Command Palette
Search for a command to run...
示例归一化用于学习深度表示
示例归一化用于学习深度表示
Ruimao Zhang Zhanglin Peng Lingyun Wu Zhen Li Ping Luo
层归一化
摘要
归一化技术在各类先进神经网络和不同任务中至关重要。本研究通过提出示例归一化(Exemplar Normalization, EN),探讨了一种新颖的动态“学习即归一化”(Learning-to-Normalize, L2N)问题,该方法能够为深度网络中的不同卷积层和图像样本学习不同的归一化方法。EN 显著提升了近期提出的可切换归一化(Switchable Normalization, SN)的灵活性;SN 通过将几种归一器在每个归一化层中线性组合来解决静态 L2N 问题(该组合对所有样本相同)。与条件批归一化(conditional Batch Normalization, cBN)直接采用多层感知机(MLP)来学习数据依赖参数不同,EN 的内部架构经过精心设计以稳定其优化过程,从而带来诸多有益特性:(1)EN 使不同的卷积层、图像样本、类别、基准和任务能够使用不同的归一化方法,为从整体视角分析它们提供了新思路。(2)EN 对多种网络架构和任务均有效。(3)它可以替换深度网络中的任意归一化层,同时仍能保持模型训练的稳定性。大量实验证明了 EN 在广泛的任务谱系中的有效性,包括图像识别、噪声标签学习和语义分割。
一句话总结
本文提出示例归一化(Exemplar Normalization, EN),这是一种动态归一化学习方法。该方法通过精心设计的内部架构,学习特定层与特定样本的归一化参数,避免了基于多层感知机(MLP)或静态线性组合的不稳定性,从而稳定优化过程,并在图像识别、噪声标签学习和语义分割任务中提升性能。
核心贡献
- 本文提出示例归一化(EN),这是一种动态归一化框架,能够自适应地为单个图像样本和卷积层分配不同的归一化方法。通过使用精心设计的内部架构替代标准的多层感知机参数学习,EN 在训练和推理阶段均能实现样本级和层级的定制化归一化,同时稳定优化过程。
- 该方法建立了一个灵活的分析框架,用于考察不同归一化器在网络各层中的运作方式及其与不同输入样本的关联性。此能力使得不同的卷积层、图像样本、类别、基准和任务能够采用不同的归一化方法,从而促进对其相互关系的整体分析。
- 大量实验表明,EN 可作为即插即用模块,在不牺牲训练稳定性的前提下,替换多种架构中的现有归一化层。在 ImageNet、WebVision、ADE20K 和 Cityscapes 上的评估显示,EN 带来了持续的性能提升;当集成到标准 ResNet50 模型中时,其改进幅度最高可达可切换归一化(Switchable Normalization)的 300%。
引言
归一化技术对于稳定训练过程并在计算机视觉应用中最大化卷积神经网络的性能至关重要。尽管近期的混合方法尝试结合多种归一化器,但它们通常依赖静态学习策略,对所有图像应用相同的归一化比例,这限制了实例级别的适应性,并常常导致次优的准确率。为突破这一瓶颈,本文利用示例归一化(EN)引入了一种动态归一化框架,该框架能够自动为每个样本和网络层选择最合适的归一化器。通过精心设计轻量级内部架构,EN 避免了早期条件方法的过拟合陷阱,同时作为即插即用模块,在多种基准测试中持续提升性能,并揭示了不同图像类别处理视觉信息的机制。
