Command Palette
Search for a command to run...
面向语音识别错误分析的音素导向词错误对齐(用于机器翻译)
面向语音识别错误分析的音素导向词错误对齐(用于机器翻译)
Nicholas Ruiz Marcello Federico
一键部署 Whisper-large-v3-turbo
摘要
我们提出了一种对常用于语音识别评估的词错误率(WER)指标的变体,该指标在缺乏时间边界信息的情况下引入了音素对齐。在计算参考转录与假设转录中词汇的莱文斯坦对齐后,相邻错误跨度被转换为带有词和音节边界的音素,并执行音素层面的莱文斯坦对齐。音素对齐信息用于修正每个错误区域中的词对齐标签。我们证明,我们的音素导向词错误率(POWER)产生的分数与 WER 相似,同时具有更好的词对齐能力,以及能够捕捉语音识别假设中与同音错误相对应的一对多对齐关系。这些改进的对齐使我们能够更好地追踪语音识别中莱文斯坦错误类型对下游任务(如语音翻译)的影响。
一句话总结
作者提出了语音导向的词汇错误率(POWER),这是一种 WER 的变体,它在词汇错误跨度内应用语音 Levenshtein 对齐来修正对齐标签并捕获同音映射,从而生成与标准 WER 相当的分值,同时能够更准确地追踪识别错误,以便进行下游语音翻译分析。
核心贡献
- 本文提出了语音导向的词汇错误率(POWER),这是一种语音识别评估指标,它结合了音素级对齐,在不需要时间边界信息的情况下解决标准 Levenshtein 词汇对齐中的歧义问题。
- 该方法使用文本到语音的文本分析组件将相邻的词汇错误跨度转换为音素,执行语音 Levenshtein 对齐,并将生成的映射关系应用于细化每个受影响区域内的词汇级错误标签。
- 实验评估表明,POWER 在保持标准词汇错误率分值的同时,生成了更准确的词汇对齐结果,识别出同音的一对多错误,并生成了细化的错误分布,从而提升了下游语音翻译分析的效能。
引言
口语翻译系统通常将独立的自动语音识别与机器翻译模型串联,因此理解语音识别错误如何影响翻译质量至关重要。传统评估依赖于词汇错误率指标,该指标使用标准 Levenshtein 对齐对错误进行分类。这种传统方法经常忽略语音和语言关系,往往导致实词对齐错误,并且无法检测到跨越多个 token 的同音错误。为克服这些局限,作者利用文本到语音的发音词典与字母到音素的规则,为相邻的识别错误计算语音导向的对齐方式。这种改进后的方法生成了符合语言学规律的错误分布,使得预语音识别(pre-ASR)文本标准化更加可靠,并能精确分析识别错误如何影响翻译性能。
数据集
- 数据集构成与来源: 作者使用自动语音识别假设数据,汇总实验运行中的错误统计信息,以分析影响下游处理的转录错误。
- 关键子集详情: 错误被划分为不同的类别,其中闭类词(closed class word)的插入与删除约占全部错误的 16.2%。替换跨度构成了其余的高频错误,通常源于同音混淆,即系统选择了语音相似的词序列。
- 数据使用与处理: 团队利用此错误分类来训练恢复模型并评估统计机器翻译实验。在开发过程中,他们采用 POWER 框架来准确标记未对齐的词汇,确保处理插入与删除错误时具有可靠的训练信号。
