Command Palette
Search for a command to run...
既视感:用于序列推荐的上下文化时序注意力机制
既视感:用于序列推荐的上下文化时序注意力机制
Jibang Wu Renqin Cai Hongning Wang
ResNet 和带有注意力机制的 LSTM
摘要
基于用户历史中的序列行为预测其偏好,这对现代推荐系统而言极具挑战且至关重要。大多数现有的序列推荐算法主要关注序列动作之间的转移结构,但在建模历史事件对当前预测的影响时,往往忽略了时序和上下文信息。在本文中,我们认为过去事件对用户当前行为的影响应随时间推移及不同上下文而变化。因此,我们提出了一种上下文化时序注意力机制(Contextualized Temporal Attention Mechanism),该机制学习权衡历史动作的影响,不仅考虑“是什么”动作,还考虑“何时”以及“如何”发生的动作。更具体地说,为了动态校准来自自注意力机制的相对输入依赖,我们部署了多个参数化的核函数以学习不同的时序动态,然后利用上下文信息来决定每个输入应遵循哪种重加权核。在两个大型公共推荐数据集上的实证评估表明,我们的模型始终优于大量最先进的序列推荐方法。
一句话总结
Déjà vu 为序列推荐引入了上下文感知时序注意力机制。该机制通过参数化核函数动态加权历史交互,以捕捉随时间变化且依赖上下文的影响,并在两个大型公开数据集上持续优于最先进的序列推荐方法。
核心贡献
- 本文提出了一种用于序列推荐的上下文感知时序注意力机制,显式建模了历史用户行为受时间与上下文影响的特性。该方法摒弃了传统的以状态转移为中心的建模范式,转而采用一种基于具体时间节点与上下文条件动态加权历史交互的框架。
- 为校准自注意力依赖关系,该模型采用多种参数化核函数以捕捉多样化的时序动态。上下文信号随后为每个输入选择相应的重加权核,从而根据历史行为的时间与上下文属性自适应调整其影响权重。
- 在两个大型公开推荐数据集上的实证评估表明,所提框架持续优于大量最先进的序列推荐方法。这些结果验证了在基于注意力的序列建模中引入自适应时序与上下文加权的有效性。
引言
从历史交互序列中预测用户偏好是现代推荐系统面临的基础性挑战。尽管现有的序列推荐模型能够有效捕捉物品间的状态转移,但它们大多忽略了时序动态与上下文因素如何调节过去行为的真实影响力。先前的方法通常依赖静态的时间调整,难以应对稀疏的行为数据,或在处理多样化事件类型时缺乏扩展性。为弥补这些不足,研究团队采用了上下文感知时序注意力机制,利用参数化核函数动态重新校准历史影响力。通过依据上下文信号路由这些核函数,该模型能够根据时间节点与情境因素自适应地加权历史交互,从而在各项指标上持续超越当前基线方法。
数据集
- 数据集构成与来源: 研究团队利用两个公开数据集来捕捉不同应用领域中的用户行为:一个为专业社交平台,另一个为电子商务市场。
- XING 子集: 该数据源自 Recsys Challenge 2016 合集,用于追踪职位发布交互记录。每条记录包含用户 ID、物品 ID、时间戳及交互类型。研究团队排除了“删除”操作,并忽略了特定交互类别。通过设定热度阈值,移除了交互次数少于 50 次的物品,并将用户交互次数限制在 10 至 1,000 次之间。对于同一物品与相同操作类型且停留时间低于 10 秒的交互记录,同样予以剔除。
