Command Palette
Search for a command to run...
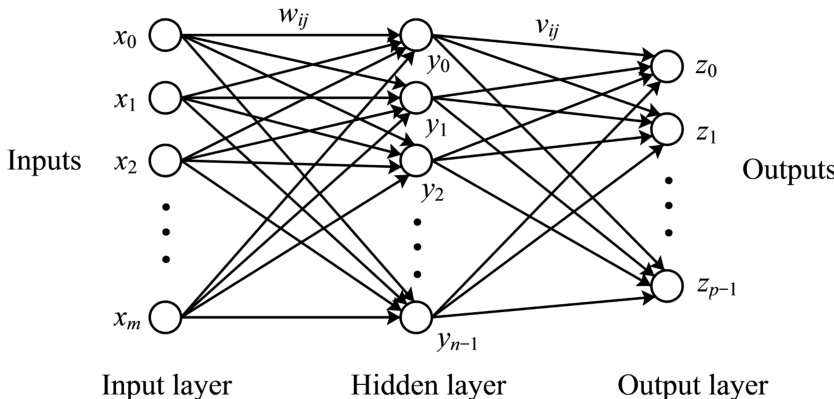
多层感知器
摘要
一句话总结
本文提出了一种量子多层感知机模型,该模型利用量子态制备处理层输出,并采用量子权重学习算法,在经典算法基础上实现至少二次或指数级加速,从而为量子机器学习提供高效框架,并启发了一种基于赫布理论的Hopfield网络指数级学习方法。
核心贡献
- 量子多层感知机模型通过量子比特振幅将输入向量和权重向量编码为量子态,仅需 O(logn) 个量子比特即可支持任意实值信号。
- 并行交换测试技术将多层感知机的非线性架构整合至量子电路中,实现了在线与批量权重学习算法的高效运行。
- 该框架在网络推理与参数更新方面相较于经典方法实现至少二次或指数级加速,并可扩展至为Hopfield网络中的赫布学习提供指数级加速。
引言
多层感知机作为图像识别和机器翻译等关键应用的基础前馈神经网络,其量子化适配已成为量子机器学习领域极具价值的前沿方向。然而,将这些非线性架构与量子计算相结合一直面临挑战,因为先前的模型在权重更新时要么违反量子幺正性,要么需要线性扩展的量子比特数量,从而将输入限制为二进制值。为突破这些瓶颈,研究团队采用振幅编码方案,仅使用对数量级的量子比特资源将输入向量和权重向量表示为量子态。他们引入并行交换测试技术来高效计算点积并应用非线性激活函数,从而实现了前向传播与权重训练算法的量子化部署。该框架相较于经典方法提供至少二次或指数级加速,并可自然扩展以加速Hopfield网络中的赫布学习。
数据集

- 数据集构成与来源: 研究团队构建了一个量子数据集,包含输入向量、目标输出以及编码为归一化量子态的神经网络权重参数。这些量子态通过酉算子以算法方式生成,而非从外部存储库中获取。
- 各子集关键细节: 数据以大小为 d 的批次组织,加载至均匀叠加态 d1∑t=0d−1∣t⟩ 中。每个态的制备时间复杂度为 O(Tin)。该框架不采用传统的过滤或裁剪规则,因为这些态在数学上已归一化,并直接映射至模型的输入与参数维度。
- 模型中的数据使用: 研究团队利用这些量子态对量子多层感知机的输出层与隐藏层权重进行批量训练。通过并行交换测试估算输入态与权重态之间的内积,从而在无需经典数据打乱或固定训练划分的情况下,实现高效的梯度估算与权重更新。
- 处理与态管理: 处理流程依赖并行态制备、受控旋转与量子相位估计,将内积值编码至辅助寄存器中。计算完成后,应用逆操作以撤销中间态并恢复干净寄存器。所有处理步骤均经过优化,以维持量子相干性,并在 O(Tin/ϵ) 的运行时间内达到 ϵ 的估计精度。
方法
多层感知机的量子模型通过扩展量子态制备与量子并行性原理构建,旨在模拟经典神经网络的结构与学习动态。该框架利用量子算法高效计算内积与非线性函数,从而实现多层感知机前向传播与学习阶段的模拟。整体架构包含三个核心部分:输入与权重向量的量子态制备、用于计算输出的网络前向传播量子模拟,以及用于更新权重的在线学习算法量子实现。
流程始于表示网络参数与输入的量子态制备。输入向量 x 与权重向量 wi 通过高效量子算法编码为量子态 ∣x⟩ 与 ∣wi⟩。这些算法基于线性组合酉算子(LCU)技术,可在 O(κ(x)logm) 时间内制备与给定向量成比例的量子态,其中 κ(x) 为该向量的条件数。此步骤是将经典数据以量子形式进行访问的基础。
多层感知机的前向传播通过计算各层输出来模拟。针对隐藏层,研究团队采用并行化方法生成输出向量 y 的量子态。具体实现方式为:首先制备隐藏单元的叠加态,随后应用受控操作生成一个并行包含归一化输入向量 ∣x⟩ 与各权重向量 ∣wi⟩ 的态。接着应用并行交换测试同时计算所有 i 对应的内积 x⋅wi。该内积用于计算Sigmoid函数 φ(x⋅wi),随后通过受控旋转将其编码为量子态。最终结果为一个与输出向量 y 成比例的量子态。该方法相较于经典方法实现指数级加速,时间复杂度为 O((logmn)/ϵ)。
输出层的模拟采用类似方式。隐藏层输出的量子态 ∣Y⟩ 作为输入。该过程涉及制备输出单元的叠加态,并应用受控操作将 ∣Y⟩ 与各输出层权重向量 ∣vi⟩ 结合。使用并行交换测试计算内积 y⋅vi,进而计算Sigmoid函数并将结果编码为量子态。由此得到最终输出向量 z 的量子态,时间复杂度为 O((logmnp)n/ϵ2)。
学习算法以在线学习过程的形式实现,每次迭代仅基于单个训练样本来更新权重。输出层权重 vj 的更新规则包含一个与 (rjt−zjt)zjt(1−zjt)yt 成比例的项。该过程通过制备结合当前权重向量 ∣ψjold⟩ 与隐藏层输出量子态 ∣Yt⟩ 的量子态来进行模拟。应用受控操作生成一个在叠加态中包含更新后权重向量 vjnew 的态。施加Hadamard变换以提取新的量子态 ∣vjnew⟩。该流程避免了直接测量,从而防止复杂度增加,并使算法能够维持较低的计算成本。该在线学习算法的时间复杂度为 O(N3/2(logmn)n/ϵ2),相较于经典算法在 n 维度上提供二次加速,在 m 维度上提供指数加速。