Command Palette
Search for a command to run...
一键部署 Mellum-4b-base:专为代码补全设计的模型
摘要
一句话总结
作者提出了一种面向现代 IDE 代码补全的序列模型。该模型优先考虑实际部署约束而非 next-token 预测精度,通过确保类型检查有效性、实现瞬时推理,并为本地离线使用保持紧凑的磁盘与内存占用。这与仅针对预测指标优化的先前深度神经网络不同。
核心贡献
- 引入了一种 partial token 语言模型,以满足实际 IDE 约束。该模型通过生成类型有效的建议、返回瞬时结果,并保持紧凑的磁盘与内存占用来实现这一目标。
- 严格的预处理流程消除了训练集与测试集划分中的重复样本,防止准确率指标被人为夸大。
- 在开源 GitHub Dart 语料库上的评估表明,该模型实现了比先前基于 pointer network 的方法更高的 next-token 预测精度。
引言
代码补全已演变为 IDE 的关键功能,能够加速打字、验证正确性并简化 API 导航。然而,开发者要求建议必须满足严格的延迟与本地计算约束。以往的机器学习方法(涵盖 n-gram 模型、循环网络及 pointer 架构)虽提升了上下文排序能力,但在处理词表外标识符、受限于工作站内存以及保证语法有效输出方面始终面临挑战。此外,评估协议的不一致与未察觉的数据集重复现象,历来导致各项研究的准确率指标被夸大。作者通过引入一种专为现代 IDE 环境优化的 partial token 语言模型来解决这些瓶颈。该模型在严格去重的 Dart 语料库上实现了最先进的预测精度,同时谨慎平衡了推理速度、模型规模与输出有效性。
数据集
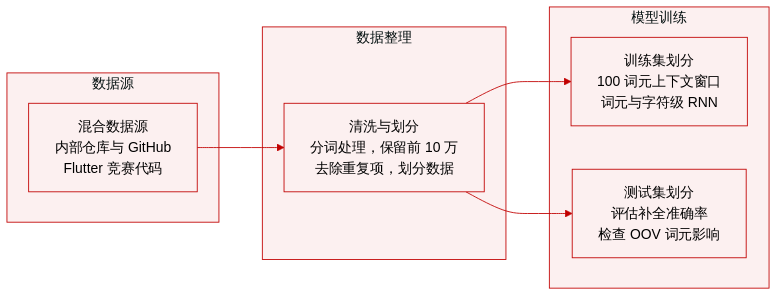
- 数据集构成与来源: 作者评估了三个独立的 Dart 语料库,以分析词表重叠度与自动补全性能。第一个来自某大型软件公司的内部仓库,第二个由托管在 GitHub 上的开源 Dart 代码组成,第三个包含来自 Flutter 移动应用开发竞赛的提交内容。
- 子集详情与过滤: Internal 语料库主要包含 AngularDart Web 应用,其独特词表占比为 80%。GitHub 语料库包含通用 Dart 框架与库,无特定公司引用,独特词表占比为 71%。Flutter Create 语料库规模较小但高度多样化,包含限制在 5kb Dart 代码内的移动应用。其独特词表占比为 54%,且包含的 unique tokens 总数少于 100,000 个。
- 数据处理与模型使用: 作者使用 token 扫描器将源文件转换为 token 列表,并选取出现频率最高的 100,000 个 tokens 作为输出词表。稀有 tokens 被替换为特殊占位符以稳定训练。为防止因广泛代码重复导致的数据泄露,精确重复的序列已被移除。每个语料库均划分为训练集与测试集,每个数据集训练两个独立的 RNN,一个处理 token 序列,另一个处理字符序列。
- 上下文窗口与训练策略: 作者使用固定的 100-token 上下文窗口构建 next-token 预测样本。每个关键字、标识符或字面量均作为前 100 个输入的目标标签。尽管这些语料库仅共享约 13% 的合并词表,但重叠的 tokens 占据了整体概率质量的 90% 以上。这表明,结合局部引用的固定输出词表在代码补全中依然有效。
方法
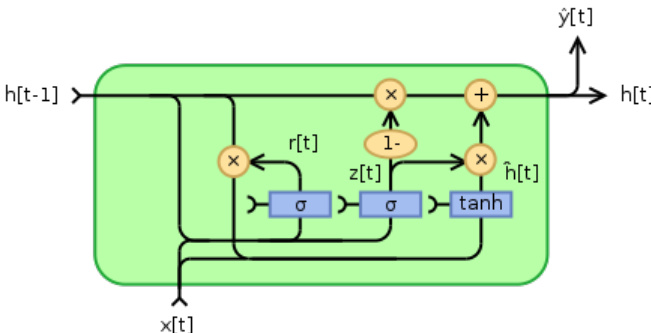
作者采用了一种混合神经网络架构,旨在平衡预测精度与交互式代码补全系统的严格性能约束。核心框架将字符级输入表示与 token 级输出相结合,使模型能够预测完整的 tokens,同时保留源代码的细粒度模式。该设计允许模型通过局部重复检测机制有意义地表示词表外 (OOV) tokens,该机制会为输入序列中出现的 tokens 分配概率。整体架构基于循环神经网络 (RNN),采用门控循环单元 (GRU) 单元处理序列依赖,并在隐藏状态与输出 softmax 之间设置投影层以降低预测延迟与模型规模。如图所示,GRU 单元通过重置门与更新门将当前输入与上一隐藏状态相融合,使网络能够选择性保留或遗忘信息,从而有效管理代码序列中的长期依赖。
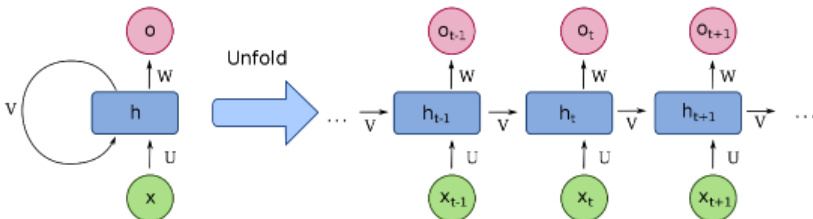
