Command Palette
Search for a command to run...
通过机器学习对答案候选者进行重排序以增量提升问答系统
通过机器学习对答案候选者进行重排序以增量提升问答系统
Michael Barz Daniel Sonntag
候选人重新排名模型
摘要
我们实现了一种方法,用于对最先进的问答(QA)系统的Top-10结果进行重排序。我们的重排序方法的目的是在给定用户问题和Top-10个候选答案的情况下,提高答案选择的准确性。我们专注于改进已部署的问答系统,这些系统不允许重新训练,或者重新训练成本高昂。我们的重排序方法利用基于n-gram的特征学习一个相似度函数,将查询、答案和初始系统置信度作为输入。我们的贡献包括:(1) 我们从奥地利T-Mobile客户关怀领域的877个答案出发,生成了一个QA训练语料库;(2) 我们使用神经网络句子嵌入实现了一个最先进的QA流水线,该嵌入将查询编码到与答案索引相同的空间中;(3) 我们使用单独提供的测试集评估了QA流水线和我们的重排序方法。该测试集可被视为在系统部署后可用,例如基于用户反馈。我们的结果表明,系统在Top-n准确率和平均倒数排名(MRR)方面的性能因使用梯度提升回归树进行重排序而得到提升。平均而言,平均倒数排名提高了9.15%。
一句话总结
通过基于查询、答案与初始置信度得分的 n-gram 特征训练梯度提升回归树,本研究证明了在对已部署问答系统的前 10 名候选结果进行重排序后,在 T-Mobile Austria 客服数据集上平均互惠排名(Mean Reciprocal Rank)提升了 9.15%,且无需进行昂贵的模型重新训练。
核心贡献
- 从 T-Mobile Austria 客服领域构建了一个包含 877 对问答的专用训练语料库,以支持基于检索的问答系统。
- 提出了一种部署后重排序算法,该算法利用梯度提升回归树,从查询、候选答案与初始置信度得分的 n-gram 特征中学习相似度函数。
- 在源自真实用户聊天记录的数据集上进行的评估表明,重排序步骤提升了检索性能,在无需重新训练基础模型的情况下,使平均互惠排名平均提升了 9.15%。
引言
作者解决了在工业客服环境中逐步优化已部署问答系统所面临的挑战,其中有效管理长尾高频查询直接影响服务可靠性。尽管先前方法依赖于知识库维护、自反思元模型或人工参与的众包,但这些方法通常需要大规模架构修改或持续的外部监督,难以集成到实时生产流水线中。为克服这些限制,作者引入了一种轻量级的部署后重排序模块,该模块应用基于 n-gram 的相似度模型对现有检索系统的候选答案进行重新排序。该方法实现了问答流水线的自动化与反馈驱动式适配,证明了定向重排序能够在不破坏现有工作流程或无需完整模型重新训练的情况下,显著提升答案选择质量。
数据集
- 数据集构成与来源: 作者构建了两个匿名化语料库,分别来源于内部客服记录与实际聊天记录。