方法
本文提出示例归一化(EN),这是一种动态归一化框架,通过为每个卷积层内的独立样本学习不同的归一化策略,实现数据依赖型归一化。EN 扩展了可切换归一化(SN)的能力,引入了样本特定的重要性比例,使得小批量中的每张图像都能自适应地组合多种归一化方法。EN 的核心架构围绕双分支流程构建:一个分支用于估计各种归一化方法的统计量,另一个分支则计算样本特定的重要性比例以融合这些归一化后的特征图。
该框架的输入特征图为 X∈RN×C×H×W,其中 N、C、H 和 W 分别代表批次大小、通道数以及空间维度。第一阶段涉及估计小批量中 K 种归一化方法(例如批归一化、实例归一化、层归一化)各自的均值 μk 和标准差 δk。这些统计量统一记为 Ω={(μk,δk)}k=1K,随后用于对输入进行预归一化。具体而言,输入 X 通过平均池化进行下采样,生成 N×C 的特征矩阵 x。将每个 Ωk 应用于 x,得到 N×K×C 的张量 x^,随后通过一维卷积层处理,将其通道维度从 C 缩减至 C/r(r 为缩减率)。该步骤采用分组卷积实现,以保持参数量与 r 无关,最终生成中间表示 z。
EN 的核心创新在于计算样本特定的重要性比例 λnk。该过程分为三个步骤。首先,利用 z 张量计算每个样本不同归一器之间的成对相关性。对于第 n 个样本,矩阵 zn∈RK×C 与其转置 znT 相乘,形成 K×K 的相关性矩阵 vn=znznT。该矩阵捕捉了给定样本各归一化方法之间的相互依赖关系,提供了一种高阶特征表示,从而增强了模型对最优组合的推理能力。随后,将相关性矩阵 vn 展平为向量,并输入两层全连接(FC)网络。第一层 FC 网络将维度提升至 πK(实践中 π=50),接着使用 tanh 激活函数;第二层 FC 网络将维度降回 K。得到的向量 λn∈RK×1 代表第 n 个样本的重要性比例。应用 softmax 函数确保比例之和为一,即 ∑kλnk=1,最终归一化输出通过预归一化特征图的线性组合计算得出,其中包含每种归一化方法的可学习缩放参数 γk 和偏移参数 βk。
该架构通过避免直接组合均值和方差统计量(这可能引入偏差),并采用结构化、数据驱动的方法计算重要性比例,从而确保了优化过程的稳定性。比例计算模块的设计轻量级,额外参数主要存在于卷积层和全连接层中,与 SN 相比仅带来微小的计算成本增加。
实验
本文在多种视觉识别任务上评估了所提出的 EN 归一化方法,包括大规模与噪声图像分类、细粒度分类以及语义分割,以验证其准确性、鲁棒性及跨域泛化能力。在所有基准测试中,EN 均持续优于现有的归一化和基于注意力的技术,同时保持具有竞争力的计算成本。消融实验与动态比例分析进一步表明,该方法的自适应加权机制能够自动学习实例级和层级的归一化偏好,这些偏好随训练过程动态演变,直接推动了其卓越的性能。最终,EN 被证明是一种高效且通用的归一化策略,能够可靠地提升各类视觉任务中的模型准确率。
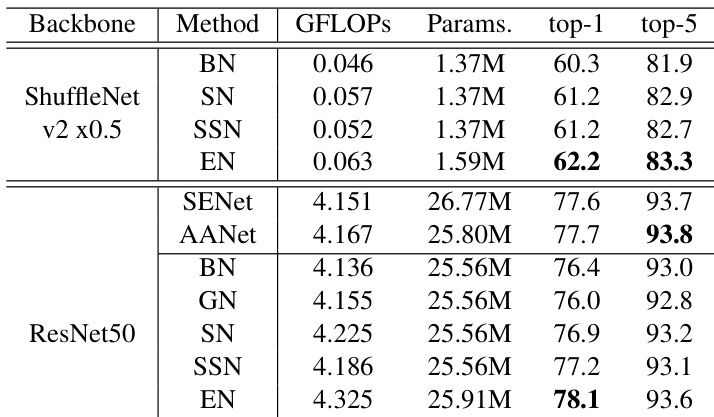
本文在 ImageNet 上使用不同的主干网络评估了 EN 方法,并将其性能与多种归一化技术进行对比。结果表明,EN 在保持具有竞争力的计算成本的同时,实现了更高的分类准确率。该方法在不同网络架构和任务中均展现出一致的性能提升。在 ImageNet 上,结合 ShuffleNet v2 和 ResNet50 主干网络,EN 的 top-1 和 top-5 准确率均优于其他归一化方法。EN 在分类准确率上超越了 SN 及其他方法,且计算成本仅小幅增加。EN 在不同主干网络及图像分类、语义分割等任务中均表现出一致的性能提升。
