Command Palette
Search for a command to run...
一种形态句法信息增强的LSTM-CRF命名实体识别模型
一种形态句法信息增强的LSTM-CRF命名实体识别模型
Lilia Simeonova Kiril Simov Petya Osenova Preslav Nakov
使用 astroBERT 进行命名实体识别(NER)预测
摘要
我们提出了一种用于命名实体识别的形态信息增强模型,该模型基于LSTM-CRF架构,结合了词嵌入、双向LSTM字符嵌入、词性(POS)标签和形态信息。以往的工作主要侧重于仅使用词嵌入和字符嵌入从原始词输入中学习,而我们表明,对于保加利亚语等形态丰富的语言,获取词性信息对性能提升的贡献大于详细的形态信息。因此,我们证明命名实体识别仅需粗粒度的词性标签,但同时利用不同粒度的部分词性信息也能带来收益。在标准数据集上的评估结果表明,该模型在保加利亚语命名实体识别任务上相较于最先进方法取得了显著的性能提升。
一句话总结
本文提出了一种融合形态句法信息的 LSTM-CRF 命名实体识别模型,该模型整合了词向量、字符特征与多粒度词性标签,证明了对于形态丰富的语言而言,粗粒度句法线索优于详细的形态特征,并在保加利亚语 NER 基准测试中实现了最先进的性能提升。
核心贡献
- 本研究提出了一种形态感知 LSTM-CRF 命名实体识别架构,整合词向量、双向 LSTM 字符嵌入、词性标签及形态特征,以弥补复杂词形中的信息缺失。
- 系统性分析表明,词性标注带来的性能提升高于详细的形态信息,证明粗粒度标签结合不同粒度层级能有效增强实体识别效果。
- 在标准保加利亚语数据集上的评估显示,该模型较现有最先进模型有显著改进,同时公开的数据集与源代码为未来研究提供了直接对比的基础。
引言
命名实体识别是问答、信息抽取与对话 AI 等广泛自然语言处理应用的关键预处理步骤。尽管历经数十年研究,该任务仍具挑战性,主要受限于海量非结构化数据及专有名词的语言学复杂性。早期系统依赖易出错的规则与统计模型,而近期的深度学习方案如 Bi-LSTM-CRF 架构在英语任务上取得了显著成果。然而,现代模型在处理形态丰富的语言时面临困难,因为标准词向量无法捕获解析大量屈折词形所需的语法上下文。为填补这一空白,本文利用词性标签与形态标注作为 LSTM-CRF 网络的直接输入。这种融合形态句法信息的设计在保加利亚语 NER 任务上较现有基线模型实现了显著的性能提升,并完整公开了数据集与代码,以规范未来的评估工作。
数据集
- 数据集构成与来源: 本文采用源自人工标注的 BulTreeBank 的保加利亚语语料库。该语料库将 BIO 格式的命名实体标注与位置形态句法标签相结合。
- 子集详情: 数据被划分为三个互斥集合:训练集、验证集与测试集。原文未提供精确的 token 数量,但指出存在显著的类别不平衡现象,且人物实体高度集中。准备过程中未应用明确的过滤规则。
