Command Palette
Search for a command to run...
如何使用数据框架 (DataFrames)
摘要
一句话总结
作者提出用主流列式数据框(dataframe)替换传统事件日志结构,以提升流程挖掘的可扩展性,并详细阐述了在主流工作站上高效处理真实世界事件数据所需的算法适配与计算复杂度分析。
核心贡献
- 本文引入了数据框结构的正式抽象与实现,以替换传统的内存事件日志表示,支持直接从 Apache Parquet 和 Apache ORC 等列式存储格式中读取数据,从而突破标准工作站上的可扩展性瓶颈。
- 文中展示了针对过滤和直接后继图(Directly-Follows Graph)计算所适配的流程挖掘算法,并附带了形式化的复杂度估算,证明了数据框架构如何优化内存访问并加速日志探索。
- 在真实世界与模拟事件日志上的实证评估表明,所提出的基于数据框的方法能够以高效的执行时间和合理的内存占用处理大规模数据,验证了其在主流流程挖掘工作负载中的适用性。
引言
流程挖掘使组织能够从信息系统生成的事件数据中提取可操作的洞察,支持瓶颈检测与流程发现等关键分析。然而,事件日志的指数级增长暴露了现有框架的重大瓶颈:这些框架通常优先保证分析精度而非执行速度与内存效率,导致在标准工作站上进行大规模分析变得不切实际。为解决这一问题,作者利用列式存储格式与数据框结构来替代传统的事件日志表示。他们形式化了一种专为流程挖掘定制的数据框抽象,将核心算法适配至该新结构,并通过复杂度分析与实证测试证明,该方法在不牺牲分析能力的前提下,显著提升了计算性能与内存管理效率。
数据集

-
数据集构成与来源: 该数据集由符合 IEEE XES 标准格式的事件日志组成。这些日志作为流程挖掘的基础输入,来源于广泛使用的框架与商业工具,包括 ProM6、PM4Py、Disco、ProcessGold、Celonis 和 QPR。
-
子集详情与结构: 数据并非按固定的训练分区组织,而是根据分析需求围绕两种处理配置进行安排。部分加载仅提取案例标识符与活动名称,这足以满足大多数发现与一致性算法的需求。完整加载则保留所有可用属性,以支持详细的日志探索与行为过滤。数据集本身包含部分属性,意味着并非每个事件都包含所有注册字段的值。
-
数据使用与处理: 作者将这些日志视为形式化流程挖掘分析的起点。他们定义了一种经典的事件日志结构,将案例标识符映射至事件集合,事件映射至活动,事件映射至部分属性函数。随后,该结构化数据被转换为直接后继图(Directly Follows Graph),其中节点代表活动,带权边记录活动直接后继的频率。该工作流还提及与 Apache Hadoop 和 Spark 等大数据架构的集成,以处理大规模事件集合。
-
额外处理策略: 该处理流水线强调选择性属性加载以优化内存使用与计算。在构建图之后,作者将直接后继图转换为 Petri 网,以支持高级一致性检查。该数据处理方法还支持关系型数据库实现与分布式 MapReduce 架构,确保处理流水线在不同流程挖掘工作负载中保持可扩展性。
方法
作者采用基于数据框的方法来增强流程挖掘操作的可扩展性,其基础是 Apache Parquet 和 Apache ORC 等列式存储格式。该框架旨在通过利用列式存储的优势以及数据框实现中提供的结构化操作,高效处理大规模事件日志。该方法论的核心在于数据框结构的抽象与实现,相较于传统的基于行或基于 XES 的事件日志表示,它能够实现更优化的数据访问与操作。
数据框模型被形式化定义为一个元组 D=(I,N,T,V,χival,χtype),其中 I 表示事件索引集合,N 为属性名称集合,T 为属性类型集合,V 为可能值集合。函数 χival 将每个事件索引与属性名称映射至对应值,而 χtype 为每个属性分配类型。一个关键假设是存在案例与活动属性,确保每个事件均可唯一标识且包含已定义的活动。该抽象实现了一种灵活且高效的事件日志表示,支持广泛的流程挖掘操作。