- 额外处理与元数据: 作者不依赖裁剪或显式元数据生成,而是专注于提取替换跨度并映射语音错误模式。该方法支持模型重评分或保留序列歧义,以便下游组件能够区分发音相似的替代选项。
方法
作者采用语音导向的对齐方法来增强传统的词汇错误率(WER)指标,在错误分析过程中引入语音信息。该框架首先基于参考文本与假设文本在词汇层面进行标准的 Levenshtein 对齐。随后,相邻错误的跨度(定义为包含至少一次替换的序列)利用词汇和音节边界被分割为音素。这种语音分割使得能够在音素层面执行第二次 Levenshtein 对齐,从而捕获语音混淆性并解决词汇级对齐中的歧义。随后,生成的语音对齐信息被用于细化原始的词汇级对齐,特别是在错误区域,以生成更准确的替换、删除和插入标签。

如图所示,对齐过程通过动态规划矩阵进行可视化,其中最优路径基于编辑操作确定。该矩阵追踪插入、删除和替换的成本,箭头指示状态之间的转移。该图展示了音素级对齐如何通过考虑语音相似性来解决词汇级对齐中的歧义。例如,对齐路径反映了基于语音邻近度的 "ao" 与 "ae" 之间的替换,随后该信息被用于细化词汇级错误标签。这种方法确保即使涉及同音或语音相似的词汇,替换也能被正确识别,而在标准 WER 中这些词汇常被误分类为删除或插入。
语音导向的对齐过程进一步利用启发式方法进行了优化,以解决存在多条最优路径时的歧义问题。具体而言,该算法通过将回溯路径编码为边加权图并应用 Dijkstra 算法选择最合理的对齐方式,来最小化参考文本与假设文本中首尾词汇边界之间的空隙数量。此外,为防止将替换标签过度分配给缺乏语音对应关系的单音节词,该方法会检查额外音节是否对应新词的开头,从而将其正确分类为删除或插入。
最终的语音导向词汇错误率(POWER)使用与 WER 几乎相同的公式计算,定义如下:
POWER=LS+D+I+SS,SS=span∑max(∣spanref∣,∣spanhyp∣),其中 L 为参考文本的长度,S、D 和 I 分别为替换、删除和插入错误的数量,SS 表示替换跨度的加权计数,每个跨度以参考文本或假设文本中的最大词汇数作为权重。该公式涵盖了一对多或多对多对齐情况,这些情况表明存在语音混淆性,并有助于构建更准确的错误模型。
实验
实验使用经多个自动语音识别系统与基线翻译模型处理的 TED 演讲语料,评估语音到文本的翻译效果。第一组实验验证了传统对齐指标经常错误分类同音和多词替换等复杂识别问题,而引入语言学信息的对齐方法能够生成更准确的错误分布。后续分析衡量了这些细化的错误类别如何影响下游翻译质量,结果表明同类词替换和替换跨度是导致性能下降的主要驱动因素。最终,研究得出结论:基于频率加权且具备语言学意识的错误分析,为理解并解决阻碍机器翻译的特定语音识别缺陷提供了更可靠的框架。
作者通过分析混合效应模型,使用 WER 和 POWER 两种对齐方法比较了自动语音识别错误类型对翻译质量的影响。结果表明,POWER 识别出的替换跨度对翻译错误具有显著影响,不同类型的错误对翻译性能下降的贡献程度因对齐方法而异。基于 POWER 的对齐将替换跨度识别为翻译质量的重要预测指标,而这是 WER 无法捕捉的。与 WER 相比,使用 POWER 对齐时插入错误对翻译质量的影响有所增加。就频率加权对翻译性能下降的贡献而言,同类词替换错误的影响最为显著。
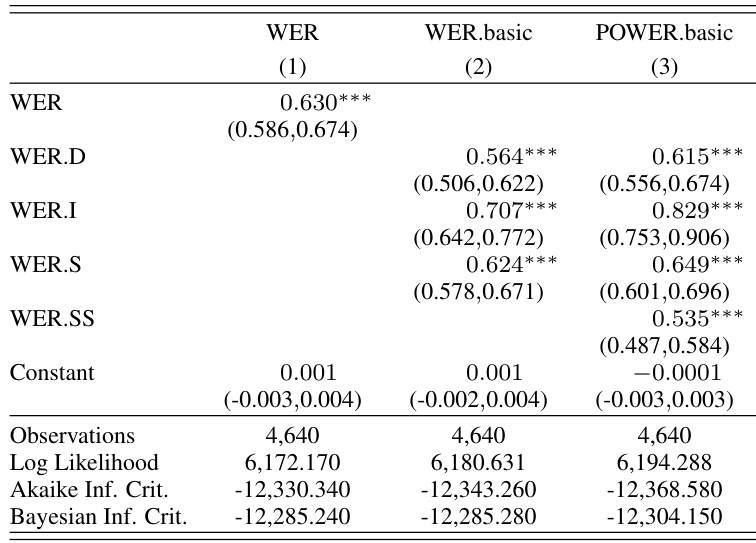
