Command Palette
Search for a command to run...
Music SketchNet:通过音高与节奏的分解表示实现可控音乐生成
Music SketchNet:通过音高与节奏的分解表示实现可控音乐生成
Ke Chen Cheng-i Wang Taylor Berg-Kirkpatrick Shlomo Dubnov
一键部署谛韵 DiffRhythm:1 分钟即可生成完整音乐 Demo
摘要
受自动图像补全系统的启发,我们提出了 Music SketchNet,这是一种神经网络框架,允许用户指定部分音乐创意以引导自动音乐生成。我们专注于在周围上下文的条件下,以及可选地由用户指定的音高和节奏片段引导下,为不完整的单声部音乐作品生成缺失的小节。首先,我们引入了 SketchVAE,这是一种新颖的变分自编码器,它显式地将节奏和音高轮廓进行分解,从而构成我们所提出模型的基础。接着,我们介绍了两种判别式架构:SketchInpainter 和 SketchConnector,它们协同工作以实现受引导的音乐补全,即在周围上下文和用户指定片段的条件下,为缺失的小节生成表示。我们在标准的爱尔兰民间音乐数据集上对 SketchNet 进行了评估,并与近期工作中的模型进行了比较。当用于音乐补全时,我们的方法在客观指标和主观听力测试方面均优于当前最先进的模型。最后,我们证明我们的模型能够在生成过程中成功融入用户指定的片段。
一句话总结
Music SketchNet 是一个可控的音乐生成框架,采用 SketchVAE 对音高轮廓和节奏进行分解,同时 SketchInpainter 和 SketchConnector 架构在周围上下文和可选用户指定片段的条件下,引导单声部作品中缺失小节的补全,在标准爱尔兰民间音乐数据集上,该框架在客观指标和主观听觉测试中均取得了最先进的性能。
核心贡献
- 本文提出了 Music SketchNet,这是一个神经网络框架,能够通过周围上下文和可选的用户指定音高与节奏草图,生成不完整单声部作品中的缺失小节。
- 该架构采用 SketchVAE 将潜在表示显式分解为解耦的音高轮廓和节奏分量,随后由 SketchInpainter 和 SketchConnector 模块处理,以便在生成过程中整合用户输入。
- 在标准爱尔兰民间音乐数据集上的评估表明,该框架在客观指标和主观听觉测试中均优于最新的先进模型,同时成功兼容了可选的用户指定条件。
引言
神经网络已显著推动了自动音乐生成的发展,但实现直观的用户控制对于实际创意应用依然至关重要。先前的条件生成方法通常要求用户提供完整的音乐曲目或依赖基础音符约束,而现有的补全技术则缺乏明确的用户引导。本文借鉴计算机视觉中的草图范式,提出了 Music SketchNet 框架。该框架利用分解式变分自编码器,将音乐小节解耦为独立的音高轮廓和节奏潜在变量。此架构允许创作者指定部分音乐构思,模型会将其与上下文感知的预测无缝结合,从而生成高度可控的乐曲。
方法
