Command Palette
Search for a command to run...
基于常规血液检查预测冠心病
基于常规血液检查预测冠心病
Ning Meng Peng Zhang Junfeng Li Jun He Jin Zhu
冠心病预测
摘要
本研究旨在探讨常规血液检查结果与冠心病(CHD)风险之间的关联,将其纳入冠心病预测模型,并比较该方法与其他预测函数的判别性能。本研究设计为一项回顾性单中心研究,基于医院队列。基线时5060名冠心病患者(男性2365人,女性2695人)年龄为1至97岁,拥有8年(2009–2017年)的医疗记录、5051次健康体检以及5075例其他疾病病例。我们基于常规血液数据开发了一种双层梯度提升决策树(GBDT)模型,用于预测冠心病风险,该模型可识别出86%的冠心病患者。我们构建了一个包含15,000个常规血液检测结果的数据集。利用该数据集,我们训练了双层GBDT模型以分类健康状态、冠心病和其他疾病。机器学习分类结果显示,在所有数据中,检测健康数据的灵敏度约为93%,而在包含冠心病的疾病数据中,检测冠心病的灵敏度为93%。在此基础上,我们进一步可视化了常规血液结果与相关数据项目之间的相关性,发现所有数据呈现中健康与冠心病存在明显模式,可作为临床参考。最后,我们从病理生理学角度对上述结果进行了简要分析。通过测试结果与相关数据项目之间的相关性,常规血液数据提供了比现有认知更多的关于冠心病的信息。我们使用GBDT算法开发了一个简单的冠心病预测模型,该模型将有助于医生预测无明显冠心病症状患者的冠心病风险。
一句话总结
基于15,000份常规血液检测结果,本研究开发了一种两层梯度提升决策树(GBDT)模型,该模型在分类健康状态、冠心病及其他疾病时灵敏度约为93%,证明了常规血液指标在冠心病风险预测中的临床价值。
核心贡献
- 利用包含15,000条常规血液检测记录的数据集,开发了一种两层梯度提升决策树(GBDT)模型,用于分类健康状态、冠心病及其他疾病。该框架通过处理标准血液学指标,实现了早期风险分层。
- 该算法在一般健康分类中达到约93%的灵敏度,并在评估队列中识别出86%的冠心病病例。这些性能指标证明了常规采集的实验室数据的预测价值。