- 子集详情: 训练集包含 877 条客服答案,并配对了 3,338 个提取出的关键词或关键短语。研究人员在此基础上进行数据增强,为每条答案添加两个自然示例查询,最终生成 5,092 条查询。团队通过组合关键词与不同数量的样本,创建了三个训练版本:仅关键词(3,338 项)、关键词加一个用户样本(4,215 项)以及关键词加两个用户样本(5,092 项)。评估集包含来自 T-Mobile Austria 聊天记录的 3,084 条真实用户请求,领域专家手动将每条查询映射至最多三条相关的训练答案。
- 数据使用与处理: 在训练阶段,作者将组合后的问题与关键词作为输入,对应答案作为输出,并在所有三个语料库版本上进行测试。评估语料库用于测量基准问答流水线性能,并通过交叉验证验证重排序方法,将专家映射结果作为离线人工反馈。为应对聊天记录中高频出现的拼写错误,流水线集成了自定义的拼写检查组件。
- 额外处理与元数据: 两个语料库在使用前均经过完整匿名化处理。训练数据依赖关键词与关键短语标签作为结构元数据,该增强策略设计为可通过众包实现扩展,以便未来在生产环境中部署。
方法
作者采用两阶段架构来优化问答(QA)系统,初始问答流水线生成前 10 名候选答案的排序列表,随后通过重排序流程进行优化。整体框架将基准问答系统与后处理重排序模块相结合,后者作用于初始系统的输出。如框架图所示,基准问答系统以用户问题为起点,首先经过旨在纠正常见拼写错误的拼写检查模块。随后进入预处理阶段,为特征编码准备查询,具体步骤因底层流水线而异。对于 spacy_sklearn 流水线,使用 Spacy 的德语语言模型进行分词与文档生成,特征编码由预训练词嵌入的平均值导出。相比之下,tensorflow_embedding 流水线采用简单的空白字符分词器,并使用 Scikit-learn 的 CountVectorizer 生成词袋表示。两个流水线均进入文本分类阶段,其中 spacy_sklearn 流水线使用支持向量分类器(SVC),而 tensorflow_embedding 流水线采用基于 StarSpace 的嵌入模型来学习查询与答案表示。分类输出置信度得分,用于对前 10 名答案进行排序。

完成初始排序后,重排序模块以前 10 名结果及其置信度得分为输入。如下方图示,重排序模型通过学习和评估用户问题与每个候选答案之间对齐程度的相似度函数来运作,同时纳入答案文本与初始置信度得分。该模型在人工标注数据上进行训练,这些数据提供了源自人工反馈的理想排序,使其能够学习更精确的排序函数。重排序算法通过计算基于查询和答案中提取的 n-gram 特征(包括一元、二元和三元语法)的相似度得分来处理每个候选项。三种距离指标被用作特征:Jaccard 距离、余弦相似度以及 n-gram 匹配数量。这些特征被输入梯度提升回归树,以预测每个候选项的优化置信度得分。最终排序通过按降序排列候选项的重排序得分获得。该方法使系统能够在无需重新训练初始问答模型的情况下,提升头部结果的排序质量。
实验
