Command Palette
Search for a command to run...
Jigsaw 跨语言恶意留言分类:EDA + 模型
摘要
一句话总结
作者提出了CLANN(跨语言对抗神经网络),该模型采用对抗训练学习具有跨语言不变性且对问答相似性重排序具有判别力的特征,在社区问答场景中,从标注源数据迁移至未标注目标数据时,相较于强大的非对抗基线取得了显著的性能提升。
核心贡献
- 提出了一种用于问答相似性重排序的跨语言适配框架,利用标注的源语言训练数据和仅未标注的目标语言数据。
- 提出跨语言对抗神经网络(CLANN),通过对抗训练学习对相似度匹配具有判别力且在不同输入语言间保持不变的抽象特征。
- 通过实证评估证明,该对抗方法相较于强大的非对抗基线系统带来了显著的性能提升。
引言
本文针对社区问答系统中问答相似性重排序的跨语言适配挑战展开研究。传统构建多语言NLP流水线通常需要昂贵的逐语言标注,或依赖机器翻译,这往往会降低语义质量并引入非预期的情感偏移。为突破这些瓶颈,研究采用对抗训练学习统一表示,该表示在英文和阿拉伯文输入间保持跨语言不变性,同时对相似度分类保持高度判别力。通过将任务特定神经网络与语言判别器结合,并在反向传播中应用梯度反转,CLANN模型仅利用未标注样本即可有效适配目标语言。该方法无需昂贵的翻译流水线或大规模目标语言标注,即可取得与强大单语基线相当的性能表现。
数据集
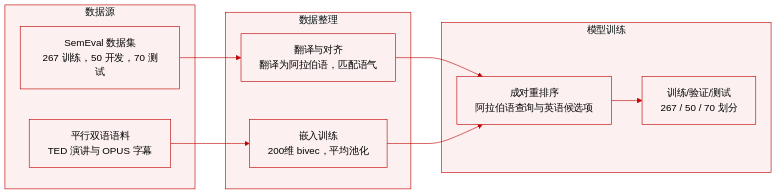
研究基于SemEval-2016 Task 3基准构建了一个跨语言问答相似性重排序数据集。通过将原始英文问题专业翻译为阿拉伯文,并使用这些阿拉伯文查询对英文候选问题进行排序,模拟了多语言检索场景。
• 数据集构成与来源: 核心数据集源自SemEval-2016 Task 3,并额外补充了一组未标注的英文问题。为进行双语表示学习,研究从TED演讲文稿和OPUS电影字幕中提取平行的阿拉伯文-英文双语文本,选用这些对话语料以紧密贴合社区问答论坛的非正式语体风格。
• 子集划分: 基准测试包含267个训练问题、50个开发集问题和70个测试问题。每个输入问题与10个通过信息检索(IR)获取的候选问题配对,每个划分分别产生2,670、500和700个候选项。补充的未标注集增加了221个英文问题及1,863个对应候选项,全部翻译为阿拉伯文以扩展模型的训练覆盖范围。
