Command Palette
Search for a command to run...
用 Bahdanau 和 Luong Attention 直观介绍神经机器翻译
摘要
一句话总结
一种用于低资源神经机器翻译的简单迁移学习方法:在训练高资源父模型后,仅通过替换训练语料库继续在低资源语言对上训练,从而生成子模型。该方法在不要求共享目标语言或具备语言亲缘关系的情况下,在无关语言及不同书写系统上均能取得显著优于基线模型的性能。
核心贡献
- 本文提出了一种简化的神经机器翻译迁移学习方法。该方法通过替换高资源父模型的训练语料库,使子模型直接在低资源语言对上继续训练,无需特殊的预处理或调整训练计划。
- 该方法突破了先前迁移学习的限制,证明了在不同字母系统且无关的语言之间能够有效转移知识,并允许父模型与子模型的目标语言不同。
- 基于 Transformer 架构的实验表明,经过适配的子模型性能显著优于仅使用低资源数据训练的基线模型。
引言
神经机器翻译虽能取得最先进的结果,但在平行训练数据低于一百万句时通常会失效。迁移学习通过复用高资源语言对的知识来解决这一低资源瓶颈,但先前的方法通常要求共享目标语言、具备语言亲缘关系,或需要复杂的训练调整与特殊预处理。本文作者利用一种基于 Transformer 架构的简化迁移学习策略,先在高质量语言对上训练父模型,随后仅通过更换数据集即可无缝继续在低资源语言对上训练。该方法在不依赖自定义训练策略或数据操作的情况下,能够在不同书写系统的无关语言之间,甚至目标语言发生改变时,带来显著的性能提升。
数据集

- 数据集构成与来源: 作者构建了一个涵盖低资源、高资源及无关语言对的多语言训练语料库,用于评估神经机器翻译中的迁移学习效果。数据集主要来源于 WMT 共享任务、Europarl、Rapid、CzEng 1.7、News Commentary、Yandex 以及联合国语料库。爱沙尼亚语-英语和斯洛伐克语-英语作为低资源目标语言对,芬兰语-英语和英语-捷克语作为高资源基线。俄语-英语作为父模型训练源,阿拉伯语-俄语、法语-俄语、西班牙语-法语和西班牙语-俄语语言对用于评估向无关语言的跨语言迁移效果。
- 子集详情:
- 爱沙尼亚语-英语:基于 Europarl 和 Rapid 数据训练;在 WMT 2018 新闻数据上进行验证和测试。
- 芬兰语-英语:遵循既定协议准备,移除了维基百科标题;在 WMT 2015 新闻数据上进行验证和测试。
- 英语-捷克语:基于 WMT2018 许可的平行数据构建(排除 Paracrawl),补充经过过滤的 CzEng 1.7;在 WMT newstest2011 上验证,在 WMT newstest2017 上测试。
- 斯洛伐克语-英语:源自 Galuščákova 和 Bojar (2012),并使用 Moses 进行反词元化;在 WMT newstest2011 上验证和测试。
- 俄语-英语:整合自 News Commentary、Yandex 和联合国语料库;在 WMT newstest 2012 上验证。
