Command Palette
Search for a command to run...
使用 Kaggle Titanic 数据集进行逻辑回归
摘要
一句话总结
作者提出了一种结合潜在因子模型与逻辑回归的引文网络模型,该模型通过带有惩罚项的凸联合似然函数捕捉主要技术趋势与特定依赖关系,从而实现低维潜在成分与稀疏图结构的高效估计,并通过仿真及实际统计学家引文网络的应用验证了该方法的有效性。
核心贡献
- 所提模型将潜在因子模型与逻辑回归相结合,共同捕捉引文网络中的主导技术趋势与稀疏的特定依赖关系。
- 参数估计采用带有惩罚项的凸联合似然目标函数,使得算法能够高效地约束低维潜在成分与稀疏图结构。
- 该方法通过仿真验证了其实用有效性,并应用于统计学家引文网络以报告结构发现。
引言
引文分析在评估学术影响力、指导资金分配以及绘制科学合作网络方面发挥着关键作用。传统的文献计量方法通常依赖原始引文数量或孤立的统计技术,难以捕捉研究社区的底层结构以及学术引用的概率特性。为克服这些局限,作者采用了一种结合潜在因子与逻辑回归的模型,直接对引文数据进行因子分析。这一统一方法同时揭示隐藏的学术主题并对引文概率进行建模,为分析学术影响力提供了更准确且更具可解释性的框架。
数据集

-
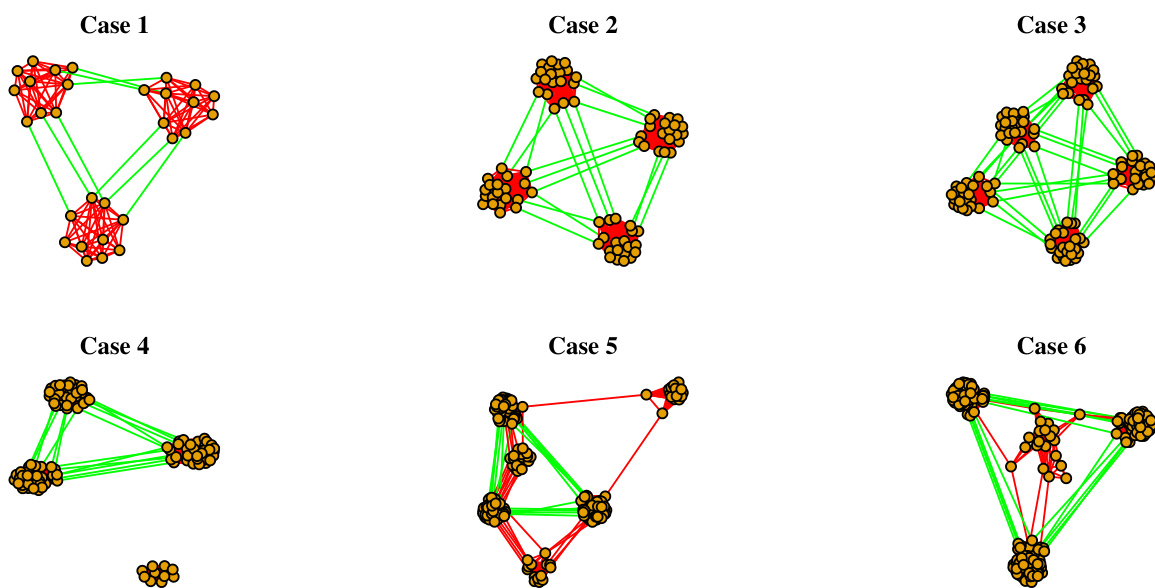
数据集构成与来源: 作者构建了一个完全合成的数据集,包含六个旨在模拟学术出版模式的引文网络。数据并非来源于真实存储库,而是通过算法生成,以便为测试网络推断模型提供可控的真实基准。
-
子集详情: 数据集分为两个实验场景,每个场景包含三个网络:
- 场景 1 包含分别具有 30、80 和 120 篇论文的网络,嵌入的主题数量分别为 3、4 和 5。这些子集中的所有论文均被分配至单一主题,主题簇之间分别通过 9、18 和 30 条特定依赖链接相连。
- 场景 2 包含 120、210 和 210 篇论文的网络,均以 3 个主题为核心结构。这些子集通过随机将两个或三个主题分配给受控的论文子集,同时保留其余论文的单一主题分配,从而引入主题混合。每个网络均保持恰好 18 条跨簇特定依赖链接。
-
数据用途与生成流程: 作者利用这些网络校准并评估用于网络重建的逻辑回归模型。不同于标准的训练集与测试集划分,这些合成图作为受控测试平台,真实基准参数按顺序初始化。截距项从均匀分布中采样以最小化人工边密度,而场景 2 中单主题与多主题论文的混合比例经过显式调整,用于测试模型区分共享潜在因子与直接引文的能力。
-
处理与元数据构建: 主题分配被编码于一个强制严格聚类的二元因子载荷矩阵中,因子权重从均匀分布中抽取以维持组内凝聚力。跨簇引文通过随机配对不同主题的节点生成,连接概率通过结合截距、主题因子与权重的逻辑函数计算得出。生成的上三角邻接矩阵通过伯努利试验填充,并进行对称化处理以形成最终无向图。在最终网络组装前,还对因子矩阵应用了中心化变换以标准化底层主题结构。
方法