作者使用 WER 和 POWER 两种对齐方法分析了自动语音识别错误类型及其对下游翻译质量的影响。结果表明,POWER 提供了更细致的错误分类,特别是在识别替换跨度以及降低插入与删除错误的影响方面。分析显示,某些错误类型,尤其是涉及开类词(open-class words)的错误,对翻译性能的影响更大。与 WER 相比,POWER 对齐降低了报告中的插入与删除错误影响,突显了更准确的错误分类。涉及开类词的替换错误对翻译质量下降有显著贡献。包含多个假设词汇的替换跨度较为常见,并对翻译性能产生显著影响。
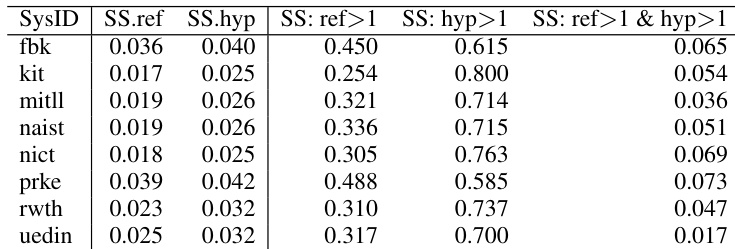
作者利用混合效应模型分析了自动语音识别错误类型及其对下游翻译质量的影响。结果表明,替换错误,尤其是涉及开类词和替换跨度的错误,对翻译性能下降的影响最为显著,且基于 POWER 的对齐提供了比 WER 更准确的错误分类。涉及开类词和替换跨度的替换错误对翻译质量的影响最大。与 WER 相比,基于 POWER 的对齐能识别出更准确的错误类型,尤其是针对替换跨度。同类词替换以及包含开类词参考词汇的替换跨度对翻译错误增加的影响最为显著。
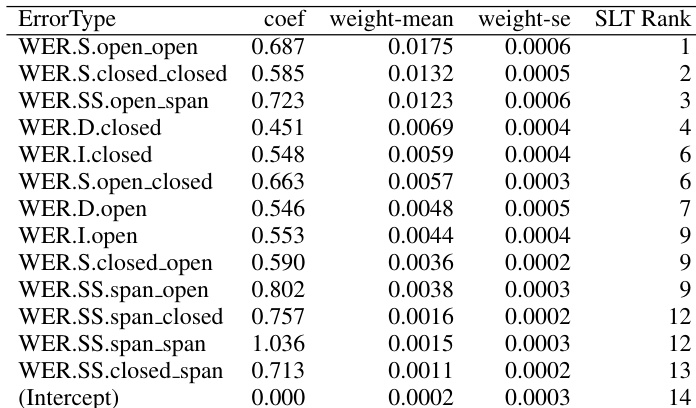
作者使用 IWSLT 2013 评估中的自动语音识别假设数据与参考数据,比较了 WER 和 POWER 两种对齐方法的错误类型分布。结果表明,POWER 提供了不同的错误分类,特别是降低了插入与删除的频率,同时提升了替换跨度及某些特定词汇类别错误的重要性。分析显示,涉及开类词和替换跨度的错误类型对下游翻译质量的影响更强。与 WER 相比,POWER 对齐降低了报告的插入与删除频率,同时增加了替换跨度的相对重要性。涉及开类词和替换跨度的替换错误对翻译质量的影响大于其他错误类型。自动语音识别错误对翻译质量的贡献因词汇类别和对齐方法的不同而有显著差异,POWER 揭示了更细致的错误模式。
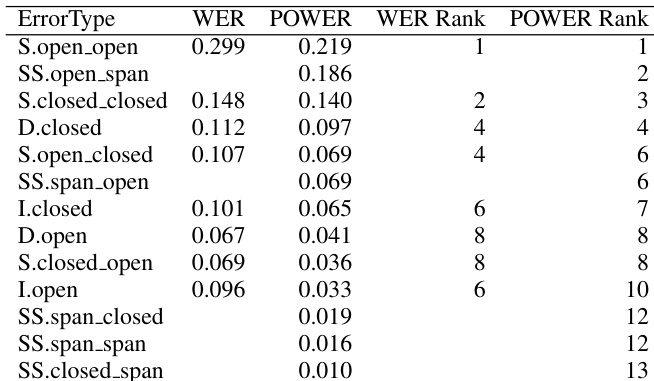
作者使用 WER 和 POWER 两种对齐方法分析自动语音识别错误及其对下游翻译任务的影响,以比较错误分布及其对翻译质量的作用。结果表明,不同的对齐技术会导致不同的错误类型分布,且某些错误类型,尤其是涉及开类词和替换跨度的错误,对翻译性能具有显著影响。POWER 对齐降低了 WER 分值,并提供了与 WER 不同的错误类型分布,特别是减少了报告的插入与删除数量。涉及开类词和替换跨度的替换错误被确认为翻译质量下降的主要贡献者。使用 POWER 对齐的错误类型能更准确地捕捉自动语音识别错误对翻译的影响,尤其是针对替换跨度和开类词替换。
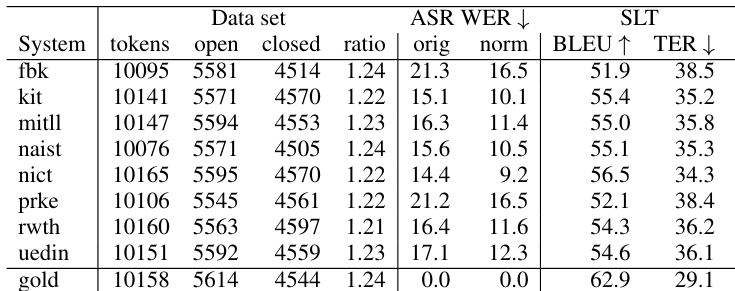
实验通过混合效应建模,比较传统的 WER 对齐与更细致的 POWER 对齐方法,评估自动语音识别错误对下游翻译质量的影响。分析验证了 POWER 提供了细化的错误分类,该分类弱化了插入与删除的影响,同时强调了替换跨度。定性分析表明,涉及开类词的替换错误成为翻译性能下降的最显著驱动因素,这证明错误的影响程度会因词汇类别和对齐方法的不同而产生显著差异。最终,与标准指标相比,POWER 对齐能更准确地评估特定语音识别错误如何损害翻译性能。