Command Palette
Search for a command to run...
加速你的循环神经网络:序列分桶
摘要
一句话总结
作者提出了一种高效的 LSTM 训练算法,该算法通过结合基于序列长度的最优批量桶划分与多 GPU 数据并行化,加速了变长序列的处理,并在在线手写识别任务中从实际耗时、训练轮次及验证损失值三个维度评估了其性能。
核心贡献
- 本文提出了一种高效的循环神经网络训练算法,旨在加速包含高度可变输入序列长度的数据集的 mini-batch 处理。
- 该方法通过实现基于序列长度的最优批量桶划分,并将计算任务分发至多个图形处理器(GPU),从而实现加速。
- 在基于 LSTM 网络的在线手写识别任务中,实验从实际耗时、训练轮次及验证损失值三个维度,将所提方法与未进行桶划分的基线方法进行了对比评估。
引言
循环神经网络(包括 LSTM 和 GRU)在语音识别和自然语言处理等应用的序列建模方面表现优异,但在大规模数据集上进行训练仍面临高昂的计算成本。以往的加速策略已探索了自适应学习率、并行化及专用架构,但这些方法在处理现实世界序列数据固有的变长特性时往往面临挑战。由于 mini-batch 的计算成本由组内最长序列决定,研究人员在按长度对序列进行聚类与维持稳定收敛所需的数据打乱之间面临艰难权衡。为解决这一瓶颈,作者引入了一种序列桶划分算法,该算法能高效组织变长输入,在保障训练稳定性的同时显著加速 mini-batch 梯度下降过程。
数据集

- 数据集构成与来源: 作者使用了包含约 1 GB 原始二进制样本的在线手写识别数据集,涵盖南非荷兰语和英语。数据采集通过使用配备触控笔的 Samsung Galaxy Note 设备完成。
- 子集详情与标注: 验证集由 5% 随机选取的变长样本组成。尽管数据集提供了预期输出序列的文本参考标签,但这些标签并未与对应的手写笔画序列进行显式对齐。
- 数据使用与训练策略: 作者通过 Theano 和 Lasagne 使用 CTC 损失函数训练 LSTM 模型。其实现了一种基于长度的桶划分策略,优先输入较短序列,并在每个 epoch 逐步增加桶数量。训练过程在包含六张 NVIDIA Tesla K40m GPU 的集群上运行。
- 处理与元数据: 原始笔画数据未应用显式的裁剪或对齐预处理。未对齐的文本标签由 CTC 机制隐式处理,该机制在优化过程中学习输入笔画与输出字符之间的映射关系。
方法
