Command Palette
Search for a command to run...
拜占庭容错分布式优化中的数据编码
拜占庭容错分布式优化中的数据编码
Deepesh Data Linqi Song Suhas Diggavi
泰坦尼克号数据科学解决方案
摘要
我们研究了存在拜占庭对手情况下的分布式优化问题,其中数据和计算分布在 m 个工作机器上,其中 t 个可能已受损。这些受损节点可以协同且任意地偏离其预先指定的程序,而一个指定的(主)节点迭代计算广义线性模型的模式/参数向量。在本工作中,我们主要关注两种迭代算法:近端梯度下降(PGD)和坐标下降(CD)。梯度下降(GD)是这些算法的特例。PGD 通常用于数据并行设置,其中数据在不同样本间划分;而 CD 用于模型并行设置,其中数据在参数空间间划分。我们对这两种算法的解决方案核心在于一种拜占庭容错的矩阵-向量(MV)乘法方法;为此,我们提出了一种基于实数域上的数据编码和纠错的方法,以抵御对抗性攻击。我们能够容忍多达 t \leq \left\lfloor rac{m-1}{2} ight floor 个受损的工作节点,这在信息论意义上是最优的。我们提供了确定性保证,且我们的方法不对数据假设任何概率分布。我们开发了一种稀疏编码方案,实现了计算高效的数据编码和解码。
一句话总结
作者提出了一种针对近端梯度下降和坐标下降的拜占庭容错分布式优化框架,该框架采用实数上的数据编码和纠错技术以实现拜占庭容错矩阵向量乘法,通过计算高效的稀疏编码方案,在无需假设数据分布的情况下,实现了对腐败节点的信息论最优容忍度,并提供确定性保证。
核心贡献
- 本文提出了一种基于实数数据编码和纠错的拜占庭容错矩阵向量乘法方法。该方法无需假设数据的任何概率分布,即可在信息论最优保证下容忍多达一半的工作节点腐败。
- 本工作利用编码矩阵的特定规则结构,提出了首个针对拜占庭攻击下分布式坐标下降的高效解决方案。该方法支持每次迭代中的部分坐标更新,区别于梯度下降中使用的一般目的代码。