框架图示展示了数据框结构,其中列对应属性名称,行代表事件。数据框抽象被实现为一个简单数据结构:Map<String, ArrayList<Object>>,其中每个键为属性名称,关联值为所有事件的属性值列表。该结构允许在 O(1) 时间内高效检索给定属性的所有值,相较于依赖哈希表进行属性访问的传统事件日志表示,能够实现更快的操作。将事件日志 L=(CI,E,A,case_ev,act,attr,≤) 转换为数据框 D 的过程包括将事件序列映射为索引,并用属性值填充数据框,缺失值表示为 ϵ。该转换假设事件之间存在全序关系,确保事件位置与数据框索引之间的映射保持一致。
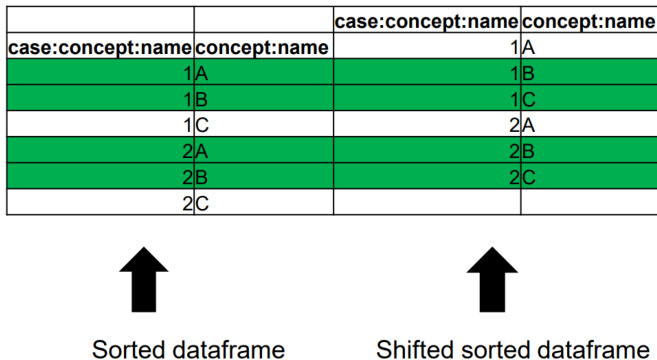
为支持流程挖掘任务,作者定义了一套作用于数据框的转换函数,包括投影、分组、移位、拼接、排序与字符串合并。投影函数根据属性值与选择函数 f 过滤事件;分组函数按指定属性划分数据框,生成不相交的子集。移位函数通过递减索引对齐事件,这对计算直接后继关系至关重要。拼接允许合并具有不同属性集的两个数据框,并通过分隔符确保属性名称的唯一性。排序根据指定属性重新排列事件,字符串合并则使用分隔符将两个属性组合为新属性。这些函数支持在数据框之上构建复杂工作流,从而促进过滤与直接后继图计算等操作。
本文在与经典事件日志实现的对比中分析了数据框操作的复杂度。过滤是流程挖掘中的常见操作,由于属性值支持常数时间访问,数据框的最坏情况复杂度为 O(N)(N 为事件数量)。相比之下,经典事件日志因哈希表访问在最坏情况下表现出更高的复杂度。数据框上直接后继图(DFG)的计算可通过两种方法实现:Map-Reduce 与移位计数。Map-Reduce 方法保持 O(N) 的平均复杂度,而移位计数方法需先按案例标识符对数据框排序(产生 O(NlogN) 复杂度),随后进行线性操作。两种方法的最坏情况复杂度均为 O(N2),源于边计数映射中的冲突。作者证明,数据框与列式存储结合后,在处理大规模事件日志方面具有显著优势,主要体现在高效的属性访问与优化的操作上。
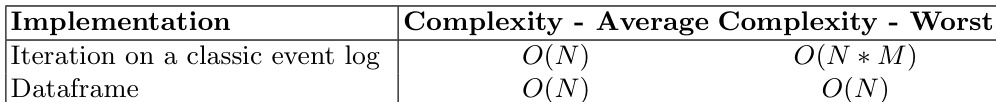
实验
该评估利用 PM4Py 库,在真实世界与合成事件日志上测试了使用 Parquet 列式存储的 Pandas 数据框在流程挖掘任务中的性能。这些实验通过测量加载时间、内存消耗以及数据过滤与依赖图生成的处理速度,验证了系统的计算效率。定性结果表明,列式数据框实现能够有效处理包含数百万事件的大规模日志,展现出对现代流程挖掘工作流的强适配性。最终,研究结果证实,列式格式在管理当代事件数据方面具有显著优势,同时在标准硬件上保持稳健的性能。
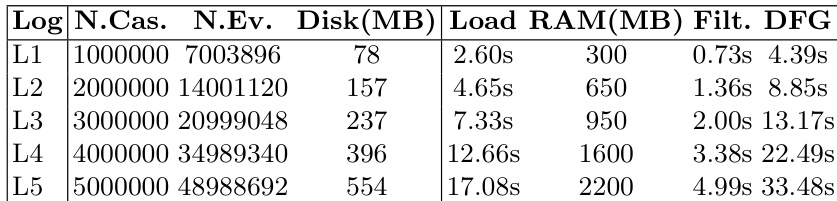
作者评估了使用列式存储格式的数据框实现在实际与合成事件日志上的性能。结果表明,数据框能够高效处理大规模事件日志,在磁盘占用、加载时间、内存使用及常见操作的处理速度方面均具优势。数据框可高效处理多达 250 万事件的实际日志,并在磁盘空间与内存使用上表现优异。列式存储格式提升了大型事件日志的加载速度并降低了内存需求。在使用列式格式的数据框时,过滤与 DFG 计算等操作速度更快。

