Command Palette
Search for a command to run...
使用深度卷积神经网络进行图像着色
摘要
一句话总结
通过对 VGG-16 和 ResNet-50 架构随机剪枝 25% 至 50% 的卷积核,本研究证明深度卷积网络能够凭借固有的可塑性恢复性能,而非依赖结构化的排序标准。该方法在自定义 ImageNet 基准测试上实现了具有竞争力的分类准确率,在 Faster R-CNN 目标检测中达到 74% 的帧率提升,并在 SegNet 分割任务中取得相当的结果。
核心贡献
- 实验表明,剪枝网络的性能恢复源于深度神经网络的固有可塑性,而非特定的重要性排序标准。这使得简单的随机剪枝策略能够在微调后移除 25% 至 50% 的卷积核,同时保持准确率。
- 在 VGG-16 和 ResNet-50 上的广泛评估验证了该结论。研究引入了一种基于 ImageNet 衍生的类别特定剪枝新基准,证明随机移除卷积核在受限测试集上始终能匹配最先进性能。
- 该方法延伸至目标检测与图像分割任务,在保持准确率的同时使 Faster R-CNN 的帧率提升 74%,并在 SegNet 中维持了相当的性能。
引言
深度卷积神经网络在计算机视觉任务中取得了最先进成果,但其沉重的计算与内存需求阻碍了其在资源受限设备上的部署。卷积核剪枝已成为降低推理成本的实用压缩策略,但先前的方法严重依赖启发式评分指标来排序并丢弃卷积核。该领域通常假设剪枝后的性能恢复能够验证这些指标,但这忽略了更广泛的恢复动态,且研究主要局限于图像分类。研究团队利用这一空白证明,深度网络恢复剪枝权重主要依靠固有可塑性,而非最优评分标准。研究表明,随机丢弃 25% 至 50% 的卷积核可在分类、目标检测与分割任务中取得与先进标准驱动方法相当的性能。此外,研究引入了类别特定剪枝的新基准,并提供了一套综合评估框架,用于衡量性能损耗、恢复速度与数据效率。
数据集
-
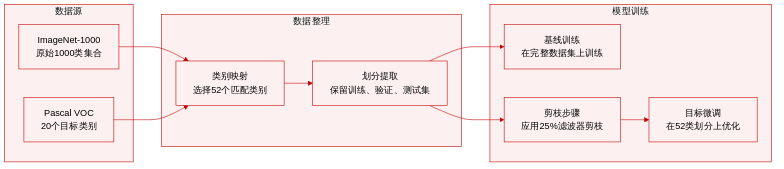
数据集构成与来源:研究团队基于 ImageNet 仓库构建了两个基准。基线数据集为 ImageNet-1000,即原始的 1000 类数据集。同时创建了 ImageNet-52P,这是一个自定义子集,旨在与 Pascal VOC 的 20 个类别对齐。
-
子集细节与过滤规则:ImageNet-52P 包含恰好 52 个 ImageNet 类别,对应 Pascal VOC 类别。研究团队通过仅选择每个 Pascal VOC 类别的直接下位词并剔除过于细粒度的子类,手动整理了该子集。两个数据集均保留 ImageNet 的标准训练集、验证集与测试集划分。训练集与测试集、验证集严格不重叠。具体图像数量未明确说明,类别构成是主要区别。
-
数据使用与训练协议:研究团队使用 ImageNet-1000 训练基线网络,并使用 ImageNet-52P 评估类别特定剪枝。在剪枝工作流中,每一层之后及最终阶段的微调仅使用 ImageNet-52P 的训练数据。该设置允许将在全 1000 类上训练的模型与仅针对 52 个目标类别优化的剪枝模型进行对比。
-
处理与评估细节:未应用图像裁剪或元数据构建。主要处理工作包括手动类别映射、划分提取以及固定的 25% 卷积核剪枝比例。模型性能在 ImageNet-52P 测试集上进行测量,以证明定向剪枝的准确率可媲美在较小数据集上从头训练的模型。