提出的 Music SketchNet 框架旨在通过补全单声部音乐作品中的缺失小节来实现引导式音乐生成,其依据是周围上下文以及可选的用户指定音高和节奏片段。该架构由三个核心组件构建而成:SketchVAE、SketchInpainter 和 SketchConnector。这三者共同构成了一个用于编码、预测和细化音乐潜在表示的层级系统。
系统的基础是 SketchVAE,它作为音乐表示的分解式变分自编码器。该模块将音高和节奏信息显式分离到独立的潜在维度 zpitch 和 zrhythm 中,从而实现独立控制与操作。SketchVAE 处理音乐小节时,首先将其编码为两个独立的 token 序列:xpitch 包含带有填充的音符值以填满 24 帧的小节,而 xrhythm 则通过用特定节奏 token 替换音高事件来捕获时值与起音信息。随后,这些序列分别通过两个独立的基于 GRU 的编码器进行编码,其中音高使用 Qθ,节奏使用 Qτ,其输出被拼接以形成完整的潜在变量 z=[zpitch,zrhythm]。层级解码器 Pϕ 从该潜在表示中重构原始音乐,首先通过“beat”GRU 层将小节解码为节拍,随后通过“tick”GRU 层将每个节拍分解为独立的 tick。这种两阶段解码过程确保了输出以符合音乐直觉的方式生成。关于 SketchVAE 结构(包括其编码器与层级解码器)的视觉概览,请参阅框架示意图  。
。
SketchInpainter 组件负责利用周围音乐上下文生成缺失小节的初始预测。它以过去和未来的上下文潜在序列 Zp 和 Zf 作为输入,并使用两组独立的 GRU 分别对音高和节奏进行处理。这些编码器的最终隐藏状态 ht1 和 ht3 被用作两个独立生成 GRU 的初始状态,即音高生成 GRU 和节奏生成 GRU。这些生成 GRU 基于上下文信息,以自回归方式预测缺失的潜在表示 Sm=(Spitch,Srhythm)。预测得到的潜在序列随后被输入 SketchVAE 解码器以生成音乐输出,该输出用于在训练过程中计算交叉熵损失。此初始预测步骤为缺失音乐材料的生成奠定了坚实的基础。
为融入用户引导并细化初始预测,系统引入了 SketchConnector 模块。该组件通过整合用户指定的草图信息 C 来修改 SketchInpainter 的潜在预测。处理流程首先将预测值 Sm 与过去和未来的潜在序列拼接,随后执行随机去掩码操作,将部分预测潜在变量(设定比例为 0.3)替换为真实值,以此模拟用户提供的上下文。该机制类似于 BERT 风格的训练,但采用去掩码而非掩码策略,旨在促使模型学习相邻音乐元素之间更强的关联性。去掩码数据与预测的 Sm 随后被输入带有绝对位置编码的 Transformer 编码器,从而生成缺失小节的最终细化潜在表示 Zm。该细化潜在变量随后由 SketchVAE 解码,以生成最终的音乐输出。如下方图片所示,SketchConnector 充当最终细化步骤,确保生成的音乐同时契合上下文提示与用户指定的草图输入 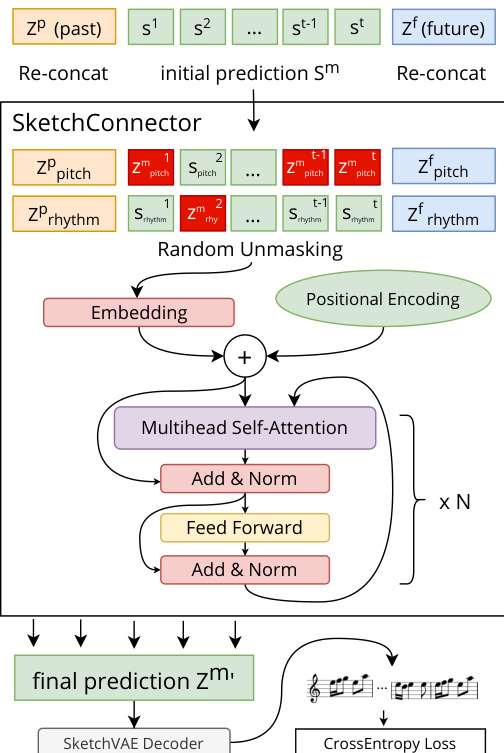 。
。
实验