- UserBehavior 子集: 由阿里巴巴提供,该数据集包含具有相同元数据字段的商业产品交互记录。为确保计算可行性,研究团队随机采样了 100,000 条用户序列。过滤条件包括:移除交互次数少于 20 次的物品,将用户活动限制在 20 至 300 次之间,并剔除超出数据集原始 9 天时间窗口的交互记录。
- 处理与模型使用: 研究团队对两个子集进行清洗与结构化处理,将其转化为用于模型训练的序列交互记录。预处理流程重点强调时间约束、参与度阈值与停留时间验证,以消除噪声与低质量信号。尽管所给片段未明确具体的训练集与测试集划分比例或混合比率,但研究团队依赖这些过滤后的序列来训练和评估其深度学习架构,优先保障数据质量与可控的模型复杂度。
方法
所提出的上下文感知时序注意力机制(CTA)模型采用三阶段流水线,旨在为序列推荐捕捉内容、时序与上下文信息。该框架处理用户历史交互序列中的物品与时间戳对 {(ti,si)}i=1L,以及当前预测时间 tL+1。物品输入序列通过 Einput∈RN×din 映射至嵌入空间,得到 X=[s1,…,sL]⋅Einput∈RL×din。时间戳被转换为相对于预测时间的时间间隔,构成 T=[tL+1−t1,…,tL+1−tL]∈RL×1。随后,模型通过三个连续阶段处理这些输入:Mα、Mβ 和 Mγ,分别对内容、时序与上下文依赖关系进行建模。
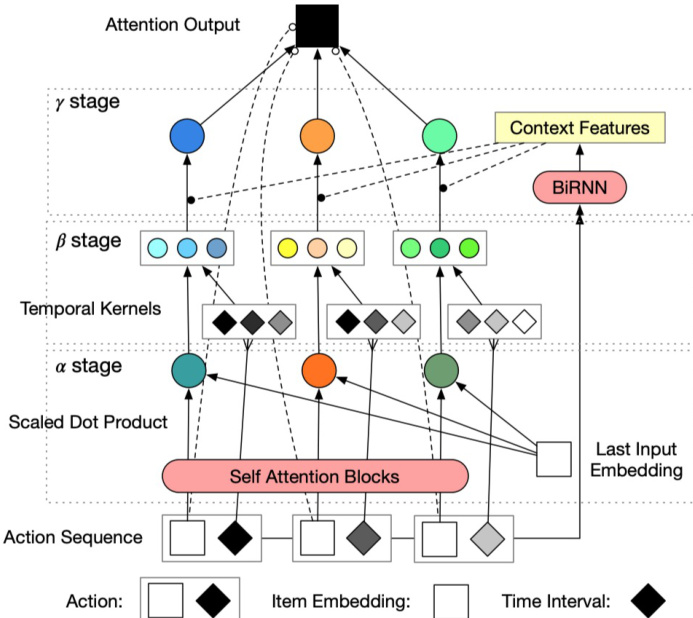
第一阶段为 α 阶段,专注于基于内容的重要性计算。该阶段利用包含 dh 个注意力头与 da 个隐藏单元的 dl 层自注意力编码器块来处理输入序列 X。每个注意力块通过缩放点积计算多头注意力,其中查询、键和值均由输入状态 Hj 通过可学习投影 WiQ,WiK,WiV 生成。生成的注意力头经拼接与投影形成 Zj,随后通过残差连接与层归一化与输入结合,输出下一层的隐藏状态 Hj+1。最终的隐藏状态 Hdl 用于计算基于内容的重要性得分 α。具体做法是在最后一层的隐藏状态与最后一个物品的嵌入向量之间执行缩放点积注意力,最终生成向量 α∈RL×1。
第二阶段为 β 阶段,用于建模时序动态。该阶段将一组 K 个核函数应用于时间间隔 T,以捕捉过去事件基于时间间隔的影响力。核函数包括指数衰减、对数衰减、线性衰减与常数函数,均由参数 a 和 b 进行参数化。这些核函数将原始时间间隔转化为 K 组时序重要性得分,构成 β∈RL×K,代表不同的潜在时序影响模式。
第三阶段为 γ 阶段,基于上下文线索融合内容与时序信息。该阶段首先利用双向循环神经网络(BiRNN)对输入物品序列 X 进行处理,提取上下文特征 C∈RL×dr。此举能够捕捉过去与未来动作所构成的周围事件上下文,反映用户对每次交互的敏感度与重视程度。可选地,额外的上下文特征 Cattr 可与 BiRNN 输出进行拼接。前馈层 FY 将上下文特征映射至 K 个时序核上的概率分布,并通过 Softmax 层进行归一化,得到 P(⋅∣C)∈RL×K。该分布用于混合 β 阶段的时序得分,生成上下文感知的时序影响力 βc=β⋅P(⋅∣C)。最终的上下文注意力得分 γ 通过对内容得分 α 与上下文时序得分 βc 进行逐元素相乘获得,随后执行 Softmax 归一化以确保权重之和为一。该加权求和结果用于计算预测物品表示 x^L+1,该表示被投影至输出嵌入空间,并与所有物品计算相似度得分以生成推荐结果。
实验