基准评估测试了多种问答流水线配置与训练语料库,为后续实验奠定坚实基础,最终选定经过拼写检查与用户注释增强的 TensorFlow 嵌入模型。随后,重排序评估通过交叉验证验证了辅助排序模型是否能通过重新排序初始前 10 名候选项来提升系统的部署性能。定性结果表明,尽管重排序方法持续提升了排序准确率与互惠排名,但由于特征较为简单且仅能在已排序结果范围内操作,整体提升幅度较为有限。因此,本研究得出结论:重排序为现有问答系统提供了一种可行但渐进式的优化方案,并强调需要先进的特征工程、用于错误检测的元模型以及主动学习策略,以实现更显著的性能突破。
作者通过对比基准性能与重排序方法对问答系统进行评估,结果显示应用重排序后大多数指标均呈现稳定提升。重排序方法提升了 top-1 至 top-9 的准确率与平均互惠排名,排名越高收益逐渐递减,而 top-10 准确率保持不变,这是由于仅从前 10 名候选项中进行选择所致。与基准相比,重排序提升了 top-1 至 top-9 的准确率与平均互惠排名。随着排名上升,提升幅度逐渐减弱,top-10 准确率未见增长。重排序方法局限于前 10 名候选集内运作,限制了其在现有结果之外进一步优化的能力。
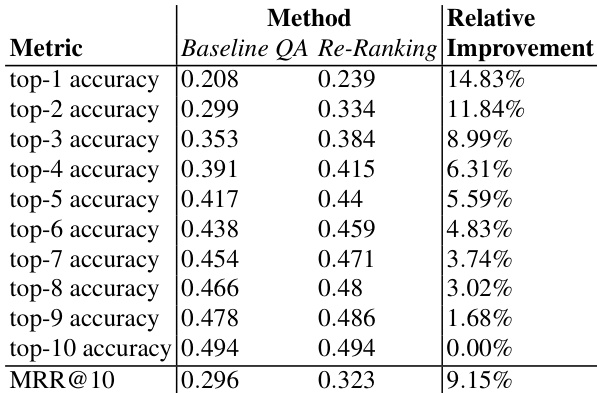
作者评估了不同配置的问答流水线,重点关注训练数据、拼写检查与模型架构对准确率及平均互惠排名等性能指标的影响。采用拼写检查与 100 个训练轮次的 tensorflow embedding 流水线取得了最佳结果,被选为重排序实验的基准。重排序方法持续提升整体性能,尤其在 top-1 准确率方面效果显著,但随着排名上升收益递减,且受限于候选集规模,提升幅度有限。在各类流水线配置中,增加用户注释与使用拼写检查均能提升性能。tensorflow embedding 流水线的表现优于 spacy sklearn 流水线,尤其在配合拼写检查与合理训练轮次时更为明显。重排序提升了 top-1 准确率与平均互惠排名,但对较高排名的改善有限,且无法突破前 10 名候选集的边界。
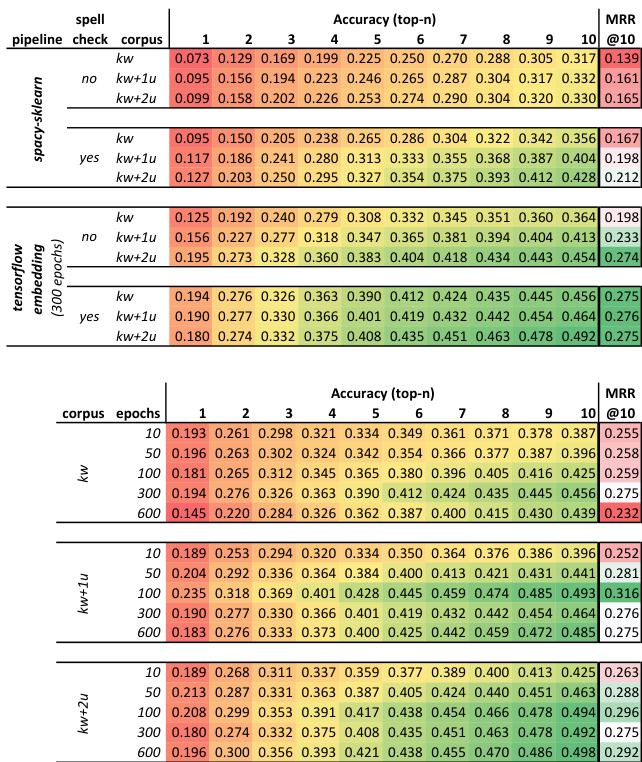
实验通过测试多种流水线配置来评估问答系统,涵盖不同的嵌入架构、拼写检查集成、训练轮次与用户注释,并辅以应用于头部候选结果的重排序策略。配置测试验证了基于 TensorFlow 的流水线持续优于 SpaCy 替代方案,尤其是在结合拼写检查与充足训练数据时。重排序评估确认,对初始候选集进行后处理能有效提升头部答案的准确率,尽管受限于固定的选择边界,其影响在较深排名处自然趋于平稳。总体而言,研究结果表明,将稳健的基础模型与定向优化步骤相结合,能够带来最可靠的问答性能。
作者评估了不同配置与训练语料库下问答流水线的性能,重点分析准确率与平均互惠排名指标。结果表明,引入用户注释与拼写检查可提升系统性能,且 tensorflow embedding 流水线的表现优于 spacy sklearn 流水线。对前 10 名结果进行重排序持续提升了准确率与 MRR,但排名越高收益越低。用户注释与拼写检查的引入同时改善了两种基准流水线的性能。在所有配置下,tensorflow embedding 流水线均稳定优于 spacy sklearn 流水线。重排序前 10 名结果提升了准确率与 MRR,其中较低排名处的提升幅度最为显著。