- 数据使用与处理: 该数据集用于训练命名实体识别模型。为防止因类别分布倾斜导致的过拟合,本文采用了早停策略。工作流程不涉及数据混合比例或裁剪策略。
- 元数据与标注处理: 命名实体使用源自句法成分边界的九个 BIO 标签(B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, B-MISC, I-MISC, O)进行编码。每个 token 继承 BulTreeBank 标签集中的位置形态句法标签,这些标签捕获了词性与语法特征,有助于分析形态如何影响 NER 性能。
方法
本文基于 Lample 等人(2016)提出的基础模型,采用改进的 Bi-LSTM-CRF 架构来解决保加利亚语等形态丰富语言的命名实体识别问题。核心框架通过首先构建整合多源信息的综合输入向量来处理句子中的每个词。该输入向量由词向量、字符级嵌入以及编码形态句法特征的语法向量拼接而成。词向量源自预训练的 FastText 向量,其通过字符 n-gram 建模捕获语义信息,并能有效处理未登录词。字符级嵌入通过对每个词的字符运行双向 LSTM 生成,捕获对建模形态变化至关重要的前缀与后缀信息。
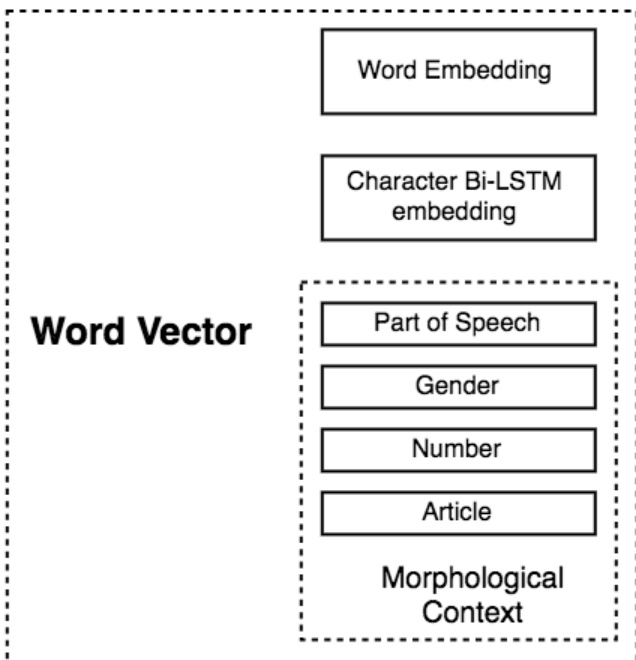
如图所示,语法向量由多个组件构成,包括词性(POS)标签以及性别、数和定指性等形态特征,这些特征均以 one-hot 向量表示。词性标签用于将词分类为名词、形容词、动词等类别,并被视为粗粒度特征。形态特征主要适用于名词、形容词、代词及混合标签,其中性别包含三个值,数包含四个值,定指性包含四个值(含单数阳性名词的特定形式)。这些特征拼接后形成综合词向量,从而丰富输入表示。
构建好的词向量随后输入至双向 LSTM 层,该层捕获每个词左右上下文的上下文信息。前向与后向 LSTM 的输出拼接后形成上下文感知的词表示。该表示经过全连接层处理,为每个可能的命名实体标签生成得分。最后,应用 CRF 解码器确定最优标签序列,确保标注的全局一致性。为缓解过拟合,训练过程中对词向量应用 dropout 层,以指定概率随机排除隐藏单元。该方法将词向量与字符嵌入自动学习的特征同手工构建的语法特征相结合,以提升形态复杂语言的性能。
实验
本研究评估了用于保加利亚语词性标注与命名实体识别的 Bi-LSTM-CRF 架构,利用上下文嵌入与线性链 CRF 解码器验证增强形态特征与 POS 标签的影响。随后的错误分析实验验证了模型在借词与外来名上的表现,表明在基础网络难以处理非典型语言结构时,POS 标签能显著提升解析准确率。尽管补充词典与脚本检测特征带来的增益有限,但研究结果证实上下文标注能有效缓解实体歧义,并展示了模型应对保加利亚语复杂词汇挑战的鲁棒性。