作者利用了一种用于循环神经网络(RNN)的并行训练框架,该框架将序列桶划分与多 GPU 数据并行化相结合以加速训练,尤其在输入序列长度差异显著的场景中效果突出。整体训练工作流在多个 GPU 进程间采用 Map-Reduce 范式运行。如下图所示,该流程始于存储在数据仓库中的已计算特征,随后将其传递至主 CPU 进程,该进程负责数据打乱并将其划分为均等部分以分发至各 GPU 进程。各 GPU 进程对其分配的数据子集独立执行序列桶划分,通过按长度对序列进行聚类来优化 mini-batch 处理效率。此步骤缓解了因将较短序列填充至与批次中最长序列等长而导致的效率低下问题,从而降低了计算开销。该桶划分策略通过动态规划算法实现,通过将序列最优地分组至预定数量的桶中,以最小化总处理时间。在各桶内的独立 mini-batch 训练完成后,各 GPU 进程返回其更新后的模型参数。随后,主进程通过归约步骤聚合这些部分模型,以生成最终模型。该框架设计为可扩展至多 GPU 环境,如图所示,并行训练共部署了六张 NVIDIA Tesla K40m GPU。 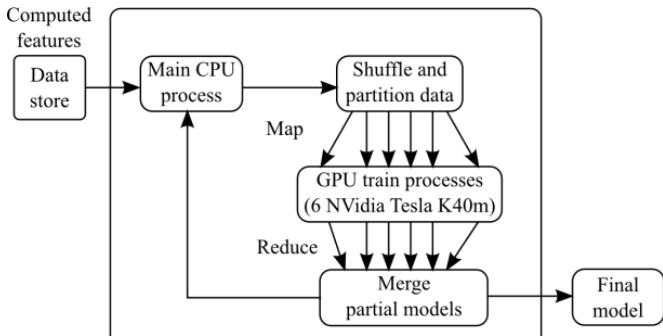
实验
实验设置在不同序列桶划分配置与多 GPU 并行架构下训练 LSTM 模型,以验证其对计算效率与收敛行为的影响。实验结果表明,结构化的序列桶划分显著降低了 epoch 处理时间并加速了初期损失下降,适中的桶配置在训练速度与验证性能之间实现了最佳平衡。此外,与单 GPU 执行相比,将工作负载分发至多个 GPU 能持续提升长期验证准确率。总体而言,这些发现证实,将优化的序列分组与并行硬件相结合,能够大幅简化训练工作流并提升模型收敛效果。
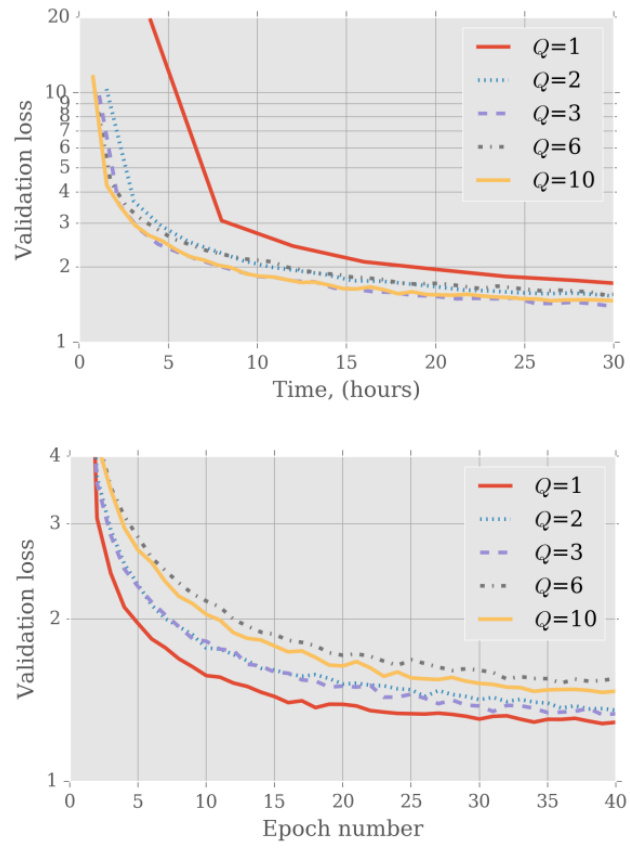
作者研究了序列桶划分对 LSTM 模型训练的影响,分析了不同桶配置下验证损失随时间与 epoch 的变化情况。结果显示,增加桶数量能够提升训练效率与收敛速度,特定桶数量下可获得最佳性能。较高的桶数量使验证损失下降更为迅速,尤其在训练初期阶段。随着桶数量增加,训练速度得到提升,特定配置下收敛速度最快。与基线情况相比,优化的桶划分使验证损失更快趋于稳定。
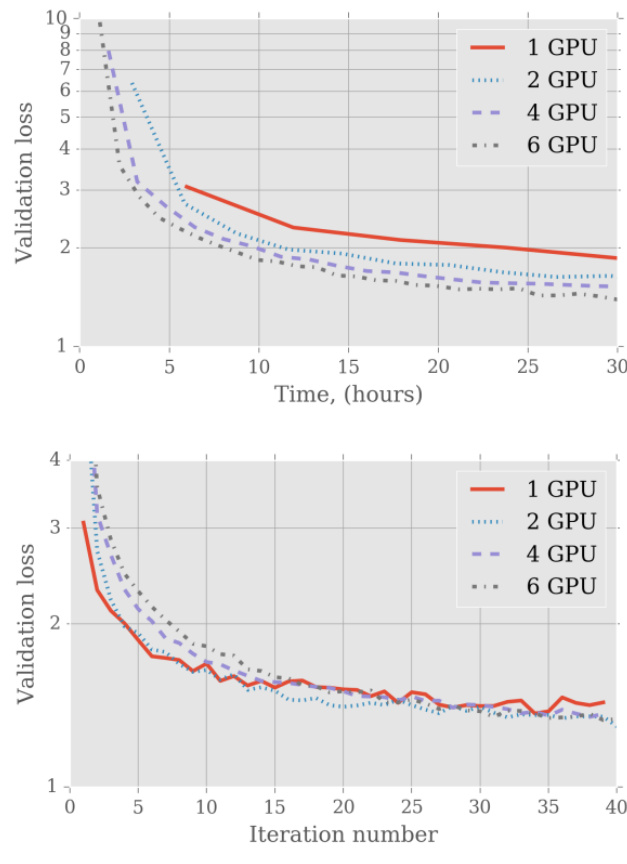
作者进一步探讨了多 GPU 使用与序列桶划分对 LSTM 模型训练的影响,重点关注验证损失与训练速度。结果表明,增加 GPU 数量可随时间推移降低验证损失并加速收敛,使用六张 GPU 时性能最佳。更多 GPU 使验证损失下降更为迅速,尤其在初始训练阶段。使用更多 GPU 可在训练过程中实现验证损失的更快收敛。随着 GPU 数量增加,验证损失下降速度加快,训练早期阶段尤为明显。经过 30 小时训练后,使用六张 GPU 的训练所得验证损失低于使用单张 GPU 的情况。
实验通过系统性地调整序列桶配置并在多 GPU 环境下进行扩展,评估了 LSTM 训练效率,以验证各自对收敛及损失下降的影响。两种策略均能持续加速模型训练并降低验证损失,最显著的提升出现在训练初期阶段。总体而言,本研究证明,策略性优化桶数量并利用并行硬件能够大幅增强训练稳定性与速度,在特定配置阈值下可实现最优性能。