Command Palette
Search for a command to run...
无监督文本选择
摘要
一句话总结
本文提出了一种无监督自动语音识别框架,该框架仅使用未对齐的语音和文本数据进行训练。首先,通过序列到序列自编码器提取音素与说话人解耦的向量表示;其次,利用 skip-gram 模型生成语义音频嵌入;最后,通过无监督变换将这些嵌入映射到文本嵌入空间中的词汇。
核心贡献
- 提出了一种无监督自动语音识别框架,处理未对齐的音频和文本语料库,生成词级转写结果。
- 通过序列到序列自编码器提取音素与说话人无关的向量,并利用 skip-gram 模型将其映射为语义嵌入,从而构建声学语义表示。
- 通过迭代变换算法将音频嵌入对齐至文本嵌入空间,在无需人工监督的情况下,在朗读英语语音数据集上实现了词级预测。
引言
自动语音识别赋能了无数应用,但其对高成本音频-文本对齐的依赖严重限制了其在低资源或新型语言环境中的部署。以往的方法通常依赖对齐语料库,或难以在无监督条件下提取能够有效桥接声学数据与文本数据的语义表示。作者利用对抗性序列到序列自编码器分离出纯净的音素嵌入,随后应用 skip-gram 框架从无标注音频中推导语义向量。通过共享变换空间将这些音频嵌入与标准文本嵌入进行迭代对齐,仅使用未对齐的语音和文本数据便实现了词级语音识别,代表了该任务首个完全无监督的解决方案。
方法
所提出的无监督自动语音识别(ASR)框架分为三个独立阶段,旨在逐步从未对齐的音频和文本数据中提取并对齐语义信息。整体架构设计用于从音频片段中解耦音素与说话人特定特征,从这些特征中学习语义嵌入,随后将生成的音频语义表示映射至文本语义空间,整个过程无需依赖对齐的音频-文本对。
第一阶段专注于从词级音频片段中提取音素嵌入,同时解耦说话人特定信息。给定一组音频片段,每个片段由两个独立的编码器处理:音素编码器 Ep 和说话人编码器 Es。这两个编码器旨在分别从输入声学特征中提取音素向量 vp 和说话人向量 vs。两个编码器的输出随后被送入解码器,用于重构原始声学特征。主要目标是最小化重构损失 Lr,该损失定义为原始特征与重构特征之间平方差的总和,从而确保编码器的组合输出保留足够的信息以实现精确重构。
为实现音素与说话人信息的解耦,框架采用了两种不同的训练准则。说话人编码器 Es 的训练旨在最小化损失 Ls,该损失促使同一说话人片段的嵌入在嵌入空间中保持靠近,同时通过间隔 λ 使不同说话人的嵌入向量相互分离。这通过结合用于同说话人对的均方误差项与用于不同说话人对的铰链损失项来实现。同时,音素编码器 Ep 的训练旨在“欺骗”判别器 D,该判别器试图分类两个音素向量是否源自同一说话人。判别器的训练目标是最大化损失 Ld,该损失衡量同说话人对不同说话人对预测概率的差异,而音素编码器则训练以最小化该损失。这种对抗性训练确保音素向量 vp 仅包含音素信息,因为说话人信息已被有效编码在独立的 vs 向量中。整个优化过程迭代最小化 Lr+Ls−Ld,以平衡重构、说话人一致性与音素解耦。
第二阶段利用提取的音素嵌入来学习语义嵌入,其原理类似于自然语言处理中的 skip-gram 模型。给定某一片段的音素向量 vpi,语义编码器 Esem 将其映射为语义嵌入 vwi。对于每个片段,定义一个包含相邻片段的上下文窗口,并将这些上下文片段的音素向量输入上下文编码器 Econ,生成上下文嵌入 vcj。训练目标是最大化某一片段的语义嵌入与其相邻片段上下文嵌入之间的相似度,同时最小化非上下文对的相似度。这通过最小化语义损失 Lsem 来实现,该损失利用点积的 Sigmoid 函数衡量相似度,并引入负采样以在负样本子集上高效训练。该过程确保具有相似上下文模式的片段被映射到语义空间中的邻近点,从而捕捉其共享的语义含义。