- 开发了一种稀疏编码方案,在保持底层矩阵稀疏性的同时实现计算高效的数据编码和解码。该设计确保在实现拜占庭容错的同时,不损害通常由稀疏矩阵操作获得的计算效率。
引言
分布式学习框架通常在部分可信的工作节点上运行,这些节点可能充当拜占庭对手。先前的解决方案通常依赖数据的统计假设,或采用鲁棒聚合技术,这会带来显著的计算开销和近似误差。大多数现有研究也集中于梯度下降,使得模型并行坐标下降算法在针对此类攻击时基本未受保护。作者利用基于实数纠错的稀疏数据编码方案来实现拜占庭容错矩阵向量乘法。该方法在无需概率数据假设的情况下提供确定性保证,同时容忍多达一半的工作节点腐败。值得注意的是,该团队是首个将矩阵向量乘法与坐标下降相结合,以设计高效、抗攻击安全优化方法的团队。
方法
作者提出了基于数据编码和实数纠错的拜占庭容错分布式优化算法,适用于近端梯度下降 (PGD) 和坐标下降 (CD)。核心方法涉及对数据矩阵和参数向量进行编码,以容忍恒定比例的恶意工作节点,而无需依赖关于数据或攻击模式的统计假设。
对于 PGD 中的梯度计算,该过程被构建为两轮矩阵向量乘法方案。请参考拜占庭容错分布式梯度下降的 2 轮方法框架图。
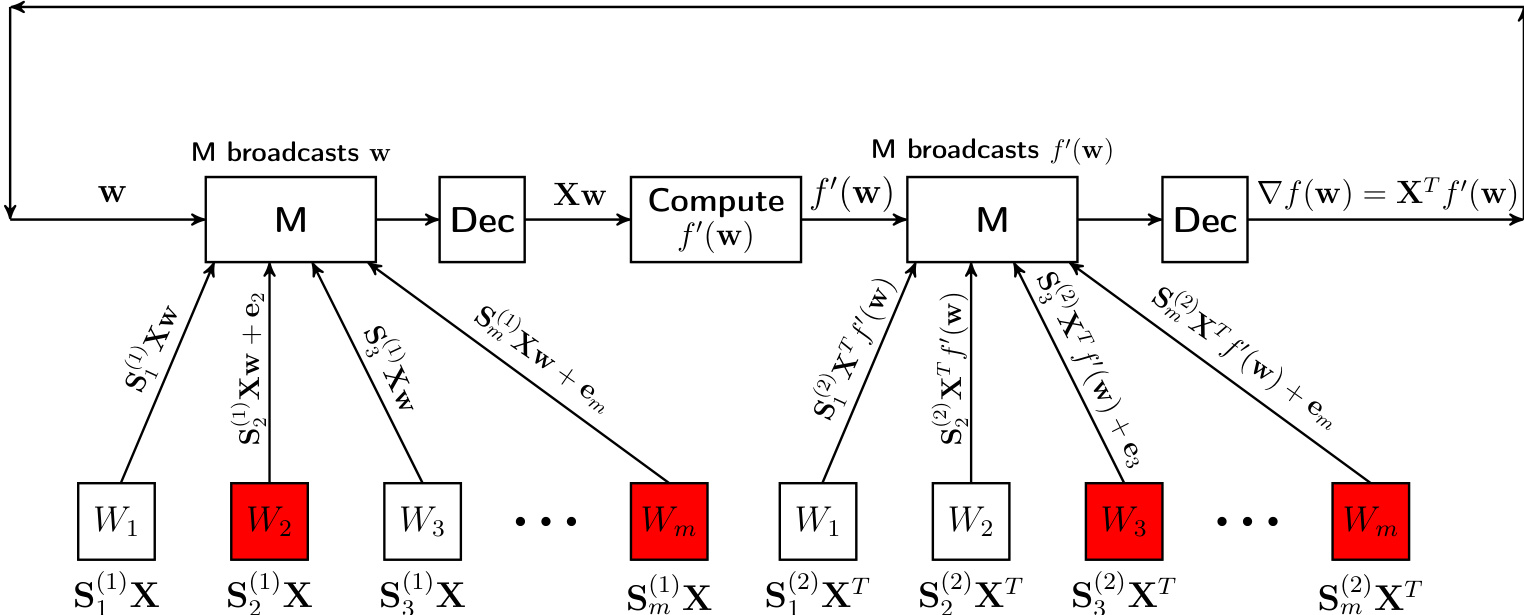 梯度 ∇f(w)=XTf′(w) 分两个阶段计算。在第一轮中,主节点将参数向量 w 广播给工作节点。每个工作节点 i 持有数据矩阵的编码版本 Si(1)X,并计算乘积 Si(1)Xw。主节点收集这些响应,应用纠错解码过程以恢复真实向量 Xw,并在本地计算 f′(w)。在第二轮中,主节点广播 f′(w)。工作节点使用应用于 XT 的第二个编码矩阵 S(2) 来计算 Si(2)XTf′(w)。主节点解码这些结果以获得最终梯度 ∇f(w)。编码矩阵被设计为具有规则结构的稀疏矩阵,这有助于使用实数上的稀疏重建技术进行高效解码。