- 对特定血液学指标(包括血小板分布宽度与红细胞分布宽度)与冠心病病理之间的相关性进行了可视化与分析。该研究揭示了区分健康队列与患病患者的明确生理模式,并为病理生理学解释提供了支持。
引言
冠心病给全球健康带来沉重负担,但早期检测仍具挑战,因为血管造影等常规诊断手段仅能揭示晚期病理。现有的临床风险评分常因依赖专业血脂面板、临床评估或基因组测试而难以识别高危人群,尤其是年轻患者,这些检测往往成本高昂或难以获取。为弥补这一空白,研究团队利用广泛可用的常规血液检测数据,训练了一种两层梯度提升决策树模型,该模型在分类健康状态和预测冠心病风险时灵敏度约为93%。通过将特定血液指标与慢性缺氧、全身性炎症及凝血失调等潜在病理生理机制相关联,该团队构建了一种低成本、自动化的筛查框架,助力临床医生更早启动预防性干预。
数据集
- 数据集构成与来源: 研究团队汇总了来自中国东部16,860名患者的临床记录,信息提取自门诊系统、住院检查日志及常规体检数据库。该队列最初被划分为三个诊断类别:冠心病、其他疾病及健康人群。
- 子集详情与标注: 初始划分包含5,060名冠心病患者、5,075名其他疾病患者及剩余的健康个体。原始标签将冠心病设为1,其他疾病设为-1,健康受试者设为0。经过质量控制步骤将数据量缩减至15,033条记录后,研究团队从每组中随机抽取5,000例,构建严格平衡的1:1:1混合数据集。
- 数据处理与特征工程: 原始输入经过标准化处理,包括将性别类别转换为二值变量。针对高稀疏性问题,首先剔除含缺失值的行,随后使用分组均值填补剩余空缺。临床异常值通过领域特定规则进行过滤。最终特征矩阵结合了基础人口学信息与22项标准化血液常规指标,如白细胞计数、血红蛋白水平、血小板参数及分类细胞百分比。
- 训练策略与模型应用: 分析工作被构建为两层分类流水线。第一层使用包含10,000条记录的子集(按70%训练集与30%验证集划分),将健康受试者与所有患病患者进行分离。第二层通过剔除健康记录,并对剩余10,000例应用相同的70/30划分,实现冠心病与其他疾病的区分。平衡数据在逻辑回归、支持向量机与梯度提升决策树之间进行评估,网格搜索调优后(学习率0.23,估计器数量70)选定GBDT为最优模型。
方法