最后阶段执行无监督变换,将学习到的音频语义嵌入与文本语义嵌入对齐。框架接收从文本语料库获得的一组音频语义嵌入 Vw 和一组文本语义嵌入 Uw。由于这些嵌入存在于不同的语义空间中,需学习一种变换将一方映射至另一方。该过程采用 MBC-ICP 算法实现,首先通过 PCA 将两组嵌入投影至其前 K 个主成分,生成矩阵 A 和 B。随后迭代学习一对变换矩阵 Tab 和 Tba。算法在投影空间之间寻找最近邻,并优化变换矩阵以最小化某点与其在另一空间中变换后最近邻之间的距离。引入循环约束以确保将点变换至另一空间再返回后仍能得到几乎相同的点,从而促进一致且稳定的映射。变换学习完成后,音频片段可被映射至文本语义空间,对应的文本词被识别为其嵌入为最近邻的词,从而有效实现词级识别。
实验
评估设置采用标准基准数据集来测量音频与文本嵌入之间的语义相关性,并结合变换精度测试以评估跨模态对齐效果。这些实验验证了引入解耦与语义训练能显著提升音频嵌入的表示质量,证实了初始提取阶段的有效性。后续的对齐测试表明,尽管完全无监督方法难以识别最优映射,半监督方法却能成功建立音频与文本空间之间稳健的仿射变换。最终,研究结果表明所提出的框架有效桥接了两种模态,为未来完全无监督的语音识别系统奠定了坚实基础。
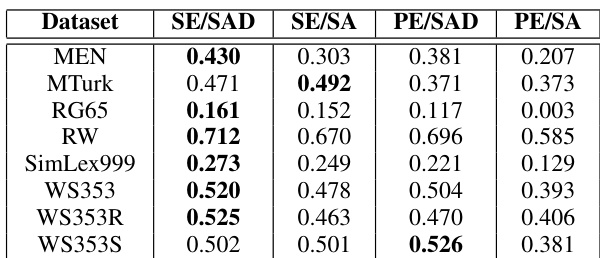
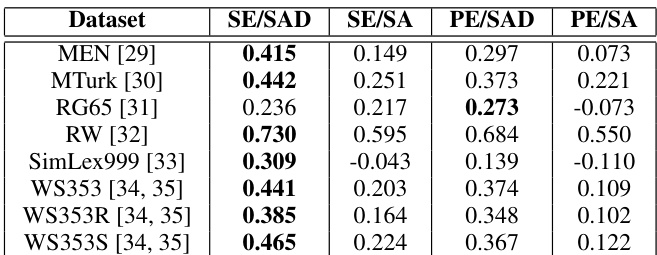
作者通过多个数据集上的相关性分数评估音频与文本语义嵌入的对齐效果。结果表明,解耦的音频语义嵌入始终优于未解耦的嵌入,且在可用标签数据时,所提方法能达到更高的变换精度。研究结果指出,仿射变换可有效将音频嵌入映射至文本嵌入,半监督学习在此过程中表现尤为突出。在所有数据集中,解耦的音频语义嵌入与文本嵌入的相关性均高于未解耦的嵌入。当使用带有标签对的半监督学习时,所提方法展现出更高的变换精度。音频语义嵌入在捕捉语义相似性方面优于音素嵌入,相关性分数也更高。
作者在多个数据集上评估音频与文本语义嵌入的相关性,并对比不同嵌入类型。结果表明,解耦语义嵌入通常优于未解耦嵌入,且音频语义嵌入在大多数情况下优于音素嵌入。表现最佳的方法在各种基准测试中均取得最高相关性,印证了所提框架的有效性。在变换阶段,半监督学习相比无监督方法显著提升了精度,表明音频与文本嵌入间存在仿射变换,但在缺乏标签数据时难以学习。在大多数数据集中,解耦语义嵌入与文本嵌入的相关性高于未解耦嵌入。音频语义嵌入在捕捉与文本的语义相似性方面始终优于音素嵌入。半监督学习相比无监督方法显著提高了变换精度,进一步印证了音频与文本嵌入间仿射变换的存在。
作者评估了不同音频嵌入方法在捕捉语义信息并将其转换为文本表示方面的性能。结果表明,解耦提升了与文本嵌入的相关性,且半监督学习相比无监督方法取得了更高的变换精度。表现最佳的方法在两项评估指标上均持续展现优越性能。在大多数情况下,解耦提升了音频与文本嵌入间的相关性。音频语义嵌入在多数场景中优于直接从语音分析中提取的嵌入。半监督学习实现了比无监督方法更高的变换精度。

作者通过相关性分析与变换精度评估音频语义嵌入在捕捉类似文本语义信息方面的有效性。结果表明,解耦提升了相关性分数,且半监督学习相比无监督方法获得了更高的变换精度,表明在拥有标签数据的情况下,音频与文本嵌入间的仿射变换是可行的。在大多数情况下,解耦提升了音频与文本嵌入间的相关性。半监督学习实现了比无监督学习更高的变换精度。音频语义嵌入在多数场景中优于直接从语音分析中提取的嵌入。
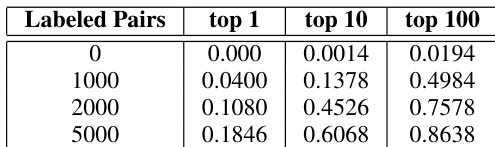
实验通过测量多个数据集上音频与文本语义嵌入的相关性,以及将音频表示映射至文本的精度,来评估跨模态对齐效果。初始验证对比了嵌入架构,证明解耦的音频语义表示比未解耦或音素替代方案能更有效地捕捉语言含义。后续评估检验了模态间仿射变换的可行性,证实半监督学习相比无监督方法能大幅提升映射精度。综上所述,这些结果表明,语义解耦结合有限的标签数据能够实现稳健且精确的音频到文本对齐。