- 无关语言对:完全源自联合国语料库。
- 确切的训练句数因语言对而异,详见论文参考文献表。
- 数据使用与处理: 作者通过拼接父模型和子模型的训练语料库生成共享的子词词表。在构建词表时,强制要求源语言和目标语言保持严格的 1:1 句子比例,以平衡两种语言对。词表目标约为 32k 个子词类型,实际词表大小在 26.1k 至 34.8k 之间。同一语言集内的所有实验共享完全相同的词表。采用字节对编码(Byte pair encoding)或 wordpieces 处理未登录词并优化序列效率。
- 过滤与裁剪策略: 移除源语言或目标语言端包含少于 4 个或超过 75 个单词的训练句子。此长度限制可加速 Transformer 训练并允许使用更大的批次大小,且不会对翻译质量产生负面影响。开发集和测试集保持未过滤状态以保留评估保真度。作者还因噪声问题在相关语言对中排除了 Paracrawl 语料库。
方法
本文采用一种简明的神经机器翻译迁移学习方法,先在高质量语言对上训练模型(称为父模型),随后在低资源语言对上继续训练(称为子模型),且过程中不重置任何模型参数或超参数。该方法借鉴了 Zoph 等人(2016)提出的迁移学习框架,但不同之处在于采用了 Nguyen 和 Chiang(2017)提出的跨两种语言对共享的子词词表。核心创新在于取消了父模型与子模型语言对必须具备亲缘关系的限制,证明了即使在完全无关的语言对之间也能实现有效的知识迁移。该方法适用于源语言和目标语言两侧,不仅限于目标语言共享的情况。
该方法无需对现有神经机器翻译框架进行修改。唯一必要的条件是使用共享的子词词表,该词表使用 word-piece 分割技术(Johnson 等人,2017)构建,训练数据为父模型和子模型语言对的拼接源端与目标端。词表在 Transformer 架构的编码器与解码器之间共享,以实现潜在的信息复用。训练过程中,模型首先在父模型语言对上训练至收敛。随后,将该训练好的模型作为子模型语言对训练的初始化模型,仅切换训练语料库。整个过程中其他所有训练参数保持不变。
实验
评估采用 Transformer 序列到序列模型,以检验在不同高资源父模型与低资源子模型语言对之间的迁移学习效果。实验表明,对父模型进行微调能显著提升子模型的翻译质量,且性能提升主要受父模型训练数据量的驱动,而非语言亲缘关系或共享书写系统。该方法即使在子模型数据极其有限、翻译方向反转或无共享语言的情况下依然有效,前提是父模型已完全收敛。最终研究结果证实,利用更大的预训练模型是在低资源环境中部署神经机器翻译的高度可靠策略。
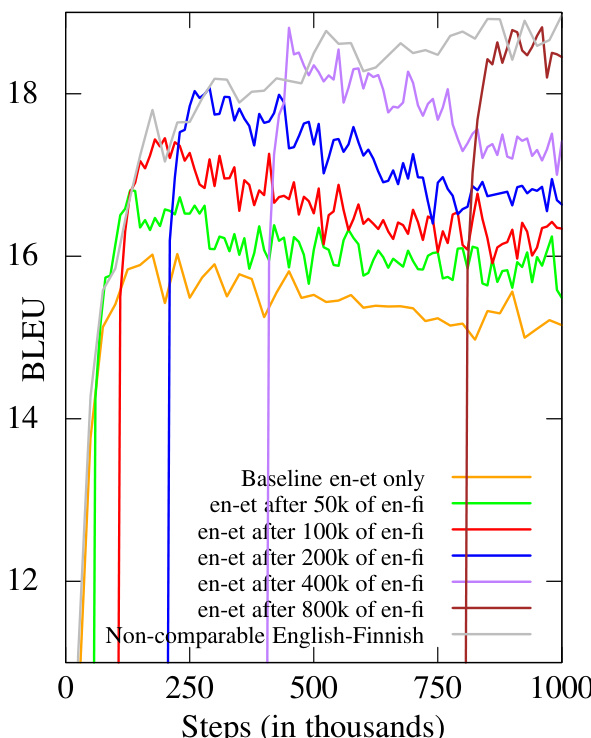
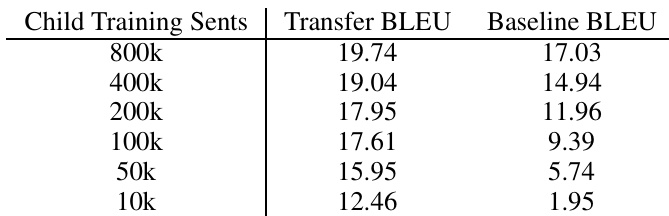
作者通过在减少的数据集上训练子模型(使用预训练父模型进行初始化)来研究神经机器翻译中的迁移学习。结果表明,迁移学习方法在各类子模型训练数据量级下均持续优于基线模型,且随着子模型数据量的增加,性能进一步提升。性能提升并非仅由输出长度增加所致,n-gram 精度提高以及引入新的、符合上下文的 tokens 也带来了改进。与仅在减少的数据集上从头训练相比,迁移学习持续提升了翻译性能。子模型训练数据量越大,提升效果越明显。提升并非仅源于输出变长,n-gram 精度同样得到改善。