研究团队利用两层梯度提升决策树(GBDT)分类模型,基于血液常规数据开展冠心病(CHD)的低成本风险评估。该模型旨在基于大规模临床病例数据集,将患者划分为高风险与低风险类别。整体框架包含两个连续阶段:第一层执行初始分类,第二层利用特征子集优化预测结果,从而提升模型的判别能力。每一层由多棵决策树构成,每棵树的构建过程均基于指定指标进行特征选择。越靠近树根节点且被频繁分裂的特征被视为越重要,这反映了其对分类准确率的更高贡献。
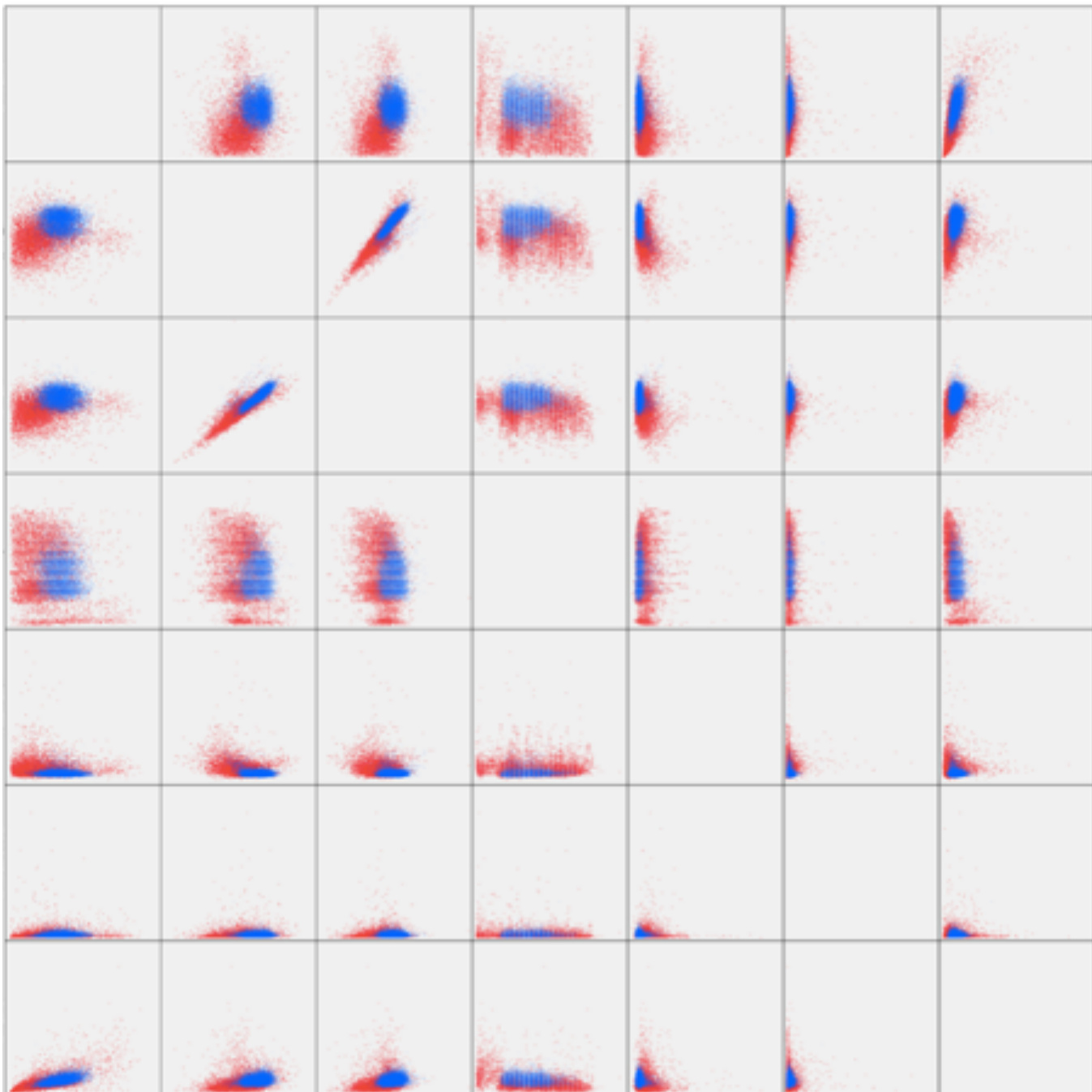
如图所示,研究团队基于特征重要性排名,对两层中贡献度最高的选定特征(LY%、HCT、RBC、年龄、RDW、BASO% 和 LY)进行了相关性分析。散点图展示了健康个体与冠心病患者的聚集效应,其中蓝点代表健康人群,红点代表冠心病患者。两组之间的分离度明显,表明所选特征有效捕捉了人群间的区分模式。可视化结果还显示,健康人群呈现出更紧密的聚集状态,这与模型对健康个体(91%)的召回率高于冠心病患者(86.5%)的结果相一致。
参考框架图,该图直观呈现了血液常规数据中所有特征间的关系。研究团队使用虚线连接特征,以说明复杂的相互依赖性与聚类模式。图表区分了健康个体(绿色)、冠心病患者(红色)及其他疾病(蓝色),绿色与红色簇之间存在清晰的分界。这证实了模型的分类性能,并揭示了底层数据结构,表明所选特征形成了支持模型预测决策的明确分组。
实验
评估环节采用基于血液常规数据训练的两层梯度提升决策树模型,将个体分类为健康、冠心病及其他疾病类别。该实验设计通过将数据关联系统映射至底层生理机制,验证了层级分类与直接分类在预测效能上的等效性,以及临床生物标志物的可解释性。定性分析证实,该框架能有效区分疾病状态,同时揭示出与已知病理生理过程相符的明确且具有临床意义的模式。最终,研究得出结论:常规血液检测提供了充足的结构信息,足以支持精准的风险分层与具有临床价值的解读。
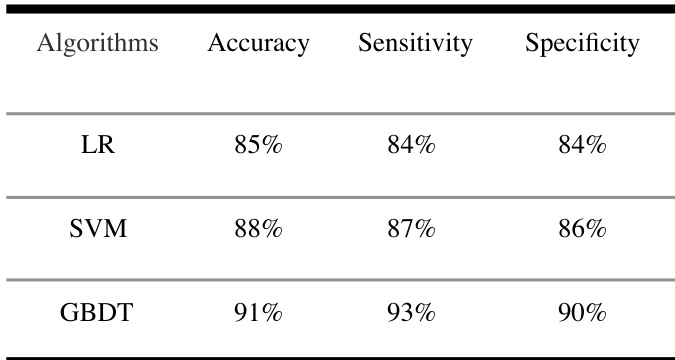
研究团队使用血液常规数据集对比了逻辑回归、SVM与GBDT等不同机器学习算法的性能。结果表明,相较于另外两种模型,GBDT算法在准确率、灵敏度与特异度上均表现更优。GBDT在准确率、灵敏度与特异度方面全面超越LR与SVM。在对比模型中,GBDT算法展现出最高的灵敏度。SVM在所有评估指标上的表现均优于LR。