梯度 ∇f(w)=XTf′(w) 分两个阶段计算。在第一轮中,主节点将参数向量 w 广播给工作节点。每个工作节点 i 持有数据矩阵的编码版本 Si(1)X,并计算乘积 Si(1)Xw。主节点收集这些响应,应用纠错解码过程以恢复真实向量 Xw,并在本地计算 f′(w)。在第二轮中,主节点广播 f′(w)。工作节点使用应用于 XT 的第二个编码矩阵 S(2) 来计算 Si(2)XTf′(w)。主节点解码这些结果以获得最终梯度 ∇f(w)。编码矩阵被设计为具有规则结构的稀疏矩阵,这有助于使用实数上的稀疏重建技术进行高效解码。
对于坐标下降,该方法经过调整以处理坐标子集的更新,同时保持拜占庭容错。如下文图所示,该方法扩展了编码策略以处理坐标子集上的参数更新。
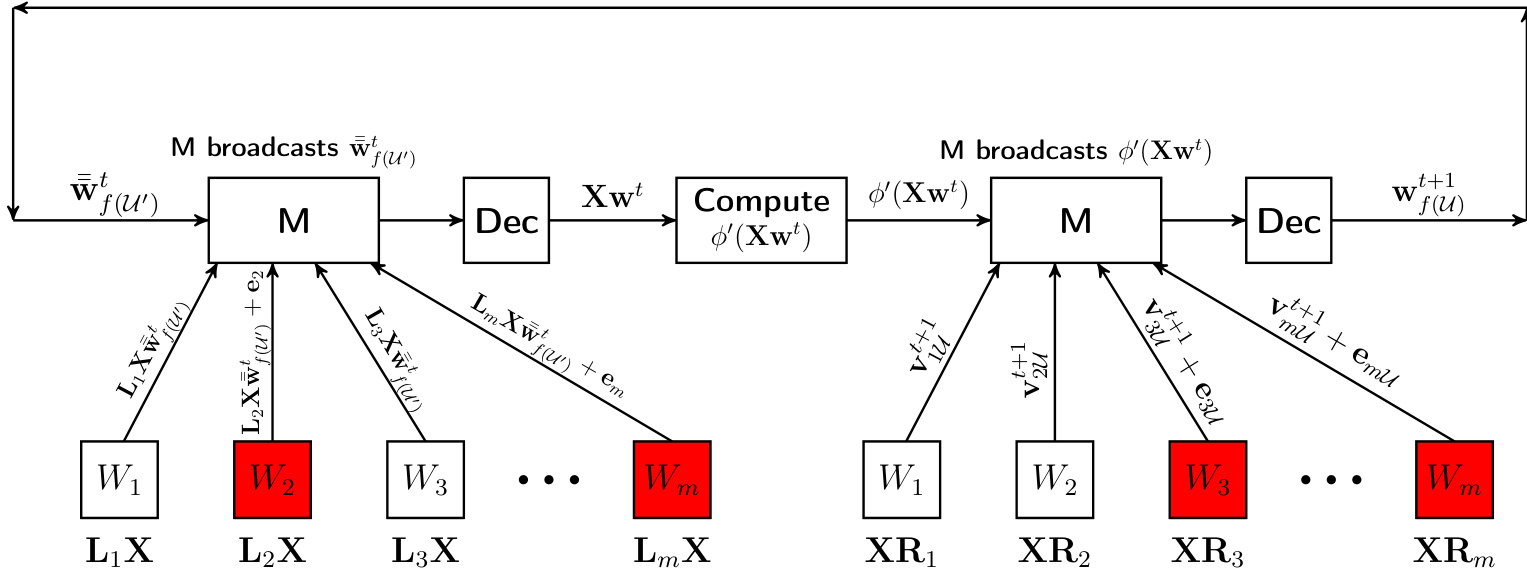 作者通过编码矩阵 R 将原始参数向量 w 编码为更高维向量 v 来扩大参数空间,使得 v=R+w。工作节点存储编码数据 XRi 并更新其本地 vi 的特定坐标。为了促进这些更新,主节点必须鲁棒地计算 Xw(或其更新)。这是通过对数据矩阵 X 使用另一个编码矩阵 L 来实现的。在每次迭代中,主节点广播到 w 的相关更新,工作节点计算涉及 LiX 的本地矩阵向量乘积,主节点解码结果以更新全局状态。该设计确保更新 v 中的小坐标子集对应于更新 w 中的特定坐标子集,允许算法即使在工作节点提供错误更新时也能正确进行。
作者通过编码矩阵 R 将原始参数向量 w 编码为更高维向量 v 来扩大参数空间,使得 v=R+w。工作节点存储编码数据 XRi 并更新其本地 vi 的特定坐标。为了促进这些更新,主节点必须鲁棒地计算 Xw(或其更新)。这是通过对数据矩阵 X 使用另一个编码矩阵 L 来实现的。在每次迭代中,主节点广播到 w 的相关更新,工作节点计算涉及 LiX 的本地矩阵向量乘积,主节点解码结果以更新全局状态。该设计确保更新 v 中的小坐标子集对应于更新 w 中的特定坐标子集,允许算法即使在工作节点提供错误更新时也能正确进行。
