Command Palette
Search for a command to run...
空间变换网络(Spatial Transformer Networks)
摘要
一句话总结
ST-GAN 是一种生成对抗网络,采用空间变换网络作为生成器,用于计算前景与背景合成所需的逼真几何形变参数。通过在参数空间中直接优化变换,并结合迭代形变方案与顺序训练策略,该方法在性能上优于简单的单生成器基线模型,同时支持室内家具可视化与配饰试穿等高分辨率应用。
核心贡献
- 本文提出了空间变换生成对抗网络(ST-GAN),该框架将空间变换网络与对抗学习相结合,用于计算图像合成中前景对象的逼真几何校正参数。通过在低维形变参数空间中运行,该架构能够生成将插入对象与背景场景对齐的变换。
- 采用顺序对抗训练策略,将大幅度的空间变换分解为迭代形变步骤,以稳定生成器与判别器之间的极小极大博弈。与简单的单生成器训练相比,这种多阶段方法提升了几何调整的收敛速度与精度。
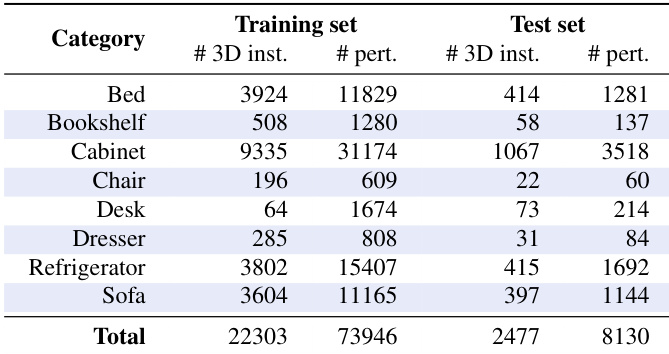
- 该框架在用于室内家具摆放的配对合成数据集以及用于肖像配饰插入的非配对真实数据集上进行了评估。大规模用户研究证实了视觉真实感的显著提升,且可迁移的形变参数使其能够有效应用于高分辨率图像。
引言
生成对抗网络已推动逼真图像合成技术的发展,但直接进行像素级生成仍受限于高维数据空间与有限的网络容量。这些模型经常难以处理几何差异,导致在图像合成等实际应用中可靠性不足,因为源对象必须无缝融入新环境。为克服这些局限,研究者在 GAN 框架中引入空间变换网络,提出 ST-GAN 这一新颖架构。该架构通过学习迭代几何形变而非直接预测像素来生成逼真输出。借助顺序对抗训练策略,模型逐步校正空间变换,使合成图像对齐到自然图像流形上,在配对与非配对合成任务中均实现了显著增强的真实感。
