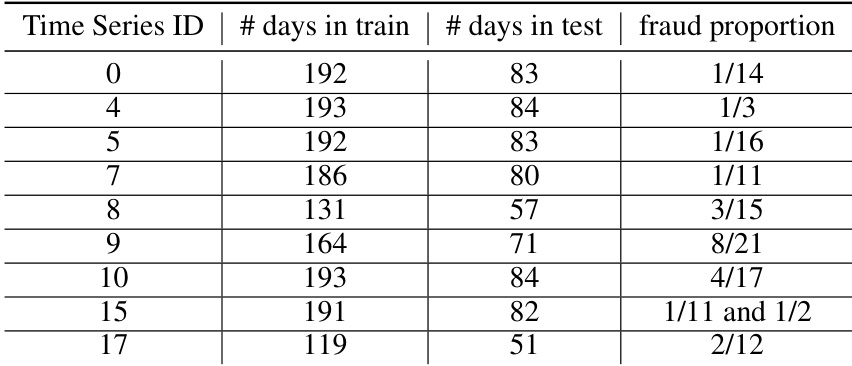
- 子集详情与过滤: 该数据集高度不平衡,欺诈交易仅占所有记录的0.76%。客户活动呈现不规则特征,部分用户仅在特定时间窗口内进行交易。为满足建模需求,作者将初始的24条客户序列筛选为9条最终时间序列。
- 训练集划分与用途: 数据采用70-30的训练集与测试集划分方式。训练阶段需要充足的正常交易量以学习客户基线行为,而测试阶段必须包含至少一个欺诈案例以供评估。此限制自然排除了欺诈事件完全落在训练窗口内的客户。
- 处理与预处理: 交易数据按日聚合以监控交易量和欺诈频率。作者采用增强迪基-福勒(Augmented Dickey-Fuller)检验来验证时间序列的平稳性,并在必要时进行差分处理。最终九条序列被格式化为适用于ARIMA建模的数据,并为每位客户计算和记录每日欺诈比率。
方法
作者利用自回归积分滑动平均(ARIMA)模型检测信用卡交易数据中的异常,重点在于对单个客户的常规消费行为进行建模。该框架基于以下假设:欺诈行为会引入每日交易次数的预期模式偏差。为实现这一目标,ARIMA模型被应用于表示每位客户每日交易次数的时间序列数据,旨在捕捉正常行为背后的时间动态特征。
整体流程始于对时间序列进行预处理以确保平稳性,这是ARIMA建模的基本要求。平稳性通过增强迪基-福勒(ADF)检验进行评估,若序列被判定为非平稳,则应用差分处理以实现平稳。确认平稳性后,模型阶数通过Box-Jenkins方法确定,该方法包含三个主要阶段:识别、估计和诊断。
在识别阶段,自回归(AR)阶数 p 和滑动平均(MA)阶数 q 通过自相关函数(ACF)和偏自相关函数(PACF)进行选择。这些函数有助于区分两种模型的衰减模式:AR(p)过程的ACF通常逐渐衰减,而其PACF在滞后阶数 p 后截断;反之,MA(q)过程的ACF在滞后阶数 q 后截断,而其PACF逐渐衰减。该信息指导 p 和 q 的适当取值选择。