解码机制依赖于错误定位矩阵 F(通常是范德蒙德矩阵)来识别腐败工作节点集。通过构建编码矩阵使其零空间与 F 相关,主节点可以通过接收向量的随机线性组合来隔离错误支持。一旦识别出腐败节点,其贡献将被丢弃,剩余的诚实响应将用于通过最小二乘或类似恢复方法恢复精确的矩阵向量乘积。这使得系统能够容忍多达 t<m/2 个腐败节点,与不可容错基线相比,存储和计算开销恒定。
实验
评估将提出的编码方案与 DRACO 和拉格朗日编码计算进行比较,以验证资源效率,随后在分布式梯度下降和坐标下降上进行数值实验,以测试拜占庭对手下的性能。结果表明,提出的方法在工作节点上实现了比 DRACO 更低的存储和计算冗余,同时提供了比拉格朗日编码计算更优越的通信效率。数值实验进一步证实,该方法有效处理腐败工作节点,为部分坐标下降更新节省了显著时间,且主节点开销可忽略不计。
实验评估了在存在拜占庭对手的情况下,具有不同更新坐标比例的坐标下降 (CD) 与完整梯度下降 (GD) 的计算时间。结果表明,与完整梯度更新相比,更新较少的坐标显著减少了工作节点和主节点的执行时间。此外,随着腐败工作节点数量的增加,计算和解码所需的时间也随之增加。部分坐标更新 (CD) 对于工作节点和主节点而言,始终比完整梯度下降 (GD) 需要更少的时间。对于小比例坐标的 CD,工作节点计算时间远低于完整 GD。增加腐败工作节点数量会导致所有算法配置的处理时间稳步增加。
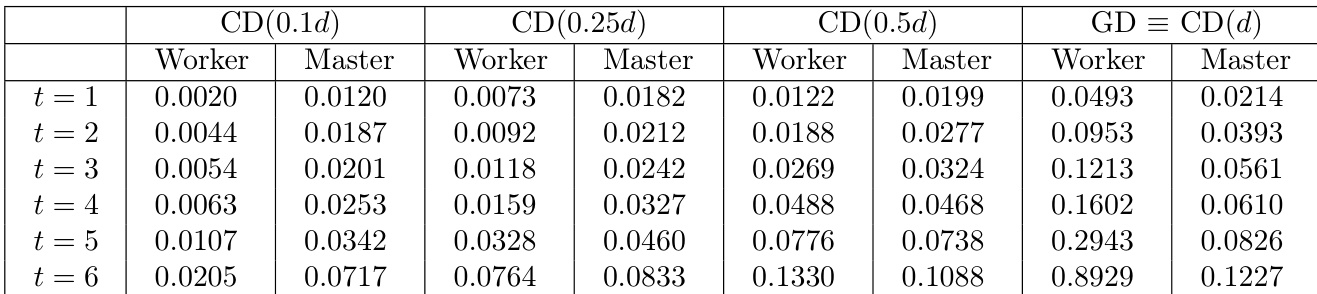
实验评估了在存在拜占庭对手的情况下,具有不同坐标更新比例的坐标下降与完整梯度下降的计算时间。发现显示,与完整梯度下降相比,部分坐标更新始终减少了工作节点和主节点的执行时间,尤其是在更新一小部分坐标时。此外,随着腐败工作节点数量在所有配置中增加,计算和解码的处理时间也稳步增加。