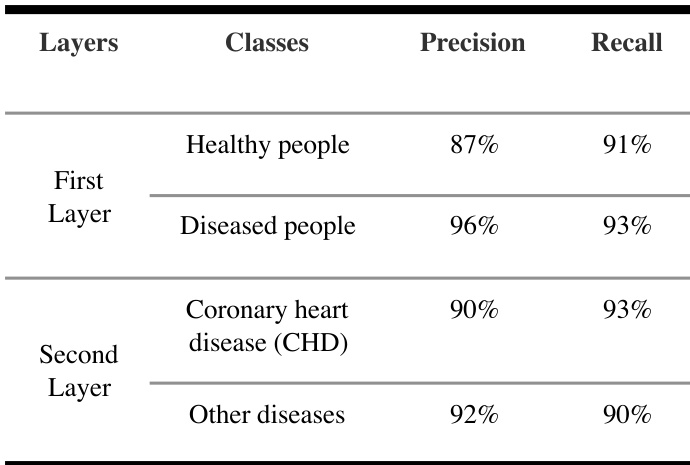
{"summary": "研究团队开发了一种两层GBDT模型,利用常规血液检测数据对健康状态、冠心病及其他疾病进行分类。该模型在两层分类中均实现了高精度与高召回率,第一层区分健康个体与患病人群,第二层进一步将患病病例细分为冠心病与其他疾病。结果表明,该两层方法的表现与直接三分类模型相当,同时为临床应用提供了可解释性。", "highlights": ["两层GBDT模型在第一层区分健康个体与患病人群时实现了高精度与高召回率。", "在第二层中,该模型在识别冠心病与其他疾病方面继续保持强劲性能。", "模型的分类结果与研究中报告的整体性能一致,支持其用于临床风险预测。"]
研究团队使用血液常规数据对比了多种用于分类健康状态、冠心病及其他疾病的机器学习算法。GBDT模型在对比模型中取得了最高的准确率与灵敏度,表明其在识别健康个体与冠心病患者方面性能强劲。GBDT模型在准确率与灵敏度两方面均优于LR与SVM。该模型在识别健康个体与冠心病患者时均实现了高灵敏度。两层GBDT模型利用常规血液检测数据对健康状态、冠心病及其他疾病进行分类的效果显著。
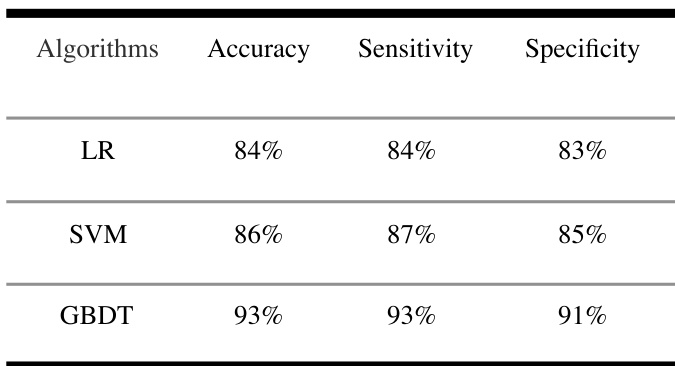
研究团队利用常规血液检测数据开发了双层GBDT模型以预测冠心病,其性能与三分类模型相当。结果表明,该模型以高精度与高召回率识别出冠心病患者,且该方法揭示了血液检测数据中可能具有临床意义的一致性模式。模型在健康与疾病类别上均展现出强劲的灵敏度。双层GBDT模型在冠心病检测方面实现了高精度与高召回率。该模型在识别健康个体与冠心病患者时表现出高灵敏度。该方法揭示了常规血液检测数据中的一致性模式,可为临床参考提供价值。

实验利用常规血液检测数据对比了多种机器学习算法,以分类健康状态与特定心血管疾病。这些评估验证了层级双层GBDT架构相较于直接多分类方法的有效性,重点强调了分类可靠性与临床可解释性。结果一致表明,GBDT在所有性能维度上均显著优于逻辑回归与支持向量机。最终,该双层框架被证明在疾病分层方面高度有效,其准确率与直接分类相当,同时为常规健康体检提供了透明且具有临床可操作性的洞察。