方法
研究团队采用了一种用于卷积神经网络(CNN)卷积核剪枝的通用算法框架,旨在系统性地降低模型复杂度同时保持性能。整体方法始于剪枝任务的正式定义:给定一个包含 K 个卷积层的 CNN,其中第 kth 层包含 nk 个卷积核,目标是对所有卷积核 {Fk1,Fk2,…,Fknk} 进行排序,并仅保留前 mk 个卷积核,其中 mk<nk 是由计算约束决定的超参数。该剪枝操作同时减少了层内计算量与输出特征图的空间维度,进而缩小了后续层的输入尺寸。该过程在所有层中迭代应用,并在每次剪枝步骤后执行微调以恢复丢失的准确率。
如图表所示,该框架以逐层方式运行,从最外层开始向内推进。在每一层中,应用评分函数为每个卷积核计算重要性得分。随后利用这些得分选择前 mk 个卷积核予以保留,其余卷积核被剪枝。剪枝后的网络随后进行 p 个轮次的微调,以适应缩减后的架构。所有层完成剪枝与微调后,整个网络将再进行 q 个轮次的微调,以确保收敛并获得最优性能。
剪枝过程的有效性取决于评分函数的选择,该函数决定了卷积核的排序。研究团队回顾了若干现有标准并引入了新变体。平均激活标准衡量训练集上卷积核输出的平均激活值;由于在 ReLU 下激活频率较低,平均激活值较低的卷积核被认为重要性较低。卷积核权重的 l1-范数是另一项标准,较小的范数表明对网络输出的影响较小。基于熵的标准通过测量激活值在各分箱中的分布来评估卷积核输出的信息量;较高的熵值表示响应更多样且可能更有用。平均零值百分比(APoZ)量化了特征图的稀疏程度,较高的零值百分比表明卷积核重要性较低。灵敏度通过损失函数对卷积核的梯度的 l1-范数计算,捕捉每个卷积核对最终预测的影响程度。
研究团队提出了一种名为缩放熵(scaled entropy)的新变体,该变体将熵与平均激活相结合,以惩罚产生高熵但低激活输出的卷积核。其定义为 SEi=−∑j=1bpijlogpij⋅Meani,其中 Meani 为第 ith 个卷积核的平均激活值。此外,针对模型仅用于原始类别子集的场景,引入了类别特定重要性标准。该方法仅针对属于目标类别的图像计算梯度范数的平均值,从而优先选择与这些类别相关的卷积核。最后,研究团队证明,即使采用随机剪枝,只要在后续配合微调,也能取得与结构化剪枝方法相当的性能,这挑战了重要性排序对有效剪枝至关重要的假设。
实验
在图像分类、目标检测与分割任务上使用标准卷积架构进行的评估验证了随机剪枝始终能匹配复杂标准驱动方法的性能、恢复速度与微调效率。进一步实验证实,剪枝前预训练更大网络的性能显著优于从头训练较小模型,同时对解码器层进行定向剪枝可产生有益的正则化效果,超越基线性能。综合来看,这些发现证明剪枝网络在迁移至全新任务时仍能保持卓越的鲁棒性,最终确立随机剪枝作为复杂剪枝启发式方法的高效且计算成本低的替代方案。
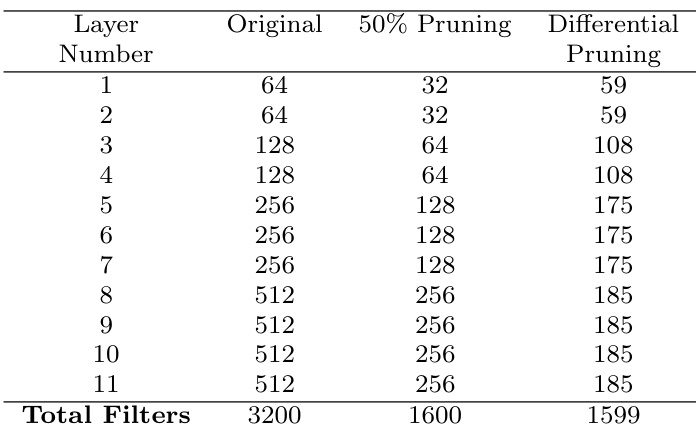
下表展示了应用于 VGG-16 网络的卷积核剪枝策略对比,具体比较了标准 50% 剪枝与基于各层卷积核数量动态调整剪枝比例的差异化剪枝方法。结果显示,两种情况下卷积核总数均有所减少,但差异化剪枝策略在底层保留更多卷积核,在高层剪枝更多,导致保留的卷积核总数略高。剪枝网络的性能在微调后的恢复背景下进行评估,其中差异化剪枝策略在准确率上表现出边际提升。相较于均匀 50% 剪枝,差异化剪枝在底层保留更多卷积核并在高层剪枝更多。差异化剪枝下保留的卷积核总数高于均匀 50% 剪枝。与均匀 50% 剪枝相比,差异化剪枝策略带来了网络准确率的轻微提升。