本文展示了一系列针对保加利亚语 POS 标注的不同模型配置对比实验,结果表明逐步添加字符级信息、POS 标签与形态特征可持续提升性能。最优模型融合了多种特征类型,取得了最高的 F1 分数。在模型中添加字符级信息的效果优于仅使用词级特征。引入 POS 标签与形态特征进一步提升了模型性能。表现最佳的模型融合了多种特征类型,相较于其他配置取得了最高的 F1 分数。

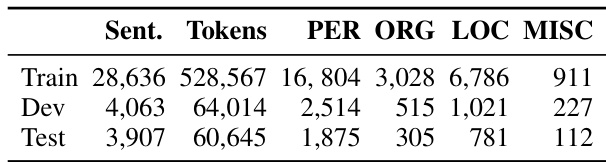
本文展示了保加利亚语 NER 任务的数据集划分,按实体类型详细列出了训练集、验证集与测试集的句子与 token 数量。数据分布显示显著的不平衡性,训练集包含绝大多数 token 与句子,而测试集规模较小且在实体类别上分布更为均衡。训练集在句子数量与 token 数量上均显著大于验证集与测试集。不同实体类型的 token 数量差异显著,部分类型的 token 数量远超其他类型。相较于训练集,测试集在各实体类型上的 token 分布更为均衡。
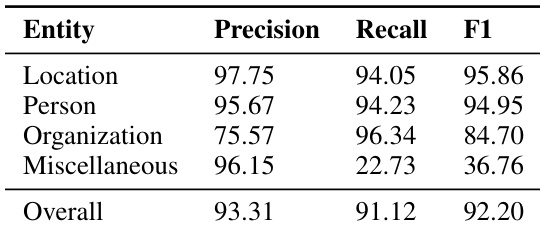
本文评估了模型在命名实体识别任务上的表现,列出了不同实体类型的精确率、召回率与 F1 分数。结果表明模型在地点与人物实体上表现强劲,而在机构与杂项类别上表现较弱,尤其在召回率与 F1 指标上。模型在地点与人物实体上取得了较高的精确率与召回率。机构与杂项实体的性能明显较低,尤其是召回率与 F1 分数。总体指标反映了性能权衡,部分实体得分较高,而其他实体则存在明显短板。
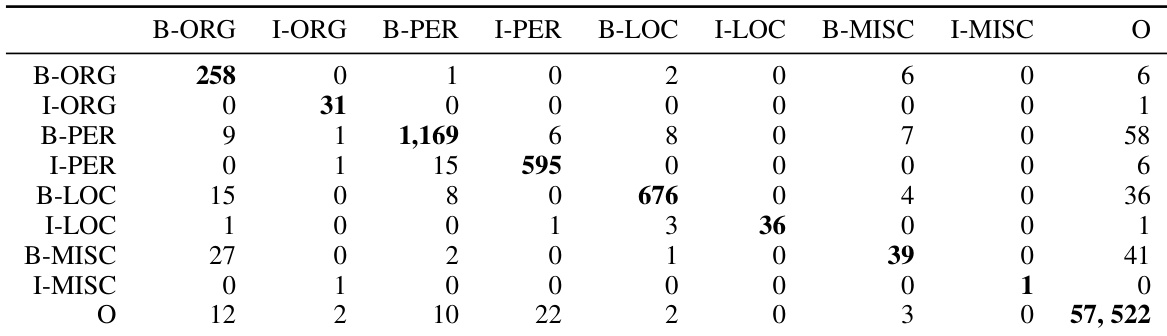
本文展示了最优模型在测试集上的混淆矩阵,呈现了命名实体识别中预测标签与真实标签的分布情况。结果表明部分标签间存在显著误分类,特别是 B-PER 与 B-LOC 常与 O 标签混淆,B-LOC 与 B-ORG 之间也存在混淆,这暗示区分名称重叠实体存在挑战。模型常将 B-PER 与 B-LOC 标签误判为 O,表明其在处理名字与地名时存在困难。B-LOC 与 B-ORG 标签间存在明显混淆,可能源于地点与机构名称的重叠。O 标签在对角线上数值较高,反映了模型对非实体词的处理能力较强。
本文将其模型与先前工作的基线模型进行对比,结果显示性能有所提升。结果表明,所提模型相较于以往的最先进方法取得了更高的 F1 分数。所提模型在 F1 分数上优于基线模型。这一提升表明该方法较以往方案能提供更优的结果。相较于先前研究,该模型在评估任务上实现了更高的性能。

该评估通过特征消融实验、数据集分布分析以及与先前最先进方法的对比基准测试,检验了保加利亚语词性标注与命名实体识别的效果。实验验证了逐步引入字符级细节、句法标签与形态属性能显著提升标注准确率,其中多特征配置效果最佳。在命名实体识别方面,模型对地点与人物实体表现出稳健的处理能力,但在机构与杂项类别上面临挑战,这主要源于命名惯例的重叠以及与非实体标签的频繁误分类。总体而言,所提架构持续超越以往基线,证实了全面特征整合与任务特定设计能够带来更优越的语言解析能力。