方法
本文提出一种新颖的生成对抗网络(GAN)架构,称为空间变换生成对抗网络(ST-GAN),旨在解决图像合成中的逼真几何校正问题。该框架通过学习调整前景对象的几何参数,使其在合成到指定背景图像时呈现自然效果。模型核心采用空间变换网络(STN)作为生成器,支持基于前景与背景输入的可微图像形变。这使得网络能够预测几何校正参数,充分考量对象与目标场景之间的复杂交互,包括透视、位置与朝向。
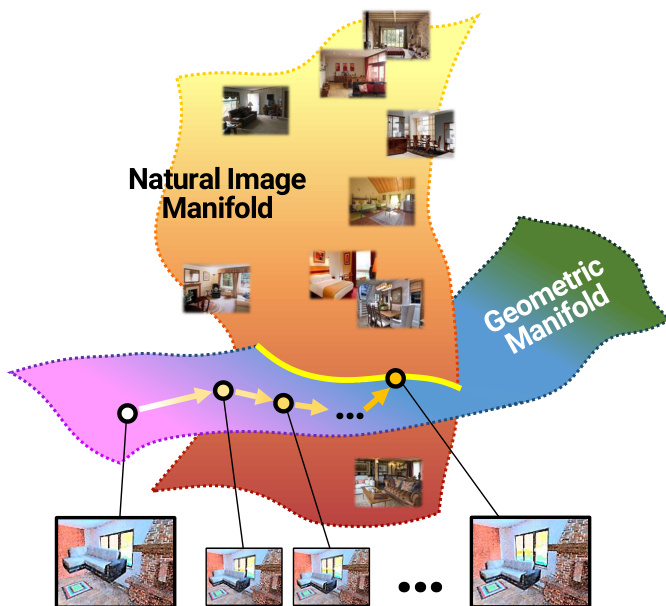
参见框架示意图以了解整体流程概述。合成图像通过将前景对象(根据一组参数 p 进行掩码与形变)叠加到背景图像上形成。模型的目标是寻找一系列几何形变更新步骤,将初始合成图像转化为位于自然图像流形内的图像。几何形变函数被限制为单应性变换,并使用 sl(3) 李代数进行参数化。该参数化方法使得形变参数可通过简单加法进行组合,这是迭代过程的关键特性。
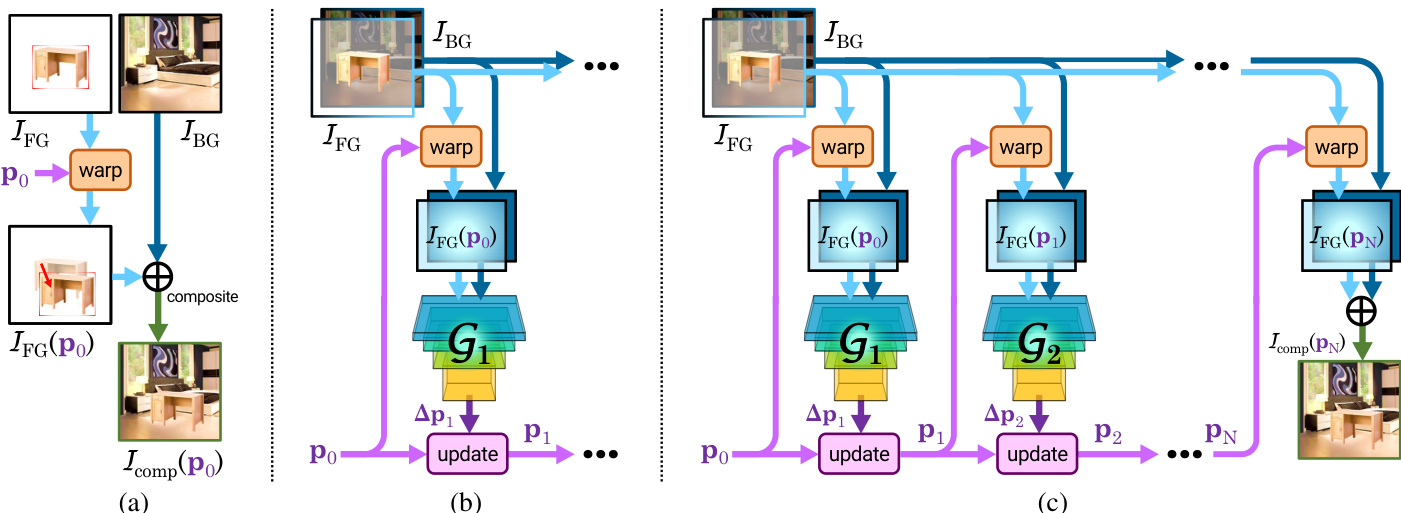
如图所示,模型采用迭代方式预测一系列增量形变更新。在每次迭代 i 中,几何预测网络 Gi 以形变后的前景图像 IFG(pi−1) 和背景图像 IBG 作为输入,预测校正量 Δpi。新的形变状态 pi 随后通过组合前一状态 pi−1 与更新量 Δpi 获得。这种迭代细化机制使模型能够将复杂的几何变换分解为更小、更易处理的步骤进行学习。
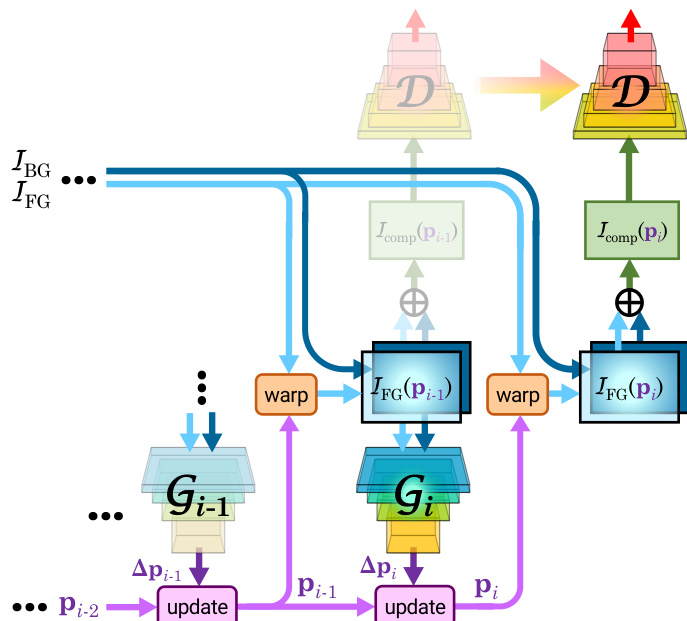