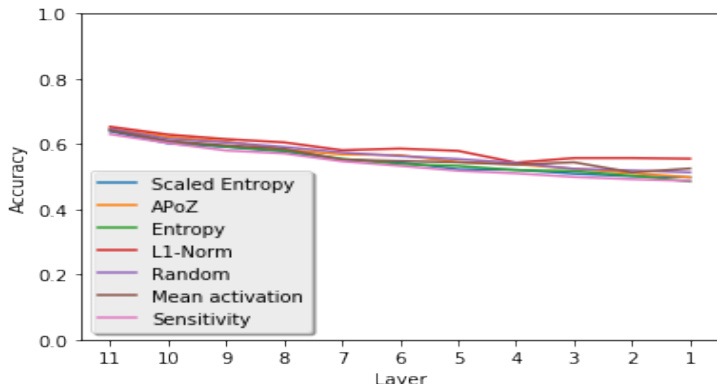
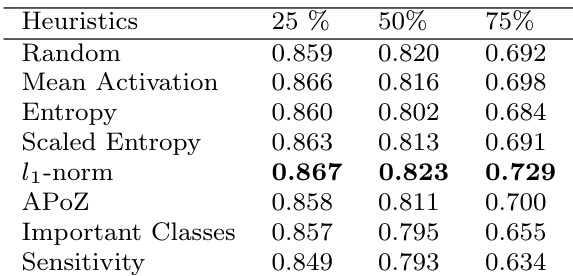
研究团队在 VGG-16 网络上针对图像分类比较了多种卷积核剪枝策略,评估了剪枝与微调后的性能。结果表明,随机剪枝取得了与 l1-norm 等原则性方法相当的性能,在不同剪枝比例与策略下准确率差异极小。研究发现表明,剪枝后的恢复过程不受剪枝标准选择的显著影响,且随机剪枝在维持网络性能方面与结构化方法同样有效。在不同剪枝比例下,随机剪枝的性能均与 l1-norm 等结构化剪枝方法相当。所有策略在剪枝后的恢复量相似,表明随机剪枝不劣于原则性方法。在使用微调网络时,无论剪枝造成的初始损伤如何,剪枝策略对最终性能的影响微乎其微。
研究团队在 VGG-16 网络上比较了多种卷积核剪枝策略,评估了不同稀疏度水平下剪枝与微调后的性能。结果表明,随机剪枝在不同剪枝比例下表现与原则性方法相似或更优,恢复量与恢复速度差异极小。研究发现表明,在应用充分微调的情况下,剪枝策略的选择对最终性能影响甚微。在不同稀疏度水平下,随机剪枝取得了与原则性剪枝方法相当的性能。所有策略在剪枝后的恢复量相似,表明最终性能不受剪枝标准的显著影响。所有剪枝方法的恢复速度与微调所需数据量相当,随机剪枝的表现与更复杂的策略持平。
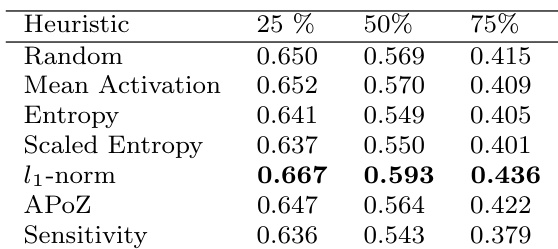
研究团队在 VGG-16 上比较了不同的卷积核剪枝策略,重点关注不同压缩级别下剪枝与微调后的性能。结果表明,随机剪枝的表现与 l1-norm 等原则性方法相当,恢复量、恢复速度与数据需求相似,表明剪枝策略的选择对最终性能影响极小。该发现延伸至目标检测与图像分割等其他任务,随机剪枝同样产生了稳健的结果。在恢复与微调后性能方面,随机剪枝与 l1-norm 等原则性方法表现一致。在不同压缩级别与任务中,剪枝策略的选择对最终性能影响微乎其微。在目标检测与图像分割任务中,即使应用于不同的网络组件,随机剪枝也能取得与其他方法相当的结果。
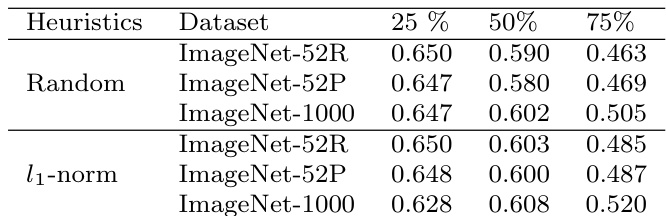
研究团队在 VGG-16 网络上比较了不同的卷积核剪枝策略,评估了剪枝与微调后的性能。结果表明,随机剪枝取得了与 l1-norm 等原则性方法相当的性能,恢复量与恢复速度差异极小。研究发现表明,在应用充分微调的情况下,剪枝策略的选择对最终性能影响甚微。在微调后的最终性能方面,随机剪枝与 l1-norm 等原则性方法表现一致。不同剪枝策略的恢复速度与微调所需数据量相当。剪枝策略的选择并未显著影响性能,表明性能恢复不依赖于初始剪枝标准。
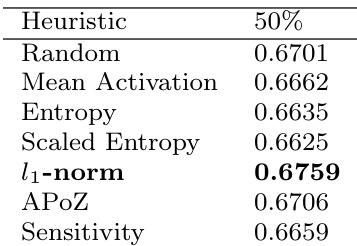
实验在 VGG-16 及相关视觉任务上评估了多种卷积核剪枝策略,包括随机、均匀、差异化与 l1-norm 方法,以验证初始剪枝标准是否显著影响网络恢复与微调后准确率。结果表明,随机剪枝的表现与结构化方法相当,在不同压缩级别下,最终准确率、恢复速度与微调数据需求差异可忽略不计。最终发现表明,剪枝方法的选择对整体性能影响极小,因为充分的微调能够有效恢复网络能力,这与具体选择策略无关。