所提模型将潜在因子模型与逻辑回归框架相结合以分析引文网络,解决了单独使用任一方法时固有的局限性。该框架旨在同时捕捉网络中的全局结构趋势与局部特定依赖关系。其核心假设是,表示 n 个节点间引文关系的二元邻接矩阵 X 源于两个成分的组合:低秩潜在结构与稀疏残差结构。潜在成分通过因子分析方法进行建模,其中每个节点通过因子载荷矩阵 F∈RK×n 与一组底层主题(因子)相关联,这些主题的影响由对角矩阵 D∈RK×K 进行加权。由此产生的交互项 FTDF 捕捉了网络中的主要技术趋势。同时,引入稀疏矩阵 S∈Rn×n 对节点间非基于因子的直接依赖关系进行建模,有效表示特定引文链接。观测网络的联合概率被表述为逻辑回归模型,其中节点 i 与 j 之间发生引文的对数几率由全局截距 α、潜在因子交互项 fiTDfj 与特定项 Sij 之和给出。
估计过程始于定义一个惩罚对数似然函数,该函数将观测数据的似然与正则化项相结合,以促进估计成分具备期望的属性。经过适当变换后,对数似然函数以参数 α、低秩矩阵 L=FTDF 以及稀疏矩阵 S 表示。为确保可识别性与计算可行性,潜在矩阵 L 被视为一般低秩矩阵,而非显式分解为 F 与 D。随后在惩罚项约束下最小化目标函数:对 S 施加 L1 范数以强制稀疏性,对 L 施加核范数以促进低秩特性。该公式化表述导出了一个凸优化问题,从而允许开发高效算法。目标函数的凸性由逻辑损失函数的凸性与正则化项的凸性共同保证。
优化过程采用交替方向乘子法(ADMM)执行,该技术非常适合处理具有结构化凸目标的问题。该方法将问题分解为可通过迭代求解的更简单子问题。目标函数中 α、L 与 S 的线性项支持高效更新,而逻辑损失函数的凸性确保了收敛性。ADMM 框架通过增广拉格朗日技术有效处理非平滑的 L1 与核范数惩罚项。算法迭代更新 α、L 与 S 的估计值,由于整体目标函数具有凸性,该方法的收敛性得到保证。所得估计量 α、L 与 S 将网络结构分解为捕捉主要技术趋势的低秩成分与捕捉其余更具体依赖关系的稀疏成分。估计值 L 的秩作为底层主题数量的估计,而 S 中的非零元素揭示了特定连接。在标准假设下确立了模型的理论性质(包括非渐近误差界),从而保证估计量的一致性。
实验
实验评估通过对合成图结构及实际统计学家引文网络进行受控测试,检验了所提方法的有效性。这些设置验证了模型在不同数据复杂度下的结构准确性与实际适用性。结果表明该方法在两种场景中均表现稳定,证实了其鲁棒性,以及适用于理论分析与实际网络应用。
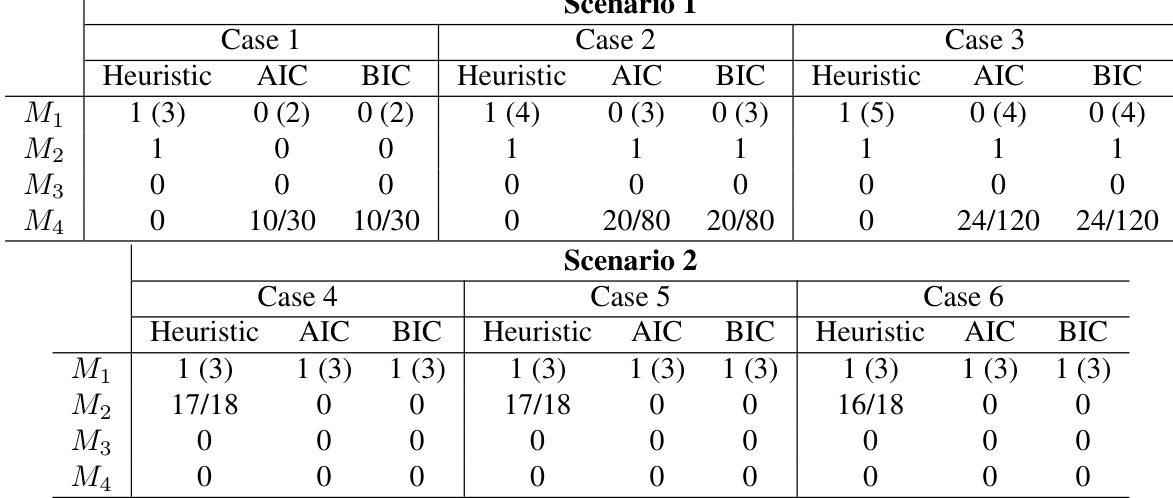
作者展示了合成网络场景的实验结果,对比了多种情况下不同的模型选择方法。下表显示了启发式方法、AIC 与 BIC 准则在选择模型时的不同表现,某些方法在特定场景中持续优于其他方法。启发式方法在各种案例中表现强劲,常能选出正确模型。在大多数场景中,AIC 与 BIC 准则的成功率低于启发式方法。不同案例间的性能差异显著,表明其对底层网络结构具有敏感性。
作者在不同合成网络场景中评估了模型选择方法,以确定启发式方法、AIC 与 BIC 准则识别正确底层结构的有效性。结果表明,启发式方法持续优于 AIC 与 BIC,后者在多数测试案例中成功率明显偏低。最终,实验揭示选择准确率高度依赖于具体的网络拓扑结构,从而确立启发式方法在不同条件下最为可靠。