为训练网络,研究者将迭代 STN 整合至 GAN 框架中。生成器 Gi 输出低维形变参数更新而非完整图像,判别器 D 则评估最终合成图像的真实性。一项关键创新在于顺序对抗训练策略。训练从单个生成器 G1 开始,随后逐个添加后续生成器 Gi。在训练每个新生成器 Gi 时,所有先前训练过的生成器权重均保持固定。所有阶段共用同一判别器 D,持续学习区分真实与伪造的合成图像。该方法确保每个生成器都能学习产生有意义的校正,并基于前序阶段的工作进行构建,从而实现更快且更稳健的训练。
对抗目标基于 Wasserstein GAN(WGAN)公式,相较于传统 GAN 提供更稳定的训练过程。判别器的损失函数包含梯度惩罚项,以强制满足 1-Lipschitz 约束。为防止前景对象被简单移除的平凡解,引入针对形变更新量 Δpi 幅度的惩罚项,将其约束在信任区域内。在顺序训练期间,判别器与当前生成器 Gi 交替更新。所有生成器训练完成后,对整个网络进行端到端微调,以优化最终合成图像。
生成器 Gi 实现为卷积神经网络,架构为 C(32)-C(64)-C(128)-C(256)-C(512)-L(256)-L(8),其中 C(k) 表示包含 k 个滤波器的二维卷积层,L(k) 表示包含 k 个输出节点的全连接层。Gi 的输入由前景与背景图像组成,形成 7 通道输入。判别器 D 采用 PatchGAN 架构,对局部图像块进行真实性分类。模型在调整大小为 120×160 的图像上进行训练,但所学形变参数可在测试时迁移至全分辨率图像,使该方法能够应用于高分辨率合成任务。
实验
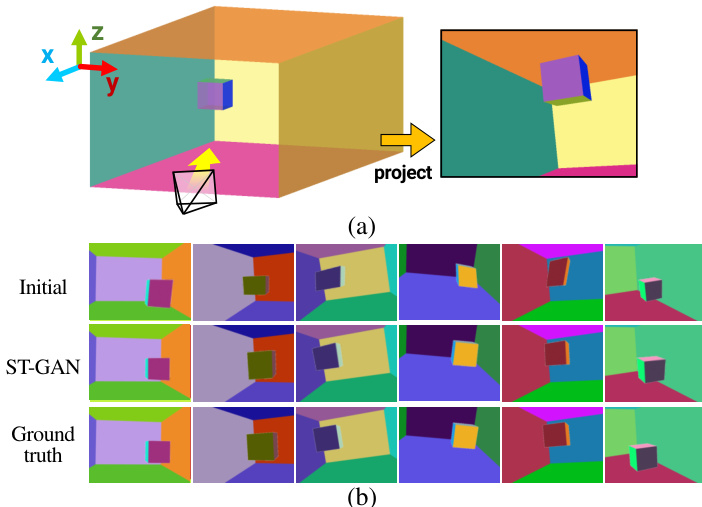
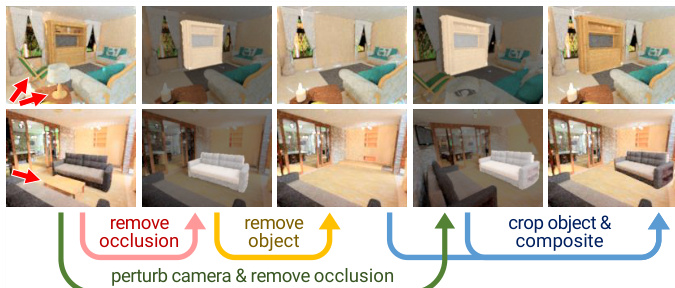
第一个实验通过对渲染的 3D 立方体施加随机单应性变换并进行扰动,以原始真实标签为基准进行训练,验证了模型校正几何畸变的能力,同时捕捉逼真放置位置的多模态分布。第二个实验在完全非配对设置下进行,使用人脸图像与手工制作的眼镜,测试系统在不依赖结构标注的情况下逐步将合成图像形变至自然位置的能力。定性来看,该方法在适度变换下能成功对齐前景元素,但在极端面外旋转时表现不佳,最终证明了其在获取配对数据极具挑战性的图像对齐任务中具有巨大潜力。