该评估通过客观生成指标、主观人类听觉测试以及交互式控制场景,将 SketchNet 与既定基线模型进行对比,以验证其补全能力。客观与主观结果均表明,该模型在音高准确性与整体音乐性方面持续优于竞品,能够有效捕捉重复模式,同时在非重复段落中保持上下文连贯性。尽管音符复杂度相近,人类听众仍对生成旋律在结构完整性和和声质量上的显著提升表示认可。此外,交互式实验证实该系统能够可靠地遵循用户指定的音高与节奏草图,证明了其作为高度可控音乐生成工具的有效性。
本文通过将 SketchNet 模型与基线系统进行对比来评估其性能,重点考察生成旋律中的音高与节奏准确性。实验包含虚拟控制测试,以评估用户指定的节奏与音高信息如何影响模型输出。结果表明,该模型在遵循用户控制的节奏与音高方面均能达到较高准确率,其中音高跟随表现更优。与基线模型相比,SketchNet 在生成音高与节奏准确的旋律方面展现出更优越的性能。该模型能有效遵循用户指定的节奏与音高控制,且在两种情况下均保持高准确率。用户控制对生成输出具有显著影响,模型在匹配指定节奏与音高模式时表现出极高的准确性。
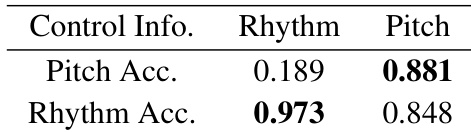
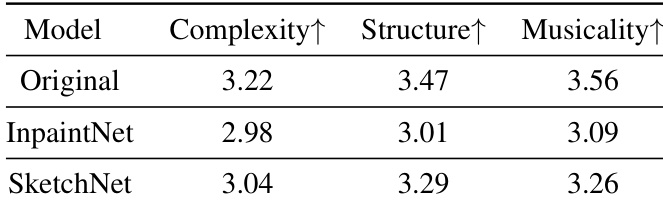
本文将 SketchNet 与 Music InpaintNet 及其他基线模型进行对比,通过客观指标与主观听觉测试评估其性能。结果表明,SketchNet 在生成旋律方面优于其他模型,尤其在结构与整体音乐性方面表现突出,同时保持了相当的复杂度。该模型在交互式场景中也展现出对音高与节奏的有效控制能力。在主观评估中,SketchNet 的结构与音乐性得分均高于 InpaintNet。模型在重复与非重复测试子集上的性能均优于基线。对音高与节奏的用户控制能够实现定向生成,且对指定输入的遵循准确率很高。
本文在不同测试子集上将 SketchNet 与多个基线模型(包括 Music InpaintNet 及 SketchVAE 的多种变体)进行对比评估。结果表明,SketchNet 在准确率与损失值方面均持续优于其他模型,尤其在无法依赖复制策略的非重复场景中表现更为显著。该模型通过用户指定的音高与节奏提示,对生成旋律展现出强大的控制力。SketchNet 在所有测试子集中均取得最佳性能,在准确率与损失指标上全面超越所有基线模型。性能提升在音高准确性方面比节奏准确性更为明显,尤其是在非重复场景中。受用户控制的音高与节奏输入对生成输出具有显著影响,模型在遵循指定控制条件时保持高准确率。
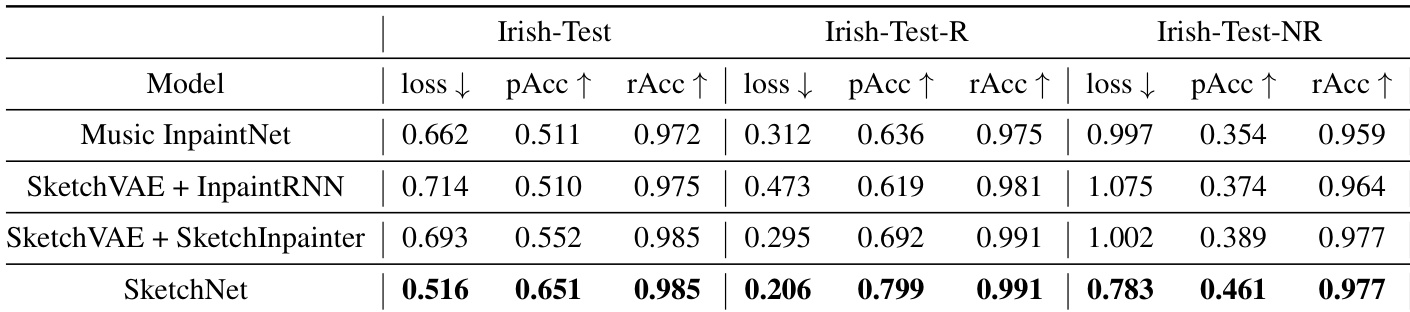
该评估通过客观指标与主观听觉测试,在重复与非重复场景中对比 SketchNet 与多个基线系统,以验证其在用户定义的音高与节奏约束下生成音乐连贯旋律的能力。结果一致表明,SketchNet 在结构完整性与整体音乐性方面超越竞争方法,同时能够精确遵循用户指定的控制条件。该模型在交互式生成任务中尤为有效,用户提示显著塑造了生成输出,且在复杂非重复语境下,音高对齐效果优于节奏跟踪。