模型的输入表示是其设计的关键组件。为解决在 RNN 有限内存容量下处理长序列的挑战,作者采用了 subtoken 编码,依据 camelCase 与 snake_case 惯例将标识符名称拆分为词素。如图 4 所示,该方法使模型能够以比纯字符级输入更少的时序步处理更长的前置代码上下文。subtoken 编码使模型能够通过将相关词元(如 "ResourceProvider" 与 "FileResourceProvider")视为共享词素序列来建立关联。该策略直接回应了纯字符级模型的局限性,后者需要大量时序步来表示单个 token,且计算成本高昂。
为生成预测结果,模型处理光标前代码上下文中的 token 序列。对于 token 级模型,该序列直接输入网络。对于 subtoken 模型,每个 token 首先被拆分为其组成的 subtokens。网络随后在该序列上进行展开,在每个时序步生成隐藏状态。最终隐藏状态经过线性层投影并输入 softmax 层,以计算输出词表上的概率分布。一项关键创新是引入了独立的辅助网络来预测局部重复概率。该网络与主语言模型共享相同的输入与隐藏表示,但使用 sigmoid 函数输出单一概率值。在预测阶段,该概率用于重新加权主模型的输出分布,将分配给输入序列中 tokens 的概率质量缩放为重复概率,其余部分缩放为一减去该概率。此机制使模型能够为从上下文中重复出现的 OOV tokens 分配非零概率,从而有效利用源代码中频繁发生的局部重复现象。最终预测结果结合了模型输出与静态分析结果,后者枚举了有效关键字与作用域内标识符,确保建议既准确又符合语法规范。
实验
评估通过多个语料库与架构上的 top-k 精度测量,以及旨在模拟真实预测工作负载的延迟基准测试来衡量模型质量。结果表明,partial token 架构始终优于标准 token 模型,其预测能力随训练数据量增加而正向扩展,并显著超越静态分析基线。集成的重复检测机制有效识别重复 tokens,并以高可靠性重新校准概率分布。此外,训练后量化成功优化了推理速度以满足交互式延迟目标,证实当前模型规模非常适合用户体验,同时凸显了多子词预测方法在实时代码补全中的不切实际。
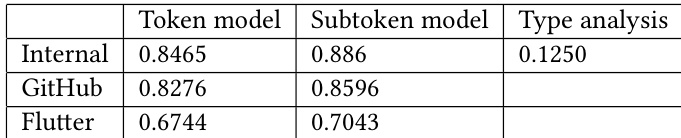
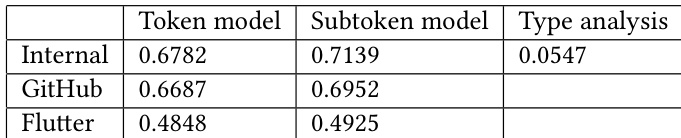
作者在不同代码语料库上比较了两种模型变体(token 模型与 subtoken 模型),结果显示 subtoken 模型实现了更高的精度。结果表明模型性能随语料库规模扩大而提升,且 subtoken 模型在所有数据集上均持续优于 token 模型。评估还包含延迟基准测试,证明训练后量化带来了显著的速度提升,大部分请求在目标阈值内完成。subtoken 模型在所有语料库的精度上均优于 token 模型。随着语料库规模增长,精度随之提升,subtoken 模型表现出一致的改进。训练后量化降低了预测延迟,大部分请求在目标阈值内完成。
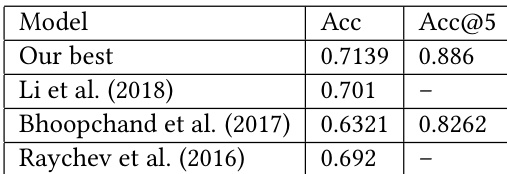
作者使用精度指标将自身模型与最先进方法进行比较,结果显示其模型性能更高。结果表明模型预测能力随语料库规模扩大而提升,在 top-1 与 top-5 精度上均优于现有方法。量化后的模型满足延迟要求,表明其已针对实时使用进行优化。与先前工作相比,该模型实现了更高的 top-1 与 top-5 精度。模型性能随语料库规模扩大而提升,并超越现有方法。训练后量化降低了预测延迟,使其能够在目标限制内实现实时使用。
作者在三个语料库上评估了两种模型变体,结果显示 subtoken 模型在精度上优于 token 模型,且随着语料库规模扩大,性能提升明显。性能基准测试表明,训练后量化显著降低了预测延迟,在保持效率的同时使其接近目标阈值。subtoken 模型在所有语料库中的精度均高于 token 模型。两种模型变体的精度均随语料库规模扩大而提升。训练后量化降低了预测延迟,大部分请求在 110ms 内完成。
评估在多个代码语料库上比较了 token 与 subtoken 模型变体,同时将推理延迟与最先进方法进行基准测试。结果表明,subtoken 架构始终产生更优的精度,预测性能随训练数据量增加而正向扩展。此外,延迟基准测试证实,训练后量化有效优化了推理速度,使其能够在不牺牲模型可靠性的前提下实现实时部署。综合而言,这些实验验证了 subtoken 建模的架构优势以及量化在生产环境中的实际可行性。