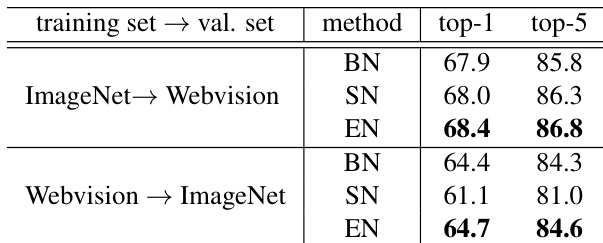
本文进行了跨数据集实验,以评估归一化方法在 ImageNet 和 Webvision 数据集之间的迁移能力。结果表明,所提出的 EN 方法在跨数据集测试的两个方向上均持续优于对比方法,展现了其鲁棒性与泛化能力。在不同训练集与验证集组合下,EN 在 top-1 和 top-5 准确率上均有显著提升。在 ImageNet 与 Webvision 的跨数据集测试中,EN 的准确率高于 SN 和 BN。当模型从 ImageNet 迁移至 Webvision 以及反向迁移时,EN 均保持了优越的性能。结果证明了 EN 在具有相同类别的不同数据集间具备强大的泛化能力。
{"summary": "本文在多个数据集和任务上评估了 EN 的性能,包括图像分类、噪声分类和语义分割。结果表明,EN 在保持具有竞争力的计算成本的同时,在准确率方面持续优于 SN 和其他归一化方法。消融研究进一步验证了 EN 的有效性,证明其设计选择对性能提升有所贡献。", "highlights": ["EN 在多个数据集和网络架构上的准确率均高于 SN。", "随着超参数 π 值的增加,EN 的性能有所提升,但模型对该参数的变化仍保持鲁棒性。", "与现有归一化方法相比,EN 在分类和语义分割等不同任务中均展现出一致的准确率提升。"]}

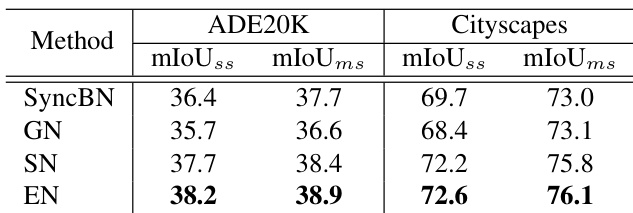
本文使用 ADE20K 和 Cityscapes 数据集在语义分割任务上评估了 EN 的性能,并与 SyncBN、GN 和 SN 进行对比。结果表明,在单尺度和多尺度测试条件下,EN 在两个数据集上的 mIoU 得分均高于其他方法。EN 的性能提升与其分类结果一致,证明了其泛化能力。在 ADE20K 和 Cityscapes 数据集的语义分割任务中,EN 均优于 SyncBN、GN 和 SN。在单尺度和多尺度测试条件下,EN 均获得了更高的 mIoU 得分。EN 的性能提升与其在图像分类任务中的结果保持一致。
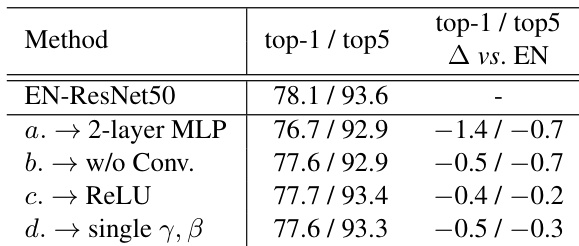
本文进行了消融实验,以评估所提出 EN 层中不同组件对分类性能的影响。结果表明,移除卷积操作或替换激活函数均会影响性能,而使用单组参数进行归一化会导致轻微下降。与所有变体相比,当前 EN 配置取得了最佳结果。移除 EN 层中的卷积操作会导致性能显著下降。将 Tanh 激活函数替换为 ReLU 可轻微提升性能。与完整 EN 配置相比,使用单组参数进行归一化会导致准确率小幅下降。
本文在图像分类、跨数据集迁移和语义分割任务上评估了所提出的 EN 归一化方法,以考察其准确性、计算效率和泛化能力。分类与跨数据集实验验证了 EN 持续超越现有归一化技术,同时保持具有竞争力的计算开销,展现了在不同架构和数据分布下的鲁棒性能。额外的消融研究证实了其特定架构组件的必要性,表明完整配置在表征能力与模型稳定性之间实现了最佳平衡。综合这些评估结果,EN 被确立为一种高效且可靠的归一化策略,能够在各类视觉识别基准测试中稳定泛化。