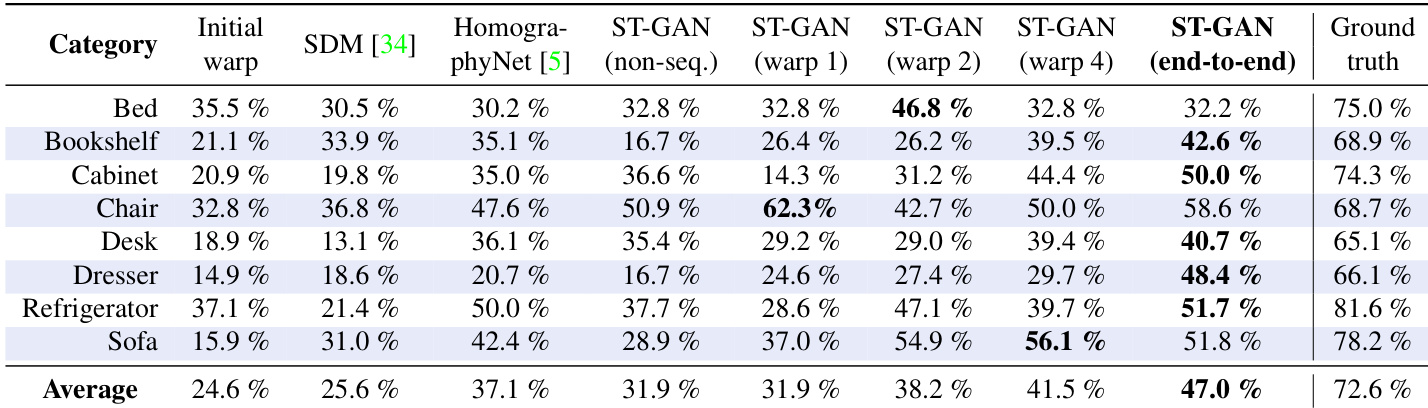
研究者在多种家具类别上评估了 ST-GAN 的性能,并将其与基线方法及 ST-GAN 的不同变体进行比较。结果表明,ST-GAN 始终优于初始形变结果并实现更高的真实感,端到端版本通常优于顺序形变方法。该方法展现出跨类别的鲁棒性,尽管性能存在波动,部分对象改进更为显著。在所有类别中,ST-GAN 均优于基线方法,且真实感高于初始形变结果。端到端 ST-GAN 变体通常表现优于顺序形变版本,尤其在椅子与梳妆台等特定对象上。性能因对象而异,部分类别提升显著,而其他类别则相对温和。
研究者展示了一项在非配对设置下将眼镜合成至人脸的实验,该场景无真实配对数据可用。该方法利用空间变换网络逐步将眼镜形变至人脸上的逼真位置,证明了无需显式结构信息即可对齐对象的能力。结果表明,该方法在处理面外旋转有限的人脸时表现良好,但在更极端的旋转情况下表现不佳。该方法能够在无配对数据或人脸关键点的情况下学习将眼镜形变至人脸。该方法以渐进方式成功对齐眼镜,通过多步迭代提升真实感。对于面外旋转显著的人脸,性能会出现下降。
评估工作涵盖家具分类与非配对人脸-眼镜合成任务,以检验模型在无配对数据或显式关键点条件下生成逼真空间变换的能力。结果表明,端到端变体始终在初始形变基础上提升真实感,且通常优于顺序形变方法,尽管性能增益因对象复杂度而异。在人脸合成实验中,模型成功学会通过迭代形变逐步对齐对象,但对极端面外旋转表现出明显的敏感性。总体而言,研究结果凸显了该方法在非配对空间对齐任务中的强大能力,同时也指出了其在严重几何畸变下的局限性。