所提出的上下文感知时序注意力模型在两个大规模用户行为数据集上进行了评估,并与参数量匹配的多种基线模型进行对比,以建立公平的比较基础。整体性能与数据集特定分析验证了该模型有效弥合了一阶状态转移与序列热度模式之间的差距。通过集成三阶段加权机制,该模型优于专用架构。消融实验与架构测试进一步证实,共享物品嵌入、多核时序建模与动态内容评分是保障模型稳健性能的关键组件。最后,注意力可视化结果表明网络学习到了具有实际意义的非线性时序与上下文重加权机制,最终证明显式建模上下文感知的时序动态能够为序列推荐提供高精度、可解释且高效的解决方案。
研究团队在两个大型数据集上评估了所提出的上下文感知时序注意力机制,并与多种基线模型进行对比。结果表明,该模型在两个数据集上的 Recall@5 指标均全面超越所有基线模型。结果显示,该模型能够有效捕捉序列热度模式,尤其在 UserBehavior 数据集上表现显著,但在建模一阶状态转移模式时存在一定局限。性能提升主要归功于模型能够基于内容、时序影响力与上下文对历史事件进行加权,消融实验进一步证实了各组件的重要性。所提模型在两个数据集的 Recall@5 指标上显著优于所有基线方法,表明其在序列推荐任务中具有强大效能。该模型在呈现序列热度模式的 UserBehavior 数据集上表现尤为突出,且相比循环模型能更好地捕捉长期依赖关系。消融实验确认,融合内容、时序影响力与上下文的三阶段加权机制对提升模型性能至关重要。
研究团队在两个数据集上评估了所提出的上下文感知时序注意力机制(CTA)与多种基线模型。结果表明,CTA 在两个数据集上的 Recall@5 指标均全面超越所有基线模型。该模型在序列热度模式占主导的 UserBehavior 数据集上表现强劲,但在以第一阶状态转移模式为主的 XING 数据集上结果相对较弱。消融研究表明,模型的有效性依赖于其三阶段加权机制,其中时序影响力组件对于捕捉长期依赖关系尤为关键。CTA 在两个数据集上均取得最高的 Recall@5 成绩。相较于第一阶状态转移占主导的 XING 数据集,该模型在捕捉序列热度的 UserBehavior 数据集上表现更为出色。消融实验再次确认,时序影响力组件对模型有效性至关重要,尤其在长期依赖关系的捕捉方面。

研究团队开展消融实验,以分析所提模型中各组件的影响,重点关注不同架构选择及其在两个数据集上的性能表现。结果显示,模型性能随窗口大小、损失函数、注意力设置及不同时序核的使用而发生显著变化,表明设计选择具有任务依赖性,需要精细调优。该模型在捕捉上下文与时序影响力方面表现出良好的鲁棒性,特定配置可带来排名指标的显著提升。模型性能对窗口大小的选择较为敏感,最优设置会因数据集底层行为模式的不同而有所差异。采用基于排名的损失函数与特定时序核组合可显著提升推荐质量。该模型有效捕捉了上下文与时序影响力,其中综合重要性得分在判定事件相关性方面起主导作用。
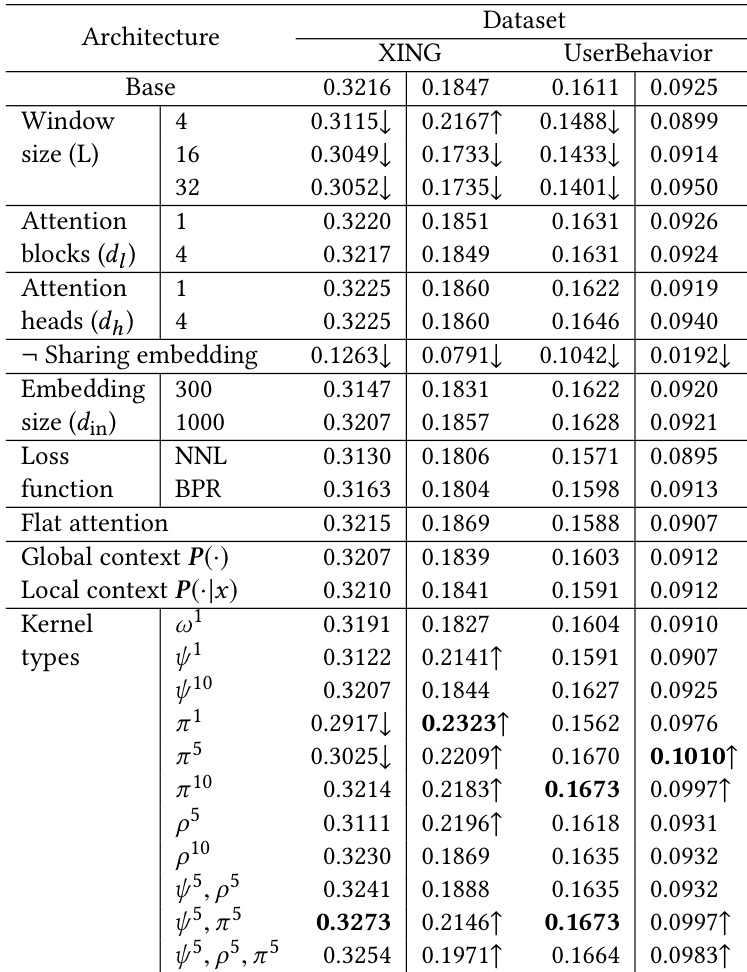
所提出的上下文感知时序注意力机制在两个数据集上与多种基线模型进行对比评估,以检验其在序列推荐任务中的整体效能。实验表明,该模型成功捕捉到了长期依赖关系与序列热度模式,但在第一阶状态转移模式占主导时存在一定局限。消融实验验证了融合内容、上下文与时序影响力的三阶段加权机制的必要性,其中时序加权对性能提升尤为关键。此外,结果表明模型效能对架构选择高度敏感,凸显了针对特定数据集调整窗口大小与损失函数的重要性。