• 数据处理与表示: 问题级表示通过计算问题内所有token的词向量平均值得到。研究使用bivec框架训练200维的阿拉伯文-英文跨语言词向量,采用大小为5的上下文窗口并迭代5个epoch。从平行语料中提取双语词典,以锚定共享的词向量空间。
• 模型使用与训练设置: 数据结构化用于成对重排序,模型在此过程中将阿拉伯文输入问题与其英文候选项进行比较。平均化的跨语言词向量支持跨语言的直接语义比较,使系统能够在训练和评估阶段根据英文候选项与阿拉伯文查询的相似度进行排序。
方法
研究采用跨语言对抗神经网络(CLANN)框架来解决社区问答中的跨语言问答相似性重排序问题。该模型旨在利用源语言的标注数据和仅目标语言的未标注数据,将基于源语言(英文)训练的模型适配至目标语言(阿拉伯文)。架构输入为一对问题 (q,q′),其中 q 为目标语言(阿拉伯文)的新问题,q′ 为源语言(英文)中检索到的问题。两个问题首先通过预训练词向量映射为固定长度向量 zq 和 zq′,这些词向量可源自单语或跨语言嵌入模型。
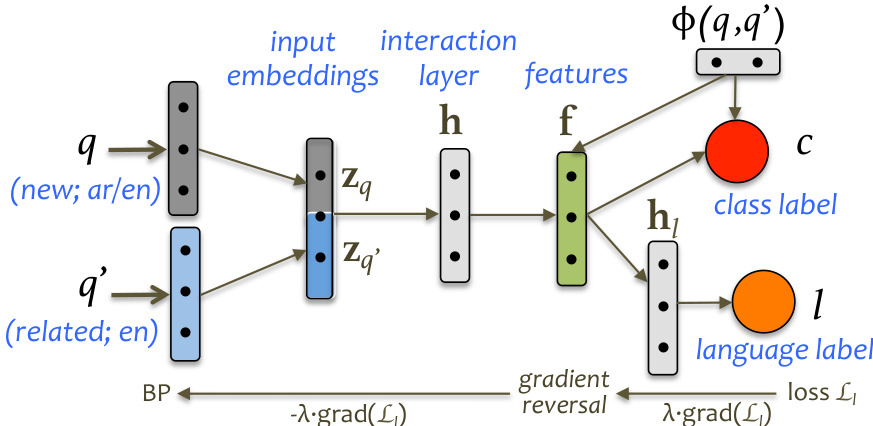
参见框架示意图。输入词向量经过一个共享交互层,该层由两个非线性隐藏层构成。第一个隐藏层计算 h=g(U[zq;zq′]),其中 U 为权重矩阵,g 为ReLU激活函数。第二个隐藏层计算 f=g(V[h;ϕ(q,q′)]),其中 V 为权重矩阵,ϕ(q,q′) 表示一组编码两个问题间相似度及任务特定属性的成对特征。这些成对特征与第一隐藏层的表示进行拼接,并直接输入至输出层。
输出层计算Sigmoid得分 c^θ=sigmoid(wT[f;ϕ(q,q′)]),用于估计类别标签 c(1表示相似,0表示不相似)的后验概率 p(c=1∣q,q′,θ)。模型通过最小化真实标签的负对数似然进行训练,损失函数为 Lc(θ)=−clogc^θ−(1−c)log(1−c^θ)。
为实现跨语言不变表示,框架引入了一个语言判别器网络,以内部表示 f 为输入,尝试对输入问题 q 的语言(英文或阿拉伯文)进行分类。该判别器通过Sigmoid函数计算语言标签 l,即 l^ω=sigmoid(wlThl),其中 hl=g(Ulf)。其损失函数 Ll(ω)=−llogl^ω−(1−l)log(1−l^ω) 用于训练判别器以区分源语言与目标语言。
整体训练目标结合了分类损失与语言判别损失:L(θ,ω)=∑nLcn(θ)−λ[∑nLln(ω)+∑n=N+1MLln(ω)]。模型通过极小极大优化进行训练,共享参数 {U,V,w} 被优化以最小化组合损失,而判别器参数 {Ul,wl} 被优化以最大化该损失。该过程通过梯度反转实现,语言损失 Ll(ω) 的反向传播梯度在传递至共享层时被反转,从而使任务分类器学习到对语言判别器具有对抗性的表示。训练过程采用随机梯度下降法,并为超参数 λ 设置动态权重调度以平衡两个损失分量。