作者评估了使用列式存储格式的数据框实现在实际事件日志上的性能,重点关注磁盘大小、加载时间、内存使用、过滤效率及 DFG 计算时间。结果表明,数据框能够有效管理大规模事件日志,在采用列式格式与选择性属性加载时,存储与计算效率得到显著提升。实验在不同日志类型与规模下均展现出一致的性能增益,凸显了列式存储对流程挖掘任务的益处。使用列式存储的数据框相比传统格式减少了磁盘占用与内存使用。仅加载相关属性时,加载与过滤时间显著缩短。即使面对大型事件日志,DFG 计算时间仍保持在可控范围内,表明处理过程高效。

作者评估了使用列式存储格式的数据框实现在实际事件日志上的性能,对比了存储大小、加载时间、内存使用、过滤速度与 DFG 计算时间。结果表明,列式格式显著降低了存储大小并提升了加载效率,尤其是在仅加载相关属性时,这证明了数据框在处理大规模事件日志方面的有效性。与传统格式相比,列式存储格式减少了存储空间与加载时间。仅加载特定属性可提高效率并降低内存使用。数据框能够高效处理包含数百万事件与案例的大型日志。

{"summary": "作者评估了使用列式存储格式的数据框实现在实际事件日志上的性能,重点关注磁盘大小、加载时间、内存使用、过滤效率及 DFG 计算时间等指标。结果表明,数据框能够有效处理包含不同数量事件、案例与属性的日志,在流程挖掘应用中展现出良好的可扩展性与效率。", "highlights": ["数据框能够高效处理包含不同数量事件、案例与属性的实际日志。", "不同日志的加载时间与内存使用差异显著,部分日志需要显著更多的资源。", "该方法展现出良好的可扩展性,因为数据框能够有效管理包含数百万事件与复杂结构的日志。"]}
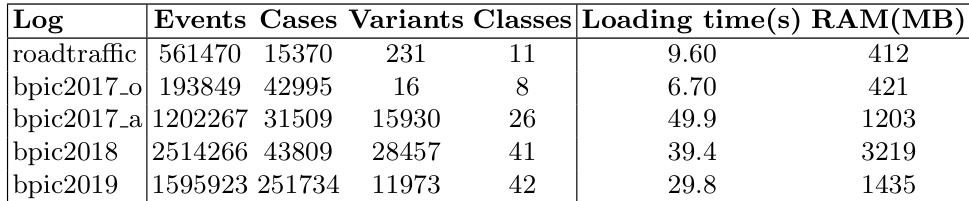
作者评估了使用列式存储格式的数据框实现在实际与合成事件日志上的性能,重点关注计算复杂度与资源消耗。结果表明,数据框能够高效处理大规模事件日志,具体性能因操作类型与数据结构而异。与经典事件日志处理相比,数据框操作呈现出不同的复杂度模式,部分操作在数据按案例 ID 预排序后性能得到提升。数据框操作的复杂度受任务性质影响,过滤与移位操作表现出低于全量遍历的复杂度。评估表明,数据框能够有效管理大型事件日志,其性能取决于具体的计算任务与数据组织方式。
该评估在真实世界与合成事件日志上测试了采用列式存储格式的数据框实现,以验证其在流程挖掘工作流中的可扩展性与计算效率。这些实验考察了在不同数据量与结构配置下,数据加载、过滤与依赖图计算等核心操作的性能。定性结果表明,列式存储显著提升了存储紧凑性并加速了查询执行,尤其是在利用选择性属性加载时。总体而言,研究结果证明,数据框为管理大规模事件日志提供了一个高度可扩展且高效的框架,其性能与特定的数据组织策略高度契合。