作者使用多种指标对比了从头训练的子模型与使用父模型初始化的子模型的翻译性能。结果表明,使用父模型初始化在多项评估指标上均带来提升,最佳配置在 BLEU、nPER、nTER、nCDER、chrF3 和 nCharacterTER 上的得分均高于基线。使用父模型初始化子模型可跨多项指标提升翻译质量。最佳配置在 BLEU、nPER、nTER、nCDER、chrF3 和 nCharacterTER 上的得分均优于基线。改进在不同评估指标上保持一致,表明迁移学习带来了稳健的性能提升。

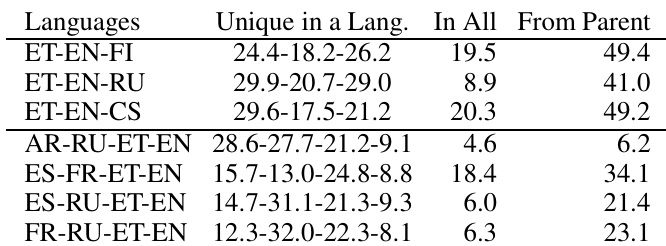
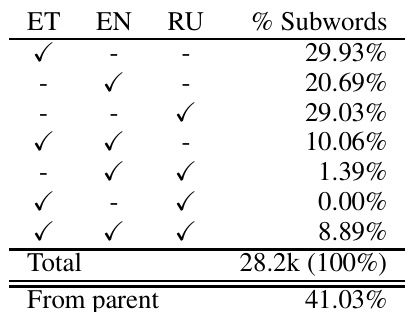
作者分析了涉及爱沙尼亚语、英语和俄语的翻译实验中子词词表的构成,重点关注各语言对总词表的贡献。结果表明,父模型贡献了词表的大部分,且子词单元在各语言间存在显著重叠。分析显示,词表主体来源于父模型,表明迁移学习有效利用了父模型的语言资源。父模型贡献了实验中大部分子词词表。各语言间的子词单元存在显著重叠,尤其是英语与爱沙尼亚语之间。总词表主要由父模型贡献主导,表明语言资源得到了有效迁移。
作者通过使用父模型改进子模型来评估神经机器翻译中的迁移学习,结果表明跨多种语言对均取得一致的性能提升。即使父模型与子模型语言无共享词表或彼此无关,仍能观察到性能提升,这表明父模型语料库的大小比语言亲缘关系更为重要。结果还凸显了该方法在低资源设置下的有效性,且受益于已收敛的父模型。迁移学习在不同语言对之间持续提升翻译性能,即使语言无关亦如此。父模型训练数据的大小比语言亲缘关系对取得性能提升更为重要。该方法在低资源场景中有效,且受益于训练充分的父模型。
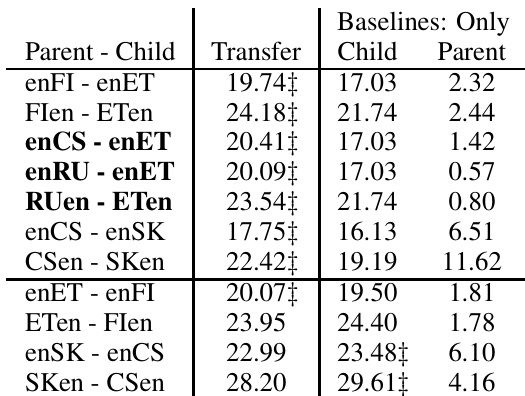
作者通过对比基线模型与使用父模型初始化的模型,分析了迁移学习对翻译性能的影响。结果表明,迁移学习方法带来了 BLEU 分数和输出长度的提升,且增益主要归因于更好的 n-gram 精度,而非输出长度增加。不同父模型下的改进保持一致,表明父模型语料库的大小在提升翻译质量方面起重要作用。迁移学习相比基线模型提升了 BLEU 分数和输出长度。增益主要源于更好的 n-gram 精度,而非输出长度增加。不同父模型下的改进保持一致,表明语料库大小比语言亲缘关系更重要。

实验通过在预训练父模型上初始化子模型,并在不同数量的目标数据上进行训练,来评估神经机器翻译中的迁移学习。在多个验证阶段中,该方法持续提升翻译质量,表明性能提升源于 n-gram 精度的改善和有效的词表迁移,而非输出长度增加。此外,语言学与跨语言学分析证实,父模型语料库大小在驱动结果方面优于语言亲缘关系,验证了迁移学习作为低资源翻译场景下高度有效策略的地位。