实验
实验通过对比跨语言对抗网络与标准前向传播基线,在英阿和阿英两个语言方向上评估跨语言问答相似性框架。实验设置验证了对抗适配在两种场景下的有效性:仅使用未标注目标数据的无监督场景,以及补充部分标注目标样本的半监督场景。结果表明,即使减少源数据,对抗训练的性能也持续优于基线。此外,引入有限的标注目标样本成功将性能恢复至与全监督训练相当的水平,证明了该框架在跨语言应用中的鲁棒性与适应性。
研究在两个语言方向的无监督与半监督设置下,对比了跨语言对抗网络(CLANN)与前馈神经网络(FNN)的性能。结果显示,CLANN持续优于FNN,半监督训练在无监督适配的基础上进一步提升性能,使结果接近全标注数据训练的表现。CLANN在跨语言方向的无监督与半监督设置下均优于FNN。使用目标语言标注数据进行半监督训练,性能优于无监督适配。半监督训练带来的性能提升稳定且显著,接近全标注数据模型的表现。
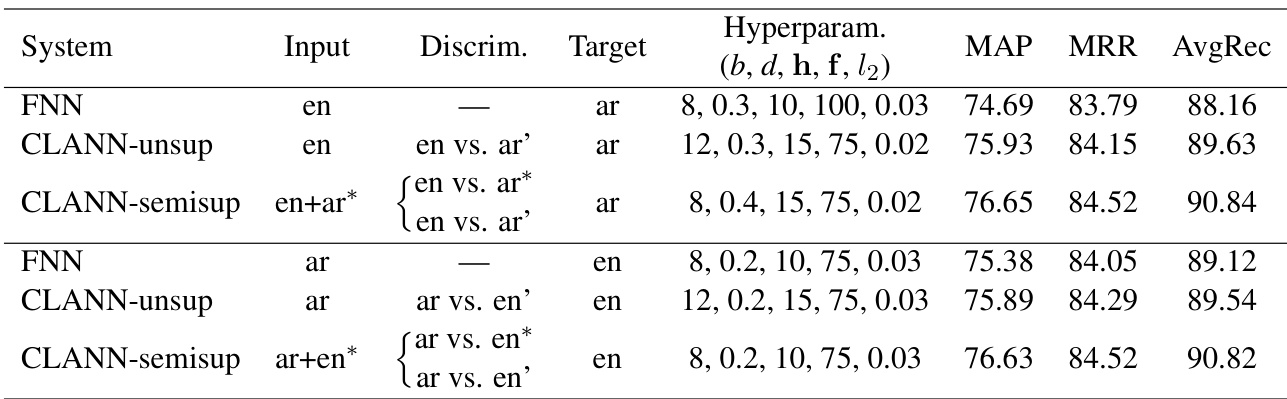
研究在两个语言方向的无监督与半监督设置下,对比了CLANN与前馈神经网络(FNN)的性能。结果表明,CLANN在所有评估指标上均持续优于FNN,且半监督训练相较于无监督适配进一步提升了性能。CLANN在跨语言方向及各项评估指标上均表现更佳。使用目标语言标注数据进行半监督训练,性能优于无监督适配。该对抗框架在跨语言设置中有效利用了标注与未标注数据。

研究展示了跨语言适配结果,对比CLANN模型与基线FNN,表明采用对抗适配可提升性能。结果证明,CLANN在两个语言方向的多项评估指标上均优于基线,在无监督与半监督设置下均取得稳定增益。在跨语言适配任务中,CLANN性能高于基线FNN。该模型在跨语言方向的评估指标上表现出一致的改进。相较于非对抗方法,对抗适配为性能带来显著提升。
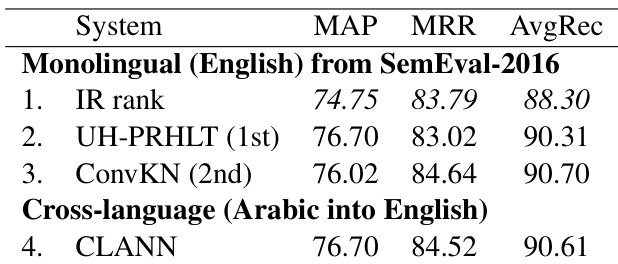
实验在两个语言方向的无监督与半监督设置下,评估了跨语言对抗网络与标准前向传播基线的性能。结果验证了相较于非对抗方法,对抗适配显著增强了跨语言迁移能力,模型性能持续优于基线。引入有限的目标语言标签进一步改善了适配效果,表明半监督训练能有效缩小无监督方法与全监督模型之间的性能差距。总体而言,该框架成功利用了标注与未标注数据,实现了稳健的跨语言泛化能力。