确定模型阶数后,估计阶段涉及使用最大似然估计将ARIMA模型拟合到训练数据。此步骤计算最能描述观测时间序列的系数 ϕ 和 θ,旨在最小化预测误差。随后在诊断阶段评估所得模型,以确保残差呈现白噪声特征,即残差互不相关,服从均值为零且方差恒定的正态分布。残差分析确认误差中不再残留时间结构,表明模型拟合良好。
针对欺诈检测,训练好的ARIMA模型通过滚动窗口方法在测试集上生成一步向前预测。计算实际交易次数与预测交易次数之间的预测误差,并为每个误差计算Z分数,以量化其偏离预期行为的程度。Z分数的定义如下:
z-score=σx−μ其中 x 为预测误差,μ 为训练集样本内预测误差的均值,σ 为这些误差的标准差。设定阈值为3;任何Z分数超过该值的日期均被标记为异常,表明可能存在欺诈。
该方法将欺诈检测视为异常检测问题,其中偏离已学习正常模式的情况被识别为可疑。该方法仅依赖时间序列的结构,无需标注的欺诈数据,使其适用于标注欺诈样本稀缺或不可用的场景。整个过程独立应用于每位客户的交易时间序列,从而实现对消费行为的个性化建模。
实验
评估将基于无监督ARIMA的欺诈检测模型与四种基准算法进行比较,使用自然发生和合成增强的交易数据集,以验证其在不同欺诈密度下的性能。实验表明,ARIMA方法通过有效减少误报并利用滚动窗口适应动态的客户消费模式,始终提供更高的精确度和整体可靠性。尽管基准模型偶尔能取得更高的召回率,但所提方法在检测每日集中出现的欺诈尝试时表现出更强的鲁棒性。研究得出结论,尽管该模型效果显著,但其对等间隔时间序列的依赖需要进一步改进,以准确处理不规则的交易时间戳。
作者使用精确率、召回率和F分数作为评估指标,将基于ARIMA的信用卡欺诈检测模型与多种基准异常检测模型(包括Box-Plot、局部异常因子、隔离森林和K-Means)进行比较。结果显示,ARIMA模型取得了最高的精确率和F分数,K-Means在召回率方面表现最佳,而局部异常因子在基准模型中效果最差。ARIMA模型在精确率和F分数上优于基准模型。K-Means在所有模型中召回率最高。局部异常因子在评估中是效果最差的基准模型。

作者使用信用卡数据集中的多条时间序列,将基于ARIMA的模型与多种基准异常检测方法(包括Box-Plot、局部异常因子、隔离森林和K-Means)进行比较。结果表明,ARIMA模型在精确率和F分数方面表现优异,K-Means在召回率方面表现最佳,而局部异常因子的整体表现最弱。由于欺诈发生率较低,分析仅在有限的时间序列集上进行,并通过在测试数据中注入模拟欺诈来进一步测试鲁棒性。与基准模型相比,ARIMA取得了最高的精确率和F分数。K-Means提供了最佳的召回率,而局部异常因子在模型中表现最差。ARIMA模型的优势在于对正常客户行为的建模,并通过滚动窗口适应动态消费模式。
作者使用三项性能指标将基于ARIMA的模型与四种基准异常检测模型进行比较。结果显示,ARIMA模型取得了最高的精确率和F分数,K-Means在召回率方面表现最佳,而局部异常因子在大多数指标上表现最低。与所有基准模型相比,ARIMA取得了最高的精确率和F分数。K-Means在召回率方面表现最佳,而局部异常因子在大多数指标上表现最低。Box-Plot是唯一在F分数上与ARIMA相当的基准模型。
{"summary": "The authors compare their ARIMA-based model to several benchmark anomaly detection models on credit card fraud detection tasks. Results show that the ARIMA model outperforms the benchmarks in terms of precision and F-measure, while other models achieve better recall or have limitations in this specific context.", "highlights": ["The ARIMA model demonstrates superior precision and F-measure compared to benchmark models.", "K-Means achieves the highest recall among the models, while Local Outlier Factor performs poorly in precision and F-measure.", "The ARIMA model's effectiveness is attributed to its ability to model dynamic customer spending behavior and detect anomalies during periods of concentrated fraud activity."]

作者将ARIMA模型与四种基准异常检测模型在信用卡欺诈检测任务上进行了比较。结果显示,ARIMA取得了最高的精确率和F分数,K-Means在召回率方面表现最佳,而局部异常因子在测试模型中效果最差。ARIMA在精确率和F分数上优于基准模型。与模型相比,K-Means取得了最高的召回率。局部异常因子在所有指标上表现最低。

该研究使用信用卡交易数据,将基于ARIMA的方法与标准异常检测基准进行评估,以检验其建模动态消费行为和识别欺诈活动的能力。尽管聚类技术对罕见事件表现出更强的敏感性,但所提时间序列框架通过有效追踪客户正常模式并适应波动趋势,始终提供更可靠的检测结果。使用模拟异常进行的鲁棒性测试进一步证实了该模型在稀疏欺诈环境中的可靠性,确立了其作为检测集中欺